



学习如何针对特定用例微调语言模型
在本文中,我将讨论如何微调VLM(视觉大语言模型,通常称为VLLMs)如Qwen 2.5 VL 7B。我将向您介绍一个手写数字数据集,Qwen 2.5 VL的基线版本在处理这个数据集时存在困难。然后我们将检查这个数据集,对其进行标注,并使用它创建一个专门用于提取手写文本的微调版Qwen 2.5 VL。
概述
本文的主要目标是在数据集上微调VLM,这是当今世界机器学习领域的重要技术,语言模型正在革命性地改变数据科学家和ML工程师的工作和成就方式。我将讨论以下主题:
- • 动机和目标:为什么使用VLM进行文本提取
- • VLM的优势
- • 数据集
- • 标注和微调
- • SFT技术细节
- • 结果和图表
注意:本文是作为在Findable公司完成的工作的一部分编写的。我们在这项工作中没有获得经济收益。这样做是为了突出现代视觉语言模型的技术能力,并数字化和分享一个有价值的手写物候数据集,这可能对气候研究产生重大影响。此外,本文的题目在Netlight举办的Data & Draft活动的演讲中有所涉及。
您可以查看本文使用的所有代码在我们的GitHub仓库中,以及所有数据都在HuggingFace上可用。如果您特别对从挪威提取的物候数据感兴趣,包括与数据对应的地理坐标,信息直接可在this Excel表格中获取。
动机和目标
本文的目标是向您展示如何微调VLM(如Qwen)在特定任务上实现优化性能。我们在这里处理的任务是从一系列图像中提取手写文本。本文的工作基于一个挪威物候数据集,您可以在this GitHub仓库的README中了解更多相关信息。关键是这些图像中包含的信息非常有价值,例如,可用于进行气候研究。这个话题也有明确的科学兴趣,例如this分析植物开花长期变化的文章,或东部宾夕法尼亚物候项目。
请注意,提取的数据是善意呈现的,我对数据所暗示的内容不做任何声明。本文的主要目标是向您展示如何提取这些数据,并为您呈现提取的数据,用于科学研究。
在本文中,我们将使用Qwen 2.5 VL从这类图像中提取文本。这些单元格是从如特色图像中所示的表格中提取的,使用图像处理技术,这些技术将在单独的文章中介绍。图片由作者提供。
我在本文中创建的结果模型可用于从所有图像中提取文本。然后这些数据可以转换为表格,您可以将信息绘制成如下图所示的图像:
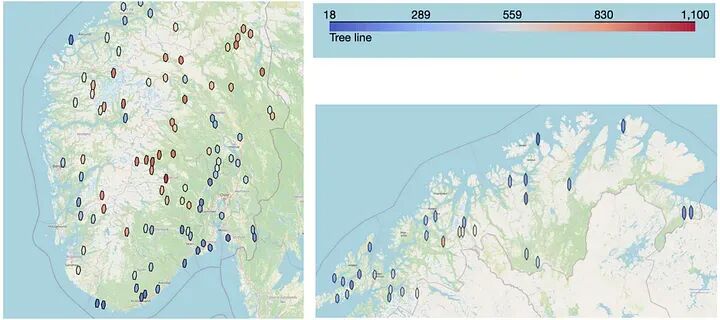
此图显示了从图像中提取的树线数据,绘制在挪威地图上。颜色较冷的六边形意味着较低的树线,正如预期的那样,这种现象在靠近海洋和越往北走越常见。较暖的颜色代表较高的树线,这预期会在越往内陆走的地方发生。图片由作者提供,使用Uber的H3技术制作。
如果您只对查看本研究中提取的数据感兴趣,可以在this parquet文件中查看。
为什么我们需要使用VLM
当查看图像时,您可能认为我们应该将传统OCR应用到这个问题上。OCR是从图像中提取文本的科学,在过去几年中,它一直被Tesseract、DocTR和EasyOCR等引擎主导。
