



前言
2025年6月,Shopify CEO Tobi Lütke 和 AI 大神 Andrej Karpathy 在 X 上提出了一个新概念——上下文工程。Karpathy 将其定义为"一门微妙的艺术与科学,旨在填入恰到好处的信息,为下一步推理做准备。"
然而,这个新概念与提示词工程有什么不同?为什么它会和 RAG、MCP 等技术扯上关系?过往的回答大多从技术角度出发,试图拆解上下文都包括什么,如何让它能够发挥最好的效果。
10月30日,上海交通大学和 GAIR 实验室发表了论文《上下文工程 2.0:上下文工程的上下文》,用一种更全面的视角定义了这个新兴学科。它不再把人机交互视为技巧,而是回归到了交流动力学的基础逻辑。

本文将以这篇论文为基础,系统性地回答三个核心问题:上下文工程到底是什么?它的基础构件是什么?未来会如何发展?
01
上下文工程是什么?
一门关于熵减的古老学科
要理解上下文工程,必须先回答:为什么人与机器的交流如此困难?
论文认为,这是因为人类与机器之间,存在一道认知鸿沟。
人类的交流是高熵的,他们的表达无序、混乱、充满隐含信息。当我对同事说"帮我搞定那个报告",他需要记忆中的"那个报告"指什么、从我的语气判断紧急程度、理解"辛苦"背后的社交暗示。这些都是海量的、模糊的、非结构化的上下文。
而机器是低熵生物,它无法接受足够多的上下文,只能理解明确的、毫不含糊的指令。
为了弥合这道鸿沟,人类必须将"高熵"意图转化为机器可理解的"低熵"指令。其手段,就是建立更丰富有效的上下文。正如马克思所说,人的本质是社会关系的总和。想要让AI更理解我们,就得让它理解人身处的一切情景。
这就是上下文工程的本质,通过更好的上下文,达成系统性的熵减过程。
在这个系统中,最重要的是实体,即人、应用、环境。上下文,就是描述实体状态的所有信息 。
