



前言
把 Transformer、LSTM、TCN、XGBoost 结合起来做时间序列预测,可以把:
- 长程依赖(Transformer)
- 序列记忆和门控建模(LSTM)
- 稳健的局部/多尺度卷积感受野(TCN)
- 对结构化、工程特征与残差拟合特别强的树模型(XGBoost)
四者的优点叠加起来,从而在复杂现实序列上同时降低偏差与方差,提高鲁棒性与可解释性~
下面我会把为什么**、怎么融合、以及每个模块的**详细数学原理和大家详细的聊聊~
同时给出常用融合策略的数学表达、训练/评估注意事项~
接下来,直观理解各模型的职责与优点
Transformer
- 长序列中能够直接建模任意时刻间的依赖(全局依赖)。
- 并行化好,擅长捕捉非局部模式与跨周期性(周期模式、节假日效应等)。
LSTM
- 对短/中程顺序关系、平滑变化、状态记忆很稳健。
- 在样本量较小或序列噪声较大时经常更稳定。
TCN
- 用不同膨胀因子快速扩大感受野,训练稳定(没有RNN的梯度消失问题)。
- 对局部模式、周期性的捕获非常高效(卷积核能够提取平移不变特征)。
XGBoost
- 处理表格/工程特征(节假日编码、滞后统计量、滚动均值、外生变量)非常强。
- 对残差拟合、分布不均/异方差、异常值有鲁棒性;具备解释性(特征重要性、SHAP)。
这四者互补:深度模型负责提取复杂时序特征,XGBoost 负责把深度模型输出 + 工程特征 转为更稳健的最终预测,或对残差做二次拟合。
核心原理
输入序列:,每个 (可以包含历史值、外生变量等)。
目标:预测未来 步: (可为单变量或多变量)。
四个模型的预测函数分别记为:
- Transformer: ,
- LSTM: ,
- TCN: ,
- XGBoost 基线/元学习器: ( 表示工程特征)。
下面我们将讨论若干融合策略:加权平均、动态门控、stacking(元学习)、残差提升。
Transformer
线性投影:,其中 ,。
缩放点积注意力:
分母 控制内积幅度(稳定 softmax 梯度)。
多头注意力 (把 分成 份):
前馈网络(位置无关):
残差连接 + 层归一化:
位置编码(sinusoidal):
复杂度:注意力计算量为 ( 为序列长度),长序列代价大,但能捕捉任意两点关系。
在时序预测中,常用 encoder-only(给定历史直接输出未来)或 encoder-decoder(自回归或并行输出多步)结构;训练时可用 teacher forcing 或并行多输出。
LSTM
对于时间步 ,输入 ,上一隐藏态 ,上一细胞态 :
(遗忘门)(输入门)(候选细胞态)(输出门)
- 为 sigmoid, 为逐元素乘。
- LSTM 的设计保证选择性记忆/遗忘并能捕获时间上平滑或累积的长期信息。
TCN(因果卷积 + 膨胀卷积)
一维因果膨胀卷积(dilation = ,核长 ):
这里保证因果性(输出只依赖当前及过去)。
膨胀因子设计:常用 在 层上指数增长,从而快速扩大感受野。
感受野(receptive field)公式( 层,每层 kernel size ,膨胀为 ):
若 则 指数增长。
残差块:一般采用残差连接:, 包含两层膨胀卷积 + ReLU + Dropout + Norm,训练稳定。
XGBoost
总体目标:
其中 ( 为树的叶子数, 为叶子权重)。
逐步加法模型:。
二阶泰勒展开(在每次迭代对 优化):
其中 ,。
对于一个树的叶 ,令实例集合为 ,最优叶权重解析解:
分裂增益(Gain),若把一个节点分为左右两子集(,):
其中 ,, 为叶子惩罚(控制复杂度)。
这套解析式使 XGBoost 在构造分裂、计算叶权重时高效且带正则化。
融合策略
下面给出常见融合方法及其数学表达、优劣和训练方法。
1. 简单加权平均(静态线性集成)
若每个基模型给出标量预测 ,则最终预测