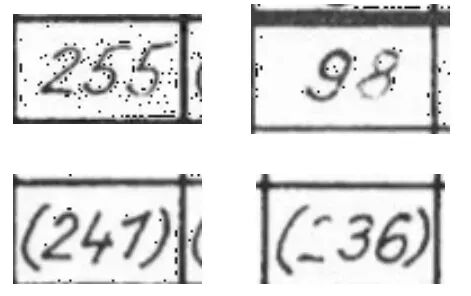
然而,这些模型经常被现代大语言模型超越,特别是那些结合视觉的模型(通常称为VLM或VLLMs)——下图突出了为什么您想要使用VLM而不是传统OCR引擎。第一列显示了我们数据集中的示例图像,另外两列比较了EasyOCR与我们在本文中训练的微调Qwen模型。
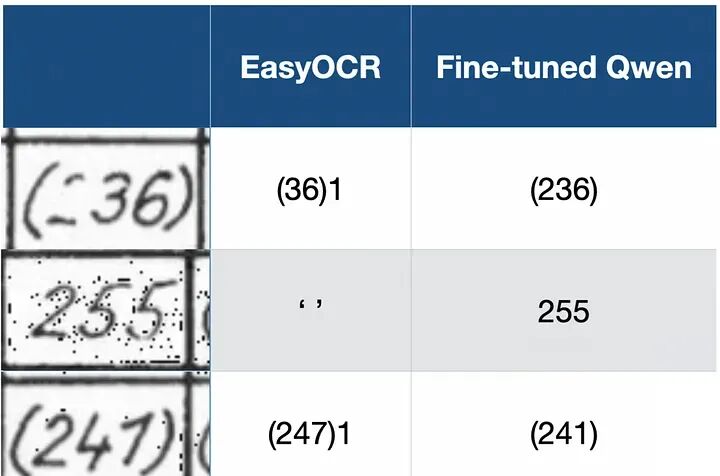
此图突出了为什么您想使用VLM(如Qwen2.5 VL)而不是传统OCR引擎(如EasyOCR)。第一列显示我们想要从中提取文本的图像,另外两列显示使用EasyOCR和微调Qwen模型提取的文本。在第一张图像中,您会注意到两个问题。首先,EasyOCR没有检测到书写较淡的"2"。其次,EasyOCR还将单元格边框误认为是"1",这是另一个关键错误。在第二张图像中,您可以看到图像中有很多点(这是我们执行的图像处理的结果),这使得EasyOCR无法从图像中提取文本。在最后一张图像中,EasyOCR将"1"误认为"7",再次犯下认为单元格边框是数字"1"的错误。
这突出了使用VLM而不是传统OCR引擎从图像中提取文本的主要原因:VLM在从图像中提取文本时通常优于传统OCR引擎。
VLM的优势
从图像中提取文本时使用VLM有几个优势。在上一节中,您看到VLM的输出质量如何超过传统OCR引擎的输出质量。另一个优势是您可以向VLM提供如何行为的指令,这是传统OCR引擎无法提供的。
因此,VLM的两个主要优势是:
-
- VLM擅长OCR(特别是手写)
-
- 您可以提供指令
VLM擅长OCR,因为这是这些模型训练过程的一部分。例如,这在Qwen 2.5 VL技术报告第2.2.1节预训练数据中提到,他们将OCR数据集列为预训练数据的一部分。
手写
提取手写文本在过去一直非常困难,至今仍是一个挑战。原因是手写是非标准化的。
我所说的非标准化是指字符在不同的人看来会有很大差异。作为标准化字符的例子,如果您在计算机上写入一个字符,无论在不同的计算机上还是不同的人书写,它都会看起来非常相似。例如,计算机字符"a"无论在什么计算机上书写看起来都非常相似。这使得OCR引擎更容易识别该字符,因为它从图像中提取的字符很可能看起来与它在训练集中遇到的字符非常相似。
然而,手写文本则相反。手写在人与人之间差异很大,这就是为什么您有时很难阅读其他人的笔迹。OCR引擎也有这个确切的问题。如果字符差异很大,它在训练集中遇到特定字符变体的可能性就较低,因此从图像中提取正确字符变得更加困难。
例如,您可以看下面的图像。想象只看着图像中的"1"(所以遮盖住"7")。现在看图像,“1"看起来很像"7”。当然,您能够分离这两个字符,因为您可以在上下文中看到它们,并批判性地思考,如果"7"看起来像那样(带有水平线),图像中的前两个字符必须是"1"。
然而,传统OCR引擎没有这种能力。它们不看整个图像,批判性地思考一个字符的外观,并使用它来确定其他字符。它们必须在查看孤立数字时简单猜测它是哪个字符。