上下文工程则是设计和优化上下文的收集、管理、使用, 以提升机器理解和任务表现的努力。
从这个意义上讲,上下文工程根本不是新概念。在AI之前,它已经发展了20多年,而现在,我们已经在上下文工程 2.0 时代了。
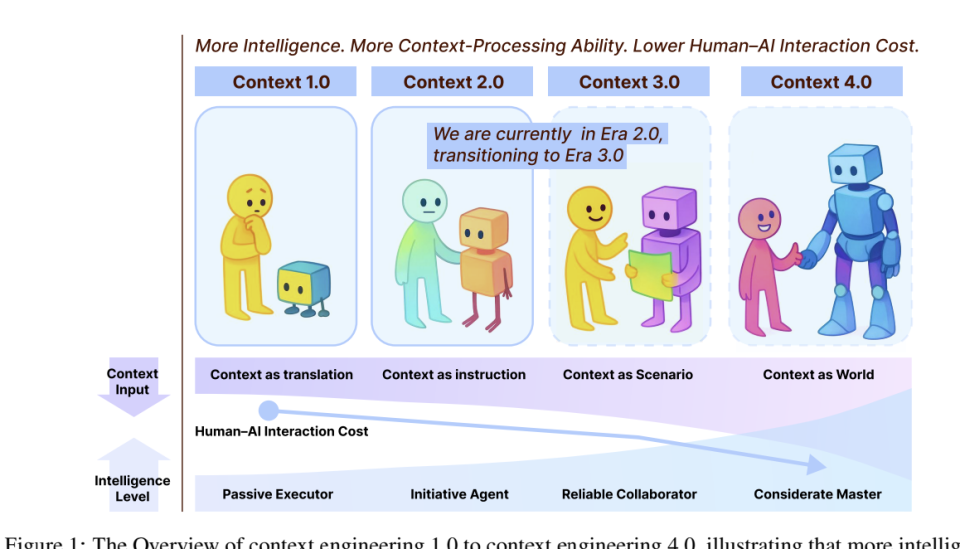
1.0时代 (1990s-2020):上下文即翻译
从计算机出现后,我们就开始探索人机理解的逻辑。操作系统的UI就是最古老、最成功的上下文工程实践。
**在那个时代,上下文工程的核心是翻译,即把人的自然语言意图,翻译成机器可理解的语言。**工程师通过设计图形界面(GUI),用鼠标操作和结构化界面将高熵意图"工程化"为低熵交互流程。编程语言也是如此,它把自然语言框架化成规范指令。
但这个过程其实很违反人类的自然表达天性。比如学编程,你不光要学语言,还要学习一种规范化的思维。
2.0 时代 (2020-至今):上下文即指令
2020年,随着 GPT-3 发布,我们迎来了一个全新时代。用户可以直接用自然语言和机器对话。
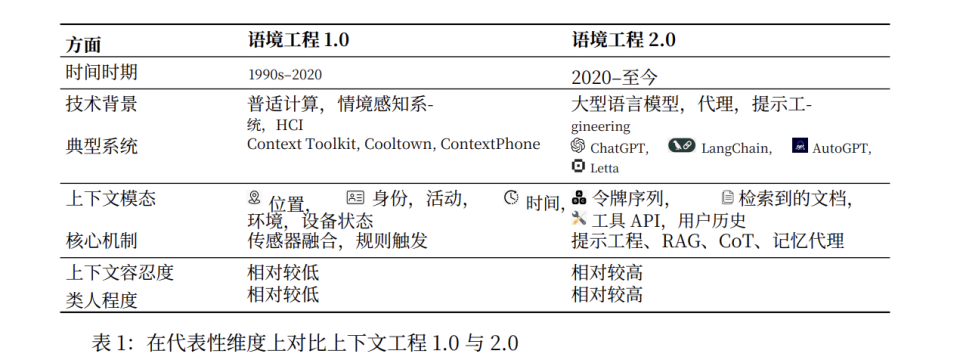
翻译的中间层消失了,设计师和程序员的熵减工作也随之消失。
但普通用户发现,虽然和 AI 说话不需要翻译了,它依然理解不了话语背后的信息。
熵减的需求并没有消失,只是转移到了用户身上。他们必须学会精确表达意图、构建有效 prompt、调试输出。
这就是提示词工程爆发的原因,人们在试图重新发明一种结构化的自然语言来减少沟通中的障碍。
但除了规范自己的表达,我们也可以从模型本身下手,给它提供更好的脚手架和系统,让它更好地理解我们的意图。
这就是上下文工程诞生的背景。
02
AI与人沟通,为什么还是有理解差距?
既然上下文工程是为了解决目前人与AI沟通的Gap,那它做不到和我们人类一样可以高熵交流的核心原因都有什么呢?