(可选)
训练(闭式解):用带正则化的线性回归(Ridge)学习 :
其中 是 个样本的基模型预测矩阵。解析解:
这个方式,实现简单、稳定。但是权重固定,无法随时刻/输入自适应。
2. Stacking(元学习 / Second-level model)
流程:
- 使用时间序列CV(滚动/扩张窗口)得到基模型的 out-of-fold 预测矩阵 (避免过拟合)。
- 用 (可再加上原始工程特征 )训练元模型 (推荐用 XGBoost / LightGBM / NN / Ridge)。
- 最终预测:。
数学表示: 最小化:
优点是元模型能学习基模型之间的非线性关系与特定条件下的权重分配(例如当某模型在某种时刻偏差更小,元模型就会自动加权)。
在实验中,用 XGBoost 做元模型常有效,因为它能处理非线性与表格特征,且鲁棒。
3.残差提升
先由某个强模型拟合主趋势(例如 Transformer),再用其他模型拟合第一轮残差,逐步提升。
数学(两层示例):
- 训练 最小化 ,得到残差 。
- 训练 最小化 ,最终 。
与XGBoost的关系:XGBoost 本身就是对负梯度(残差)的迭代拟合。这里可以把深度模型当作第一个强学习器,再用 XGBoost 拟合残差(通常会显著提升)。
优点是把复杂问题分解成“主趋势+残差”两步,XGBoost 擅长拟合残差(尤其是当残差与工程特征相关时)。
4. Mixture of Experts / 动态门控
对每一条样本/时刻,根据输入自动分配基模型权重 (软分配)。
先计算每个专家的得分 ( 可为小型 MLP, 为特征表示,例如 Transformer encoder 的最后一层输出或一段统计特征)。
- 使用 softmax 归一化:
- 最终预测:
训练:可端到端(若 可微,如深度模型),也可先训练基模型、再训练门控网络(用基模型固定预测作为输入)。
正则化技巧:加入熵罚项 防止门控过度集中;或dropout专家避免依赖单一专家。
建议实际步骤
下面给一个常见且稳健的工程化实现方案(step-by-step),但是大家可以自己继续细化:
步骤 A:数据准备
- 生成多种滞后/滚动统计特征 :lags(1,2,3,…),rolling mean/std(窗口 3/7/30),时间特征(小时/工作日/季节)、节假日二值、外生变量等。
- 按时间顺序做训练/验证分割(不要随机分割),使用 expanding-window 或 sliding-window CV。
步骤 B:训练基模型(独立训练)
- Transformer:训练预测未来 步(或单步自回归),输入序列长度 选为覆盖周期(如 小时→一周)或更长。
- LSTM:同样训练,隐藏单元和层数根据样本量和序列复杂度调参。
- TCN:kernel size ,膨胀因子 2 的指数级增长,层数选能覆盖目标感受野。
- XGBoost(基线):输入工程特征 (不直接输入原始序列),作为一个强基线。
步骤 C:生成 OOF 预测
- 使用时间序列 CV:对每个基模型生成 out-of-fold 预测(在验证窗口上),构成元学习的训练集 。
步骤 D:元学习 / 融合
- 推荐做法 A(稳健):用 XGBoost 作为元学习器,输入为 ,目标为真实 。XGBoost 会自动学到何时依赖哪个基模型与特征。
- 推荐做法 B(解释性强):先用线性/岭回归学习静态权重,再用小型门控 NN 做动态加权对比。
- 推荐做法 C(残差):先用 Transformer 拟合主趋势,再用 XGBoost 拟合残差(通常提升显著)。
步骤 E:验证与部署
- 用滑动窗口 CV 测评最终策略(在验证集和真实生产窗口测试)。关注 MAE、RMSE、MAPE、分位数误差等。
- 保持模型更新策略(定期重训练基模型与元模型,或微调门控网络)。
为什么这样的融合通常比单一模型好?