这是一张突出了将"1"与"7"分离挑战的图像。将所有三个数字放在彼此的上下文中,您可以很容易地看到前两个数字是"1",而最后一个数字是"7"。但是,如果您遮盖住最后一个数字,只看前两个数字,您会注意到这些数字很可能被解释为"7"。图片由作者提供
如何将数字"1"与"7"分离,与下一节很好地联系在一起,关于在提取文本时向VLM提供指令。
我还想补充一点,一些OCR引擎,如TrOCR,专门用于提取手写文本。然而,根据经验,这样的模型在性能上无法与像Qwen 2.5 VL这样的最先进VLM相提并论。

提供指令
使用VLM从图像中提取文本的另一个重要优势是您可以向模型提供指令。这对传统OCR引擎来说自然是不可能的,因为它们提取图像中的所有文本。它们只能输入图像,而不能为从图像中提取文本提供单独的文本指令。当我们想使用Qwen 2.5 VL提取文本时,我们提供一个系统提示,如下所示。
SYSTEM_PROMPT = """Below is an instruction that describes a task, write a response that appropriately completes the request.You are an expert at reading handwritten table entries. I will give you a snippet of a table and you willread the text in the snippet and return the text as a string.The texts can consist of the following:1) A number only, the number can have from 1 to 3 digits.2) A number surrounded by ordinary parenthesis.3) A number surrounded by sqaure brackets.5) The letter 'e', 's' or 'k'6) The percent sign '%'7) No text at all (blank image).Instructions:**General Rules**: - Return the text as a string. - If the snippet contains no text, return: "unknown". - In order to separate the digit 1 from the digit 7, know that the digit 7 always will have a horizontal stroke appearing in the middle of the digit. If there is no such horizontal stroke, the digit is a 1 even if it might look like a 7. - Beware that the text