论文通过与人类沟通做对比,总结了八大AI的缺陷,我们可以把它归结成四种。正是因为这些缺陷存在,它理解不了我们的高熵交流,造成了Gap。
**首先,AI的感官是残缺的。**人类沟通时会接收大量文字外信息,而 AI 只能获得用户明确的输入。它看不见我们所处的环境,上下文收集存在先天缺陷。
第二是AI的理解能力有限。与人类相比,AI理解和整合上下文的能力很有限。就算它感官不残缺,即使把所有信息都喂给 AI,它也不一定理解其中关系。当前模型难以处理复杂逻辑和图像中的关系信息。
**第三个最要命,就是记忆的缺失。Transformer 架构存在长上下文性能瓶颈,导致模型既没有长期记忆系统,也难以捕捉长距离依赖关系。**AI记不住过去的对话,就不可能像人一样建立背景共识。正是这些"我们都知道的过去",让人类说话如此省力。而当前试图去存储记忆的方法,如RAG等,仍然效率较低。
第四是相对于人来讲,AI的注意力是涣散的。这被论文称为“上下文选择困难”。就算我们解决了上一个问题,给 AI 外挂了长期记忆,比如RAG,理论上讲就是可以存储所有内容。但面对海量信息时,AI 并不知道该看哪里。
针对这些缺点,过去提示词工程通过添加"前情提要"修补记忆缺失,通过手动精炼信息、规范化表达减少理解和注意力负担。它就是上一代针对模型缺陷的全面补丁。
但这个过程太耗费力气了。
因此一个好的上下文工程,就是尽可能搭建脚手架,让模型借助脚手架,解决当下能力不足的问题。让AI真的可以成为人的数字存在(Digital Presence),人们可通过上下文"数字永生",让你的对话、决策、交互轨迹可以持续演化。
但这个过程太耗费人力。一个好的上下文工程,应该搭建脚手架,让模型借助系统解决当前能力不足的问题。
03
上下文工程,AI时代的泥瓦匠
为了解决模型当前问题,论文提出了一个包含收集、管理、使用三个阶段的完整上下文工程体系。这张技术地图详细说明了我们为弥补 LLM 缺陷而必须搭建的庞大脚手架系统。