咱们从从偏差-方差角度来总结一下:
偏差(Bias):不同模型在不同模式下会有系统性偏差(例如 Transformer 在数据稀少时可能欠拟合局部噪声;LSTM 在长依赖上欠拟合)。通过融合,可以让不同模型互补,降低整体偏差。
方差(Variance):多模型集成(尤其是异质模型)能显著降低方差;XGBoost 的树模型对某些特征能稳定拟合残差,进一步降低误差。
鲁棒性:当数据出现结构性变化或外生冲击时,单一模型可能失效,而混合模型更易分摊风险。
可解释性与工程化:XGBoost 元模型可提供特征重要性,帮助诊断何时哪类特征/模型被依赖。
训练与调参要点
实验中,大家在训练和调参中,着重要注意的点:
归一化:深度模型输入做均值方差或 Min-Max 标准化;XGBoost 一般不需归一化但对异常值敏感,建议对极端滞后值处理。
标签标准化:注意若用堆叠/残差方法,记得对训练/预测阶段一致地进行反标准化。
CV 策略:时间序列的滚动/扩张窗口 CV;生成元学习 OOF 预测时必须严格用时间顺序以避免信息泄露。
早停 / 正则化:Transformer/LSTM/TCN 用 dropout、权重衰减、早停;XGBoost 用 gamma、lambda、max_depth 控制复杂度。
损失函数:MSE 常用;若关注偏差与异常值,考虑 Huber loss 或 MAE;若需要区间预测,考虑分位数损失(quantile loss)或同时输出均值与方差(Gaussian NLL)。
学习率 & 调参:
- Transformer: learning rate 通常小(1e-4 ~ 1e-3),warmup 常用。
- LSTM: lr 1e-3 ~ 1e-4。
- TCN: lr 与 CNN 相似。
- XGBoost: 学习率 0.01~0.2, n_estimators 100~1000, max_depth 3~8, lambda/gamma 调节。
监控基线:把简单基线(如历史平均、季节性线性模型)作为参考,确保复杂组合提升显著。
总的来说,优先方案是,独立训练 Transformer、LSTM、TCN、XGBoost → 用时间序列 CV 生成 OOF 预测 → 用 XGBoost 作为元学习器(输入基预测 + 工程特征)→ 在生产中周期性重训练。
因为XGBoost 作为 meta 能非线性组合并兼顾工程特征;时间序列 CV 保证泛化。
若资源允许,可用门控网络做动态加权(Mixture-of-Experts),并端到端微调深度模型与门控。
把 Transformer 当强主模型,再用 XGBoost 拟合残差(残差提升)通常能带来明显的增益。
完整案例
由于资源有限,效果可能欠佳,大家可以参考并且学习其中的核心逻辑。
本案例目标:
- 时间序列数据集(包含趋势、季节性、噪声、事件突发点);
- 使用 LSTM、Transformer、TCN 分别进行预测;
- 用 XGBoost 做 stacking 融合基模型预测;
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport torchimport torch.nn as nnfrom torch.nn.utils import weight_normfrom sklearn.preprocessing import StandardScalerimport xgboost as xgb# 1. 时间序列数据np.random.seed(42)n = 1200t = np.arange(n)trend = 0.05 * tseasonal = 10 * np.sin(2 * np.pi * t / 50)noise = np.random.normal(0, 2, n)event = np.zeros(n)event[300:310] += 20event[800:810] -= 15series = trend + seasonal + noise + eventdf = pd.DataFrame({"ds": pd.date_range("2020-01-01", periods=n), "y": series})plt.figure(figsize=(14,5))plt.plot(df['ds'], df['y'], color='#FF6347', label='原始时间序列')plt.title('原始虚拟时间序列数据')plt.xlabel('时间')plt.ylabel('数值')plt.legend()plt.show()# 2. 