will often be surrounded by a black border, do not confuse this with the text. In particular it is easy to confuse the digit 1 with parts of the border. Borders should be ignored. - Ignore anything OUTSIDE the border. - Do not use any code formatting, backticks, or markdown in your response. Just output the raw text. - Respond **ONLY** with the string. Do not provide explanations or reasoning."""
系统提示为Qwen如何提取文本设定了框架,这给了Qwen相比传统OCR引擎的主要优势。
给它优势的主要有两点:
-
- 我们可以告诉Qwen在图像中期望看到哪些字符
-
- 我们可以告诉Qwen字符是什么样子(对手写文本特别重要)
您可以在1) -> 7)点中看到第一点的处理,我们告知它只能看到1-3位数字、它可以看到哪些数字和字母等等。这是一个重要优势,因为Qwen知道如果它检测到这个范围之外的字符,它很可能是误解了图像,或面临特定挑战。它可以更好地预测它认为图像中的字符。
第二点与我之前提到的分离"1"和"7"的问题特别相关,它们看起来相当相似。对我们来说幸运的是,这个数据集的作者在写"1"和"7"时是一致的。"1"总是斜着写的,“7"总是包含水平线,这清楚地分离了"7"和"1”,至少从人类看图像的角度来看。
然而,向模型提供如此详细的提示和规范只有在您真正理解所处理的数据集及其挑战时才是可能的。这就是为什么在处理这样的机器学习问题时,您总是必须花费时间手动检查数据。在下一节中,我将讨论我们正在处理的数据集。
数据集
手动检查数据可能是机器学习中任何活动价值与声望比最高的活动。
我以Greg Brockman(截至撰写本文时OpenAI的总裁)的引用开始这一节,突出了一个重要点。在他的推文中,他指的是数据标注和检查不是有声望的工作,但尽管如此,这是您在处理机器学习项目时花费时间的最重要任务之一。
在Findable,我开始担任数据标注员,然后继续管理Findable的标注团队,现在担任数据科学家。标注工作突出了手动检查和理解您正在处理的数据的重要性,并教会了我如何有效地做到这一点。Greg Brockman指的是这项工作没有声望,这通常是正确的,因为数据检查和标注可能是单调的。然而,当处理机器学习问题时,您应该总是花费相当多的时间检查您的数据集。这段时间将为您提供洞察力,例如,您可以使用这些洞察力来提供我在上一节中强调的详细系统提示。
我们正在处理的数据集包含大约82000张图像,如您在下面看到的。单元格的宽度从81到93像素不等,高度从48到57像素不等,这意味着我们正在处理非常小的图像。