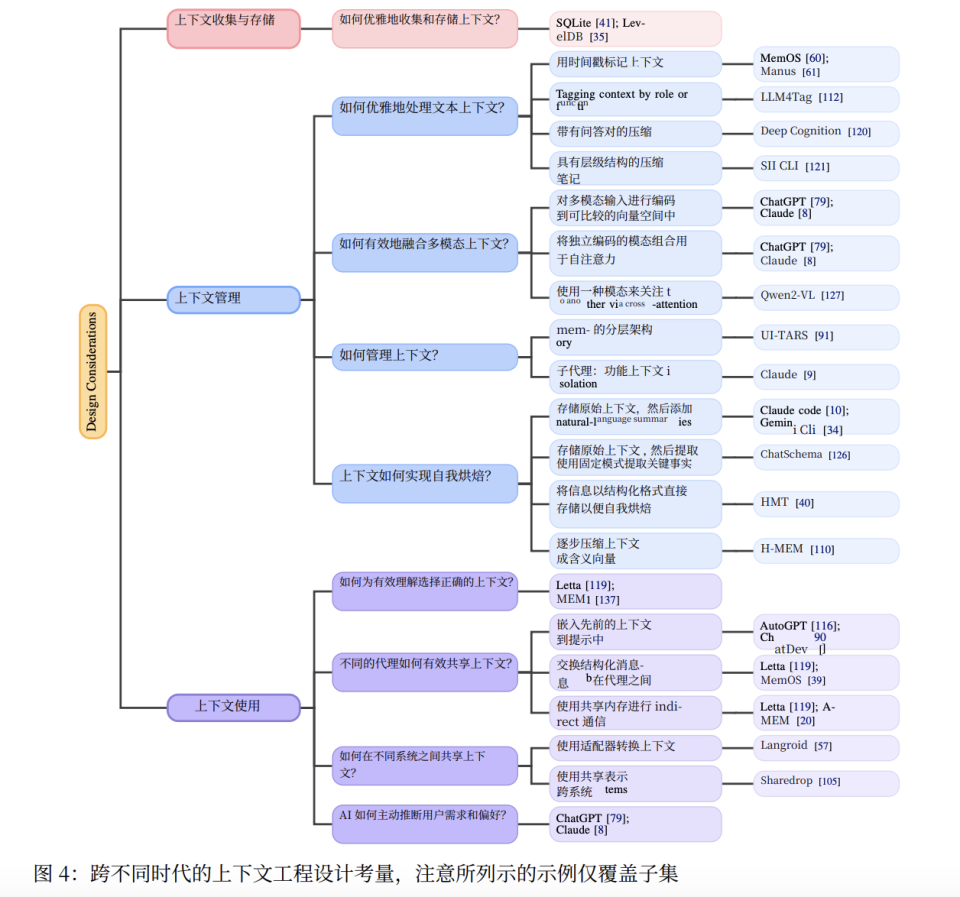
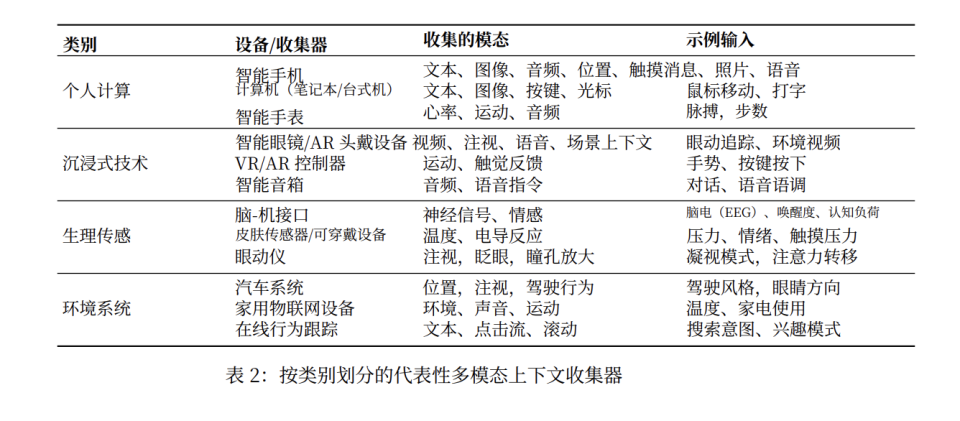
构件一:上下文收集与记忆系统
这一构件主要修复 AI 的"感官残缺"与"记忆缺失"。
上下文收集方面,我们必须超越简单的文本输入,转向多模态、分布式的收集。
多模态融合,就是将文本、图像、音频通过各自编码器映射到共享向量空间,让模型真正理解多模态意涵。
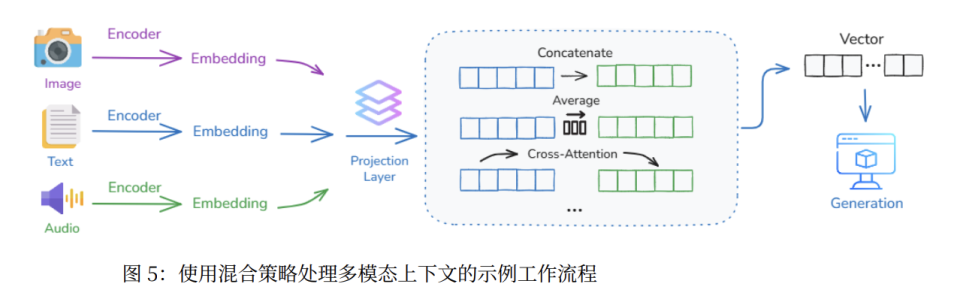
而分布式收集,则通过智能手机、可穿戴设备、IoT 传感器,甚至脑机接口,主动捕捉用户无法用文字清楚表达的环境上下文和高熵信息。
存储系统则是给记忆搭建脚手架。为了解决 Transformer 带来的记忆缺失,我们需要构建分层内存架构,让模型形成类人的记忆结构。
它类似操作系统的内存管理:短期记忆是 AI 的内存,即有限的上下文窗口;长期记忆是 AI 的硬盘,用于持久化存储高重要性上下文的外部数据库。
两层之间,需要建立类似睡眠的记忆转移机制。系统处理过往内容,将重要的短期记忆转存为长期记忆。
构件二:上下文管理
这主要解决 AI 理解能力有限,难以处理复杂逻辑和关系信息的问题。
核心是上下文抽象,论文称之为"自我烘焙"(Self-Baking)。既然 AI 看不懂原始的、高熵的上下文,这个脚手架就充当预处理器,主动将上下文消化并烘焙成 AI 能理解的低熵结构。
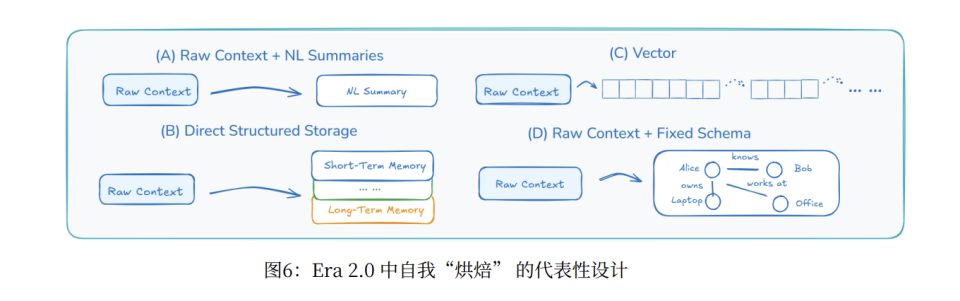
这并非简单摘要,而是区分记忆存储和学习的关键。没有它,智能体只是在回忆;有了它,智能体才是在积累知识。
目前流行实现方法从简单到高级分为三种:
- 自然语言摘要:让 AI 自己摘要重要信息,但它是纯文本,缺少结构,难以深度推理。
- 模式化提取:从原始上下文提取关键事实(人、地点、事件),按固定模式存入知识图谱。AI 不再需要理解复杂关系,只需查询已准备好的结构化关系图。