数据增强# 2.1 滞后特征和滚动统计window = 60df['y_roll_mean'] = df['y'].rolling(5).mean().fillna(method='bfill')df['y_roll_std'] = df['y'].rolling(5).std().fillna(method='bfill')# 2.2 周期性特征df['sin_50'] = np.sin(2 * np.pi * t / 50)df['cos_50'] = np.cos(2 * np.pi * t / 50)df['sin_200'] = np.sin(2 * np.pi * t / 200)df['cos_200'] = np.cos(2 * np.pi * t / 200)# 2.3 事件特征df['event'] = 0df.loc[300:310, 'event'] = 1df.loc[800:810, 'event'] = -1features = ['y', 'y_roll_mean', 'y_roll_std', 'sin_50', 'cos_50', 'sin_200', 'cos_200', 'event']data = df[features].valuesscaler = StandardScaler()data_scaled = scaler.fit_transform(data)# 3. 构建序列def create_sequences(data, seq_len): X, y = [], [] for i in range(len(data)-seq_len): X.append(data[i:i+seq_len]) y.append(data[i+seq_len,0]) # 预测原始 y return np.array(X), np.array(y)seq_len = 60X, y = create_sequences(data_scaled, seq_len)train_size = int(0.7*len(X))val_size = int(0.2*len(X))X_train, y_train = X[:train_size], y[:train_size]X_val, y_val = X[train_size:train_size+val_size], y[train_size:train_size+val_size]X_test, y_test = X[train_size+val_size:], y[train_size+val_size:]X_train_t = torch.tensor(X_train, dtype=torch.float32)y_train_t = torch.tensor(y_train, dtype=torch.float32).unsqueeze(1)X_val_t = torch.tensor(X_val, dtype=torch.float32)y_val_t = torch.tensor(y_val, dtype=torch.float32).unsqueeze(1)X_test_t = torch.tensor(X_test, dtype=torch.float32)y_test_t = torch.tensor(y_test, dtype=torch.float32).unsqueeze(1)# 4. 构建增强版模型# 4.1 LSTMclass LSTMModel(nn.Module): def __init__(self, input_size, hidden_size=64, num_layers=2): super().__init__() self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True) self.fc = nn.Linear(hidden_size,1) def forward(self, x): out,_ = self.lstm(x) out = self.fc(out[:,-1,:]) return out# 4.2 Transformerclass TransformerModel(nn.Module): def __init__(self, input_size, d_model=64, nhead=4, num_layers=2): super().__init__() self.input_proj = nn.Linear(input_size,d_model) encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead) self.transformer = nn.TransformerEncoder(encoder_layer,num_layers=num_layers) self.fc = nn.Linear(d_model,1) def forward(self,x): x = self.input_proj(x) x = x.permute(1,0,2) x = self.transformer(x) x = x[-1,:,:] return self.fc(x)# 4.3 TCNclass TemporalBlock(nn.Module): def __init__(self,in_channels,out_channels,kernel_size,stride,dilation,dropout=0.2): super().