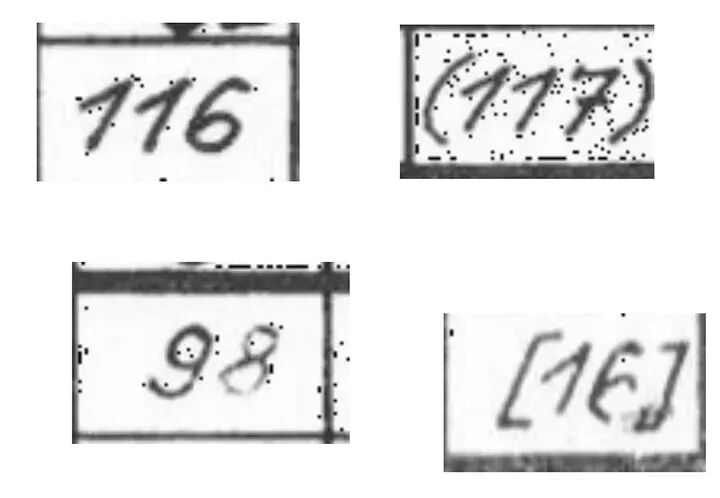
这些图像展示了数据集中存在的图像。图片由作者提供
在开始这个项目时,我首先花时间查看不同的图像以了解数据集中的变化。例如,我注意到:
-
- “1"看起来像"7”
-
- 在某些图像中有些淡的文本(例如,上面左下角图像中的"8"和右下角图像中的"6")
-
- 从人类的角度来看,所有图像都很好读,所以我们应该能够正确提取所有文本
然后我继续使用Qwen 2.5 VL 7B的基线版本来预测一些图像,并查看模型在哪些区域遇到困难。我立即注意到模型(毫不奇怪)在分离"1"和"7"时遇到问题。
在首先手动检查数据,然后使用模型预测一些图像以查看其困难之处的过程后,我记录了以下数据挑战:
-
- "1"和"7"看起来相似
-
- 某些图像背景中有点
-
- 单元格边界可能被误解为字符
-
- 括号和方括号有时会混淆
-
- 某些图像中的文本很淡
当我们微调模型从图像中提取文本时,我们必须解决这些挑战,这将在下一节中讨论。
标注和微调
在适当检查您的数据集之后,是时候进行标注和微调工作了。标注是为每个图像设置标签的过程,微调是使用这些标签来改善模型质量。
主要目标在执行标注时是高效地创建数据集。这意味着快速生成大量标签并确保标签的高质量。为了实现快速创建高质量数据集的目标,我将过程分为三个主要步骤:
-
- 预测
-
- 审查和纠正模型错误
-
- 重新训练
您应该注意,当您已经有一个在执行任务方面相当好的模型时,这个过程效果很好。例如,在这个问题中,Qwen在从图像中提取文本方面已经相当好,只在5-10%的情况下出错。如果您有模型完全陌生的任务,这个过程效果不会那么好。
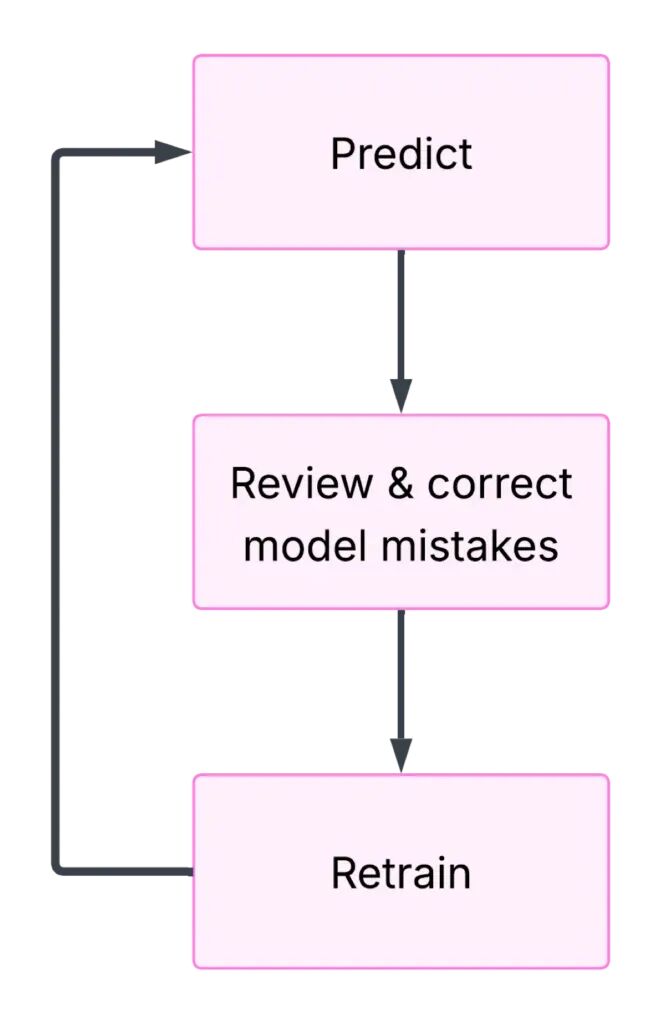
此图突出了我快速创建标注数据集和微调Qwen的三步过程。步骤1使用基线模型对几百个样本进行预测。然后我检查模型预测并纠正错误。之后,我在当前标注样本集上训练模型。继续,我使用这个微调模型对新的几百个样本进行预测,审查和纠正错误,并重新训练。我继续这个过程直到模型性能开始收敛。这种创建数据集的过程比例如查看每张图像并写下图像中的文本以创建标注数据集要快得多。图片由作者提供。
步骤1:预测
第一步是使用基线模型对几百张图像进行预测(提取文本)。您预测的图像的具体数量并不重要,但您应该尝试在收集足够标签以便训练运行足以改善模型(步骤3)和考虑训练模型所需的开销之间取得平衡。
步骤2:审查和纠正模型错误
在对几百个样本进行预测后,是时候审查和纠正模型错误了。您应该设置您的环境以轻松显示图像和标签并修复错误。在下面的图像中,您可以看到我审查和纠正错误的设置。在左侧,我有一个Jupyter笔记本,我可以运行单元格来显示以下五个样本和标签对应的行。在右侧,所有我的标签都列在对应的行上。为了审查和纠正错误,我运行Jupyter笔记本单元格,确保右侧的标签与左侧的图像匹配,然后重新运行单元格以获得以下五张图像。我重复这个过程直到我查看了所有样本。
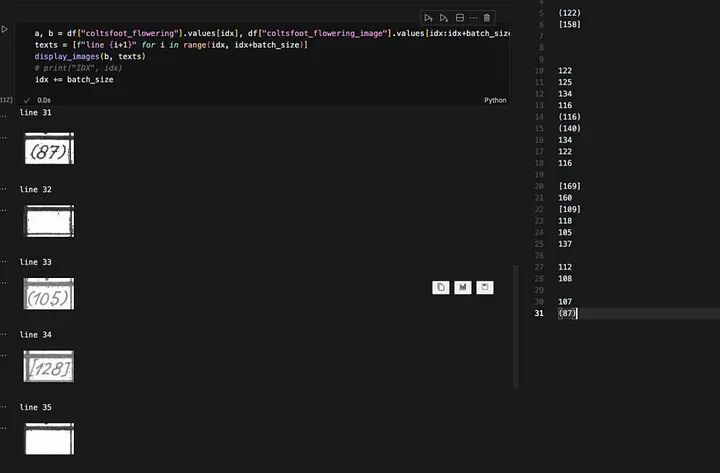