- 在线蒸馏:如 Thinking Machine 提出的方法,将上下文渐进式压缩为向量,转化成模型自己的知识。
构件三:上下文使用
这个构件主要解决 AI 注意力涣散问题,规范收集和管理后的上下文如何进行协作和推理。
论文提出的解决方法也很直接,即构建高效的上下文选择机制,先过滤注意力。
当前,模型在 RAG 中搜索记忆时过于依赖语义相关性(向量搜索),会搜出大量信息,导致上下文过载,理解能力大幅下降。
因此,我们需要一个更高效的搜索机制。它需要满足以下几个特质:
- 理解逻辑依赖。让AI使用RAG搜索时用逻辑关系,而不是简单地问“什么信息在语义上最像?”
- **平衡新近度与频率。**优先关注“最近使用过”或“经常使用”的信息
- 最终,模型能够达到主动需求推断的水平。系统不再被动地等待你提问,而是基于上下文,对你隐藏目标做分析,主动推断你下一步可能需要什么信息,并提前为你准备好。
至此,这个上下文工程框架通过收集、管理、使用上下文,弥补了 AI 在"感官"、“理解”、"记忆"和"注意力"上的四大缺陷,形成了一整套关于上下文的闭环工作流程。
在这个流程下,我们可以把提示词工程的重担转移回模型自身,让它通过系统尽可能好地理解我们。
04
上下文 3.0 & 4.0
最好的上下文工程,就是没有上下文
论文的"蓝图"并未止步于此。随着基础模型认知能力不断提升,我们将迎来熵减努力主体的第二次、乃至第三次转移。
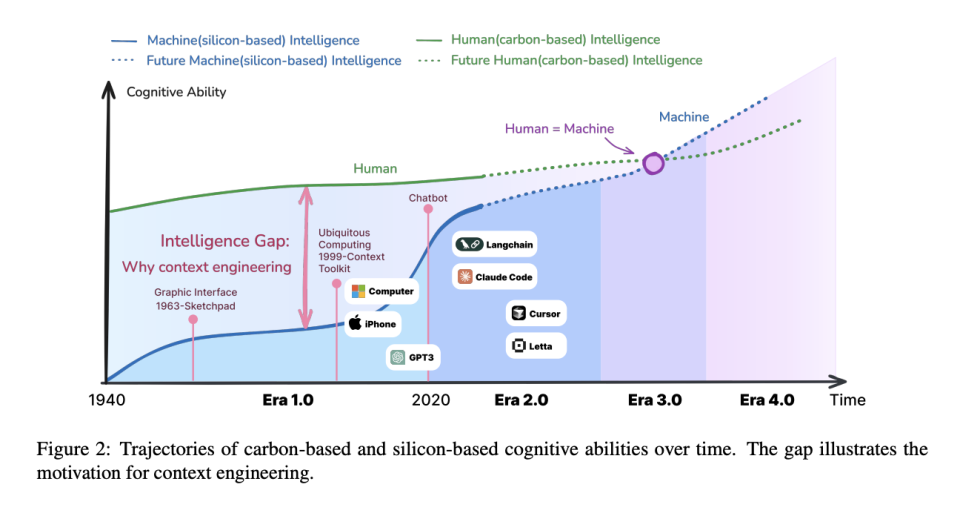
上下文工程 3.0 时代,将在当机器智能达到人类水平,能处理情绪、暗示等复杂上下文模态时到来。
这时理解瓶颈将被打破,记忆处理将成熟,AI 将主动理解我们的"场景"并与我们协作。但在这个时代,长期记忆问题仍未解决,模型主动性依然有限。