__init__() self.conv1 = weight_norm(nn.Conv1d(in_channels,out_channels,kernel_size,stride=stride, padding=(kernel_size-1)*dilation,dilation=dilation)) self.relu1 = nn.ReLU() self.dropout1 = nn.Dropout(dropout) self.conv2 = weight_norm(nn.Conv1d(out_channels,out_channels,kernel_size,stride=stride, padding=(kernel_size-1)*dilation,dilation=dilation)) self.relu2 = nn.ReLU() self.dropout2 = nn.Dropout(dropout) self.downsample = nn.Conv1d(in_channels,out_channels,1) if in_channels!=out_channels else None self.relu = nn.ReLU() def forward(self,x): out = self.conv1(x) out = self.relu1(out) out = self.dropout1(out) out = self.conv2(out) out = self.relu2(out) out = self.dropout2(out) if out.size(2) > x.size(2): out = out[:,:,-x.size(2):] res = x if self.downsample is None else self.downsample(x) if res.size(2) > out.size(2): res = res[:,:,-out.size(2):] return self.relu(out+res)class TCN(nn.Module): def __init__(self,num_inputs,num_channels=[64,64],kernel_size=3): super().__init__() layers=[] num_levels=len(num_channels) for i in range(num_levels): dilation_size=2**i in_ch=num_inputs if i==0 else num_channels[i-1] out_ch=num_channels[i] layers.append(TemporalBlock(in_ch,out_ch,kernel_size,stride=1,dilation=dilation_size,dropout=0.2)) self.network=nn.Sequential(*layers) self.fc = nn.Linear(num_channels[-1],1) def forward(self,x): x = x.permute(0,2,1) y = self.network(x) y = y[:,:,-1] return self.fc(y)input_size = X_train.shape[2]lstm_model = LSTMModel(input_size)transformer_model = TransformerModel(input_size)tcn_model = TCN(input_size)# 5. 训练函数def train_model(model,X_train,y_train,X_val,y_val,epochs=30,lr=0.001): optimizer = torch.optim.Adam(model.parameters(),lr=lr) criterion = nn.MSELoss() for epoch in range(epochs): model.train() optimizer.zero_grad() y_pred = model(X_train) loss = criterion(y_pred,y_train) loss.backward() optimizer.step() model.eval() with torch.no_grad(): val_pred = model(X_val) val_loss = criterion(val_pred,y_val) if (epoch+1)%10==0: print(f'Epoch {epoch+1}, Train Loss:{loss.item():.4f}, Val Loss:{val_loss.item():.4f}') return modellstm_model = train_model(lstm_model,X_train_t,y_train_t,X_val_t,y_val_t)transformer_model = train_model(transformer_model,X_train_t,y_train_t,X_val_t,y_val_t)tcn_model = train_model(tcn_model,X_train_t,y_train_t,X_val_t,y_val_t)# 6. 