此图显示了我审查和纠正模型错误的环境。在左侧,我有一个Jupyter笔记本,我可以运行单元格来显示接下来的五张图像,以及每张图像标签对应的行。在右侧,我所有标签都在对应的行上。这个环境使查看所有模型预测并纠正任何错误变得容易。图片由作者提供。
步骤3:重新训练:
现在您有几百个正确的样本,是时候训练模型了。在我的情况下,我获取Qwen 2.5 VL 7B并将其调整到我当前的标签集。我使用Unsloth包进行微调,该包提供了这个关于微调Qwen的笔记本(笔记本是针对Qwen 2 VL的,但所有代码都是相同的,除了更改命名,如您在下面的代码中看到的)。您可以查看下一节以了解更多关于微调过程的细节。
训练创建模型的微调版本,我回到步骤1对新的几百个样本进行预测。我重复这个预测、纠正和训练的循环,直到我注意到模型性能收敛。
# 这是笔记本中的原始代码model, tokenizer = FastVisionModel.from_pretrained( "unsloth/Qwen2-VL-7B-Instruct", load_in_4bit = False, # 这最初设置为True,但如果您有处理能力,我建议将其设置为False use_gradient_checkpointing = "unsloth",)# 要训练Qwen 2.5 VL(而不是Qwen 2 VL),请确保您使用这个:model, tokenizer = FastVisionModel.from_pretrained( "unsloth/Qwen2.5-VL-7B-Instruct", load_in_4bit = False, use_gradient_checkpointing = "unsloth",)
为了确定我的模型表现如何,我还创建了一个测试集,我在这个测试集上测试每个微调模型。我从不在这组测试集上训练以确保无偏结果。这个测试集是我确定模型性能是否收敛的方式。
SFT技术细节
SFT代表监督微调,这是更新模型权重以在我们提供的数据集上表现更好的过程。我们在这里处理的问题很有趣,因为基线Qwen 2.5 VL模型在OCR方面已经相当好了。这与我们在Findable将VLM应用到的许多其他任务不同,在那里我们通常教VLM一个它基本上没有先前经验的全新任务。
当在新任务上微调VLM(如Qwen)时,一旦您开始训练,模型性能会迅速提高。然而,我们在这里处理的任务相当不同,因为我们只想稍微推动Qwen在我们的特定图像上在阅读手写方面更好一点。正如我提到的,模型的性能在这个数据集上大约90-95%准确(取决于我们测试的具体图像)。
只需稍微推动模型的要求使模型对调优过程参数超级敏感。为了确保我们正确推动模型,我们执行以下操作
- • 设置低学习率,只稍微更新权重
- • 设置低LoRA等级只更新模型权重的一小部分
- • 确保所有标签都是正确的(模型对少数标注错误超级敏感)
- • 平衡数据集(有很多空白图像,我们过滤掉一些)
- • 调优VLM的所有层
- • 执行超参数搜索