**上下文工程 4.0 时代,**则将在机器智能达到"超人智能"时到来。此时,人机交流的熵被彻底消除。你什么都不用说,它都能预测你想干什么并执行安排。
在这个时代,上下文工程消失了。
或者用更好的方法讲,它所搭建的脚手架最终融入了核心架构。
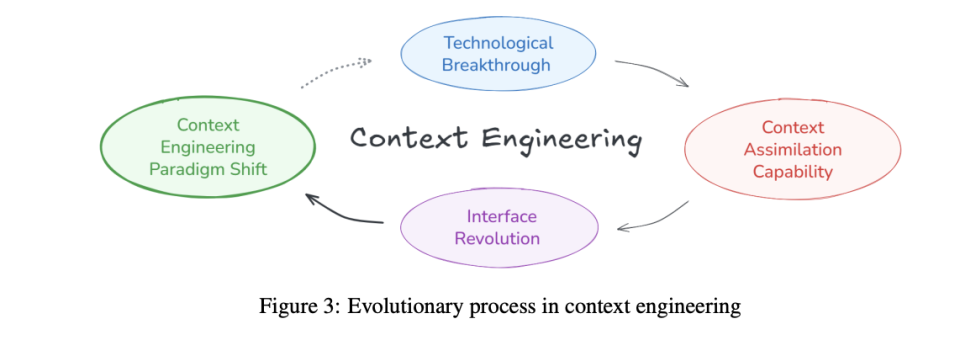
**这在技术发展的历史中,几乎是常态。**最典型的案例就是注意力机制本身。这个机制最初是作为编码器-解码器 RNN 的"外挂补丁"出现的,用来解决序列翻译中的瓶颈问题。但到了 2017 年,Transformer 架构彻底将注意力机制内化为核心,只是移除了RNN部分以实现并行处理。曾经的脚手架,变成了今天所有大语言模型的基础架构。
同样的故事,在上下文工程领域其实也在进行中。
2025年3月,Sam Altman 宣布将在所有OpenAI产品中添加 MCP 支持,包括 ChatGPT 桌面应用。这标志着工具使用这个能力,不再是简单的"外挂",而是正在成为 Agent 架构的固定组成部分。
从注意力机制到 MCP,我们看到了同一个模式:当某种脚手架被证明足够有效且通用时,它就会从外部工具演变为标准协议,最终融入模型或 Agent 的核心架构。
因此,即使我们知道上下文工程有一天会消失,但当下,它依然是通往 AGI 路上的必经之路。
不是因为它能让模型"更聪明",那是算法和算力的任务。而是因为它能让模型"更好用。
正如 Transformer 不需要等到模型完全理解语言才出现,MCP 也不需要等到模型拥有完美记忆才部署。它们的存在,让我们可以用今天的模型,实现明天才能达到的应用体验。
这些脚手架,最终会以某种形式,也许是协议、也许是架构、也许是全新的神经网络层,融入未来的模型。它们不会消失,只会invisible。
上下文工程的终极形态,就是让自己成为不需要被谈论的基础设施。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