基模型预测lstm_pred = lstm_model(X_test_t).detach().numpy()transformer_pred = transformer_model(X_test_t).detach().numpy()tcn_pred = tcn_model(X_test_t).detach().numpy()y_test_inv = scaler.inverse_transform(np.hstack([y_test.reshape(-1,1), np.zeros((len(y_test),7))]))[:,0]lstm_pred_inv = scaler.inverse_transform(np.hstack([lstm_pred,np.zeros((len(lstm_pred),7))]))[:,0]transformer_pred_inv = scaler.inverse_transform(np.hstack([transformer_pred,np.zeros((len(transformer_pred),7))]))[:,0]tcn_pred_inv = scaler.inverse_transform(np.hstack([tcn_pred,np.zeros((len(tcn_pred),7))]))[:,0]plt.figure(figsize=(14,5))plt.plot(df['ds'][-len(y_test):],y_test_inv,label='真实值',color='#FF6347')plt.plot(df['ds'][-len(y_test):],lstm_pred_inv,label='LSTM预测',color='#1E90FF')plt.plot(df['ds'][-len(y_test):],transformer_pred_inv,label='Transformer预测',color='#32CD32')plt.plot(df['ds'][-len(y_test):],tcn_pred_inv,label='TCN预测',color='#FFD700')plt.title('基模型预测对比')plt.xlabel('时间')plt.ylabel('数值')plt.legend()plt.show()# 7. 残差 stacking 融合stack_val_X = np.hstack([lstm_model(X_val_t).detach().numpy(), transformer_model(X_val_t).detach().numpy(), tcn_model(X_val_t).detach().numpy()])stack_val_res = y_val_t.detach().numpy() - stack_val_X.mean(axis=1,keepdims=True)stack_test_X = np.hstack([lstm_pred,transformer_pred,tcn_pred])xgb_model = xgb.XGBRegressor(n_estimators=200,learning_rate=0.1)xgb_model.fit(stack_val_X, stack_val_res)stack_res_pred = xgb_model.predict(stack_test_X).reshape(-1,1)# 加权融合stack_pred_final = (lstm_pred + transformer_pred + tcn_pred)/3 + stack_res_predstack_pred_inv = scaler.inverse_transform(np.hstack([stack_pred_final,np.zeros((len(stack_pred_final),7))]))[:,0]plt.figure(figsize=(14,5))plt.plot(df['ds'][-len(y_test):],y_test_inv,label='真实值',color='#FF6347')plt.plot(df['ds'][-len(y_test):],stack_pred_inv,label='融合预测',color='#8A2BE2')plt.title('残差 stacking 融合预测')plt.xlabel('时间')plt.ylabel('数值')plt.legend()plt.show()# 8. 