我将在一些要点上添加一些额外说明:
标签正确性
标签正确性至关重要。仅仅几个标签错误就会对模型性能产生不利影响。作为一个例子,当我正在微调我的模型时,我注意到模型开始混淆括号"( )“与方括号”[ ]"。这当然是一个重大错误,所以我开始调查为什么会发生这种情况。我的第一个直觉是这是由于我一些标签的问题(即,有些图像实际上是括号,但收到了带方括号的标签)。我开始查看我的标签,注意到在大约0.5%的标签中出现了这个错误。
然而,这帮助我做出了一个有趣的观察。我有一组大约1000个标签。99.5%的标签是正确的,而0.5%(5个标签!)是错误的。然而,在我微调我的模型后,它实际上在测试集上表现更差。这突出了仅仅几个错误标签就能损害您模型性能的事实。
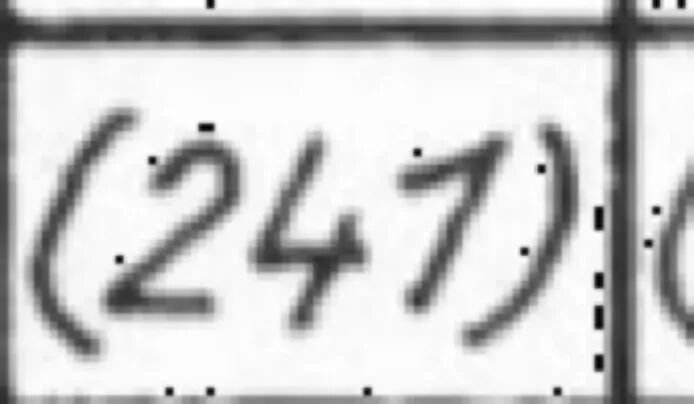
这是一个标签设置为方括号而您可以清楚看到图像包含括号的图像示例。图片由作者提供。
为什么如此少的错误会产生如此大的影响的原因是模型盲目信任您给它的标签。模型不看图像并思考_嗯,为什么当图像有括号时这是方括号?(就像您可能做的那样)。模型盲目信任标签并接受这个事实,即这个图像(这是括号)包含方括号。这确实会降低模型性能,因为您提供了不正确的信息,它现在使用这些信息来执行未来的预测。
数据平衡
微调的另一个细节是我平衡数据集以限制空白图像的数量。大约70%的单元格包含空白图像,我们希望避免在这些图像上花费太多微调时间(模型已经能够很好地忽略这些单元格)。因此,我确保我们微调的数据中最多30%包含空白图像。
选择要调优的层
下面的图像显示了VLM的一般架构:

此图显示了VLM的标准架构布局。图像通过ViT(视觉变换器)处理,从中提取视觉标记。然后这些标记通过VL(视觉语言)适配器传递,以确保图像标记与文本标记在相同的嵌入空间中。输入模型的文本简单地进行标记化。文本和图像标记然后都输入到解码器中,解码器产生输出文本。
微调VLM时要考虑的一个决定是您微调哪些层。理想情况下,您想要调优所有层(在下面的图像中标记为绿色),我在这问题上处理时也这样做了。但是,有时您会有计算约束,这使得调优所有层变得困难,您可能不需要调优所有层。这方面的一个例子是如果您有一个非常依赖图像的任务。例如,在Findable,我们对来自建筑师、土木工程师等的图纸进行分类。这自然是一个非常依赖图像的任务,这是一个示例,表明您可能只能调优模型的视觉层(ViT——视觉变换器和视觉语言适配器,有时称为投影仪)就足以满足需求。
这是建筑师图纸的一个示例。图纸来源于奥斯陆市,与Findable AS客户数据无关。通过访问奥斯陆市政府的saksinnsyn网站(英文案例访问)(https://innsyn.pbe.oslo.kommune.no/saksinnsyn/main.asp)找到图纸。搜索Camilla Collects vei(随机选择的地址)。然后按Søk i sak(案例中搜索)按钮。选择Saksnummer(案例编号)为202317562的案例,按带有tegninger的选项卡,并选择名为plan 8 etasje的图纸。在与奥斯陆市规划和建筑服务部门交谈后使用该图形,他们允许使用其网站上任何公开可用的图纸。图纸于2024.05.23访问
超参数搜索
我还进行了超参数搜索以找到微调模型的最佳参数集。然而,值得注意的是,超参数搜索并不总是可能的。一些大语言模型的训练过程可能需要几天时间,在这种情况下,执行广泛的超参数搜索不可行,因此您必须使用您的直觉来找到一组好的参数。
然而,对于这个提取手写文本的问题,我有权访问A100 80 GB GPU。图像相当小(每个方向少于100px),我正在处理7B模型。这使得训练需要10-20分钟,这使得过夜超参数搜索可行。
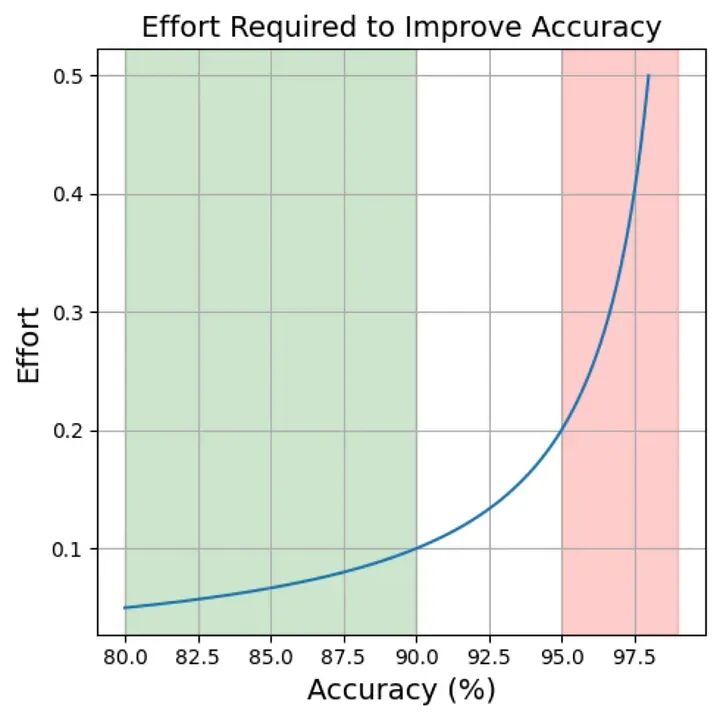
这是我创建的任意图表,显示了提高模型准确性所需的努力量。如您所见,从80%到90%准确性所需的努力比从95%到99%准确性所需的努力要少得多。图片由作者提供。
结果和图表
在重复训练模型、创建更多标签、重新训练等循环后,我创建了一个高性能的微调模型。现在是时候看最终结果了。我制作了四个测试集,每个包含278个样本。我在数据上运行EasyOCR、基线Qwen 2.5 VL 7B模型(Qwen基线模型)和微调模型,您可以在下表中看到结果:
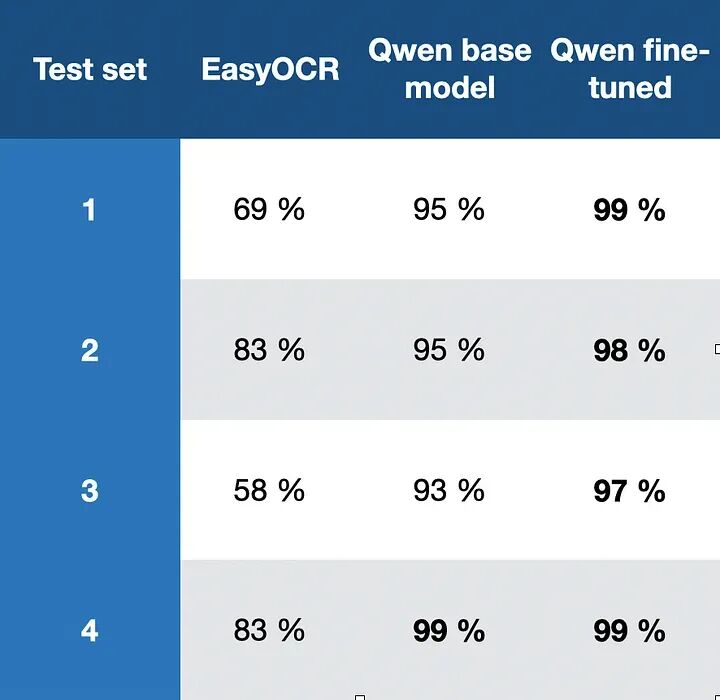
这是三个不同模型在四个测试集上的结果。您可以看到EasyOCR表现不佳,其结果如此糟糕,您无法信任它提供的数字。Qwen基线模型表现相当好,从93-99%不等。在某些情况下,这可能是可接受的性能,但对于我正在处理的数据集和我的性能期望来说还不够。但是,您可以清楚地看到模型的微调工作得很好,它在除第4个测试集之外的所有测试集上表现都比基线Qwen模型更好,其中两个模型同样好。Qwen基线和微调模型基于阿里巴巴的Qwen 2.5 VL 7B。
因此,结果清楚地表明微调按预期工作,大大改善了模型性能。
最后,我还想分享一些可以用数据绘制的图表。
这是树线数据,从图像中提取,使用Uber的H3技术绘制在挪威地图上。您可以看到树线如何向海洋和北方变得更冷(更低),如果您向内陆看,它变得更暖(更高)。图片由作者提供,
如果您想进一步调查数据,所有数据都包含在HuggingFace上的这个parquet文件中。
结论
在本文中,我向您介绍了一个由带有手写文本的小图像组成的物候数据集。我在本文中解决的问题是如何有效从这些图像中提取手写文本。首先,我们检查数据集以了解它的样子、数据的差异以及视觉语言模型在从图像中提取文本时面临的挑战。然后我讨论了您可以使用的三步管道来创建标记数据集并微调模型以提高性能。最后,我突出了一些结果,显示微调Qwen如何比基线Qwen模型更好地工作,我还展示了一些代表我们提取数据的图表。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1070
1070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