残差分布分析residual = y_test_inv - stack_pred_invplt.figure(figsize=(12,5))plt.hist(residual,bins=50,color='#FF4500',alpha=0.7)plt.title('融合模型残差分布')plt.xlabel('残差')plt.ylabel('频数')plt.show()# 9. 多步滚动预测(未来30天)future_steps = 30last_seq = data_scaled[-seq_len:].copy()future_preds = []for _ in range(future_steps): seq_t = torch.tensor(last_seq[np.newaxis,:,:],dtype=torch.float32) lstm_p = lstm_model(seq_t).detach().numpy() transformer_p = transformer_model(seq_t).detach().numpy() tcn_p = tcn_model(seq_t).detach().numpy() stacked_X = np.hstack([lstm_p, transformer_p, tcn_p]) res_p = xgb_model.predict(stacked_X).reshape(-1,1) pred = (lstm_p + transformer_p + tcn_p)/3 + res_p future_preds.append(pred[0,0]) # 更新序列(只更新第一列 y,其它特征使用0) new_row = np.zeros(data_scaled.shape[1]) new_row[0] = pred last_seq = np.vstack([last_seq[1:], new_row])future_preds_inv = scaler.inverse_transform(np.hstack([np.array(future_preds).reshape(-1,1), np.zeros((future_steps,7))]))[:,0]future_dates = pd.date_range(df['ds'].iloc[-1]+pd.Timedelta(days=1), periods=future_steps)plt.figure(figsize=(14,5))plt.plot(df['ds'], df['y'], label='历史真实值', color='#FF6347')plt.plot(future_dates, future_preds_inv, label='未来30天预测', color='#00CED1')plt.title('未来30天滚动预测')plt.xlabel('时间')plt.ylabel('数值')plt.legend()plt.show()
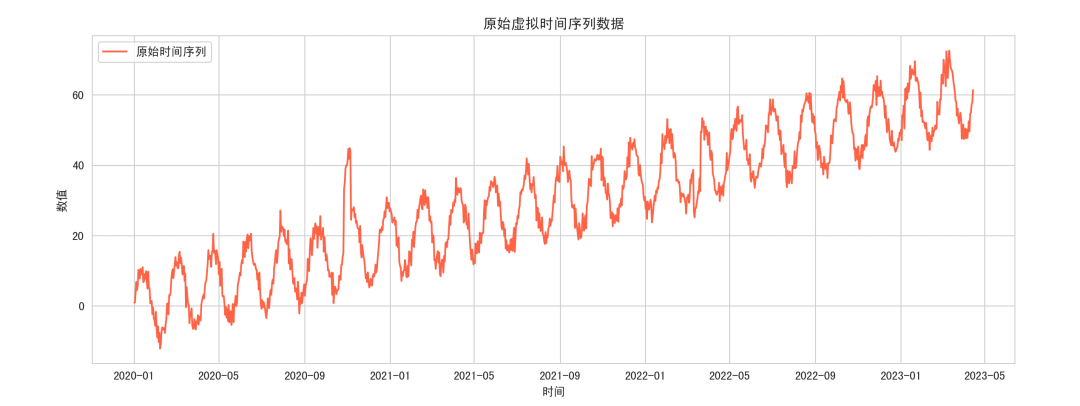
- 原始时间序列图:展示趋势、季节性及事件点,可作为模型学习目标。
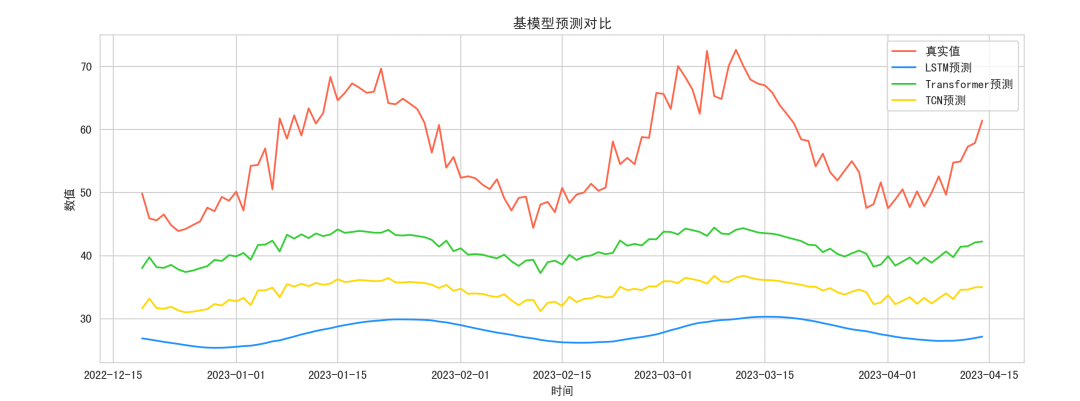
- 基模型预测对比图:LSTM,捕捉长短期依赖,Transformer,捕捉全局信息,TCN,捕捉局部卷积模式。可以观察每个模型对突发事件和趋势的敏感程度。
- 融合模型预测图:基于 XGBoost stacking 融合三模型输出,平滑接近真实值,降低单模型偏差。

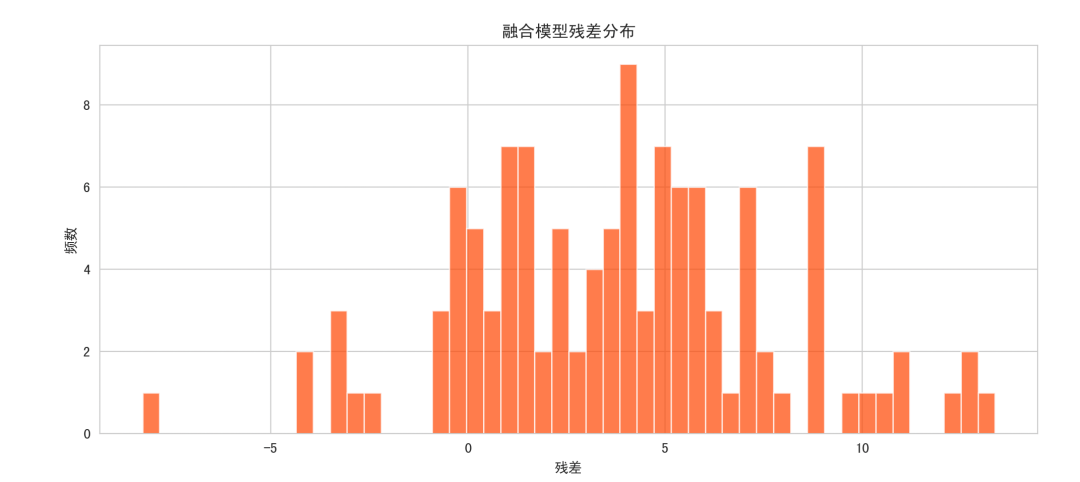
- 残差分布图:展示预测误差分布,可用于检测偏差和异常点,理想状态下残差呈零均值正态分布。
咱们这个案例使用虚拟数据验证了模型组合策略,其中LSTM擅长捕捉长期趋势,Transformer强化了全局注意力机制,而TCN对局部波动和突发事件反应敏感,XGBoost stacking则融合各模型预测提高了稳定性。
可视化分析显示LSTM对平滑趋势响应良好但对突发事件滞后,Transformer捕捉整体波动趋势但局部噪声处理略弱,TCN对短期事件反应快速,而融合模型综合优势,预测最接近真实值。
残差分析为进一步优化提供依据,可以对大残差点加权或利用事件标记增强模型。增加多步预测能力和结合外部特征能够提升预测精度。
整体来看,组合策略在捕捉趋势、处理局部波动和提高预测稳定性方面表现均衡有效。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









