



前言
大模型真的很厉害,它们不仅能写出复杂的代码,解决高难度的奥数题,更展现出令人惊叹的思考力。其思考的深度、广度,应该超过99%的普通人。大概从GPT o1开始,大模型有了"深度思考"的能力,而且这个能力正在飞速地迭代,继续变得“更聪明”。
今天,就来和大家聊一个比较酷的话题:大语言模型(LLM)是如何学会“思考”和推理的?希望此文可以给大家一些启发。
大模型思考的“快与慢”
很多人认为,AI的聪明之处在于它能瞬间给出正确答案,这似乎是一种超乎人类的直觉。但这种看法其实是一种误解。在大多数情况下,大模型直接给出的答案,就像是一种“本能反射”。它直接从海量数据中“背诵”或“联想”出一个最可能的答案,这更像是记忆力而非真正的推理。
▲ 人类的思维的两种模式
这种“快思考”虽然高效,但难以处理需要多步逻辑的新问题。而真正的推理能力,是让AI能够处理那些从未在训练数据中见过的、需要多步逻辑才能解决的新问题。这就像一个人在面对一道全新的数学题时,不是靠背诵答案,而是通过一步步的逻辑推导来找到解法。这,才是我们今天所说的“LLM推理”的核心。
大模型的“推理”到底是什么?
要理解推理,我们首先要明白大模型的工作原理。简单来说,大模型的核心任务是“猜词”(或者称为 词语接龙)。它通过学习海量的文本数据,来预测给定一串文字后,下一个最可能出现的词语(在AI领域我们称之为“令牌”或Tokens)。
举个例子:当你输入“太阳从东边”,模型会根据它学到的知识,预测出“升起”。
而大模型的“思考”,就是它在生成最终答案之前,自己生成一系列的中间令牌。这些令牌不是直接的答案,而是用来引导模型走向正确答案的“内部独白”或“思考路径”。
以下,我们介绍几个与大模型思考和推理能力最密切相关的概念和方法。
一:中间令牌(Tokens)的本质与作用
【学术原理】 在Transformer架构中,推理过程中的每一个中间令牌(Intermediate Token)都是模型基于当前上下文(包括输入和之前生成的令牌)预测出来的。这些令牌的生成过程是序列化的,即一个令牌的出现会影响下一个令牌的概率分布。
【通俗理解】 想象一下你正在写一篇小说。你每写完一个句子,大脑都会思考接下来最可能出现的词语和情节。大模型的中间令牌就像这个过程的具象化。它不是一次性得到最终答案,而是通过一步步地“猜”出中间步骤,最终构建出完整的推理过程。
为什么会生成很多令牌?
- 复杂性决定长度:对于一个复杂的推理问题,比如一个多步数学题,它需要更多、更详细的中间步骤才能确保正确。就像人类解题时需要写草稿一样,AI也需要足够的“草稿空间”来记录它的思考过程。
- 可解释性:这些中间令牌不仅是为了帮助模型得到正确答案,也使得模型的推理过程变得可解释(Explainable)。我们可以通过查看这些中间令牌,来理解模型是如何从问题一步步走到答案的。
- 提高准确率:研究表明,让模型生成更长的、更详细的中间步骤,可以显著提高最终答案的准确率。因为这相当于给模型更多的机会去纠正错误、完善逻辑。这就像我们写数学题,步骤越详细,出错的概率就越低。
二:思维链(Chain-of-Thought, CoT)
【学术原理】 CoT是一种提示工程(Prompt Engineering)技巧,其核心是利用模型的“少样本学习”(Few-shot Learning)能力。通过在输入中提供一个带有明确推理步骤的例子,模型能够被诱导去模仿这个模式,从而将一个复杂的、需要多步才能解决的问题,分解成一系列更小的、更易于处理的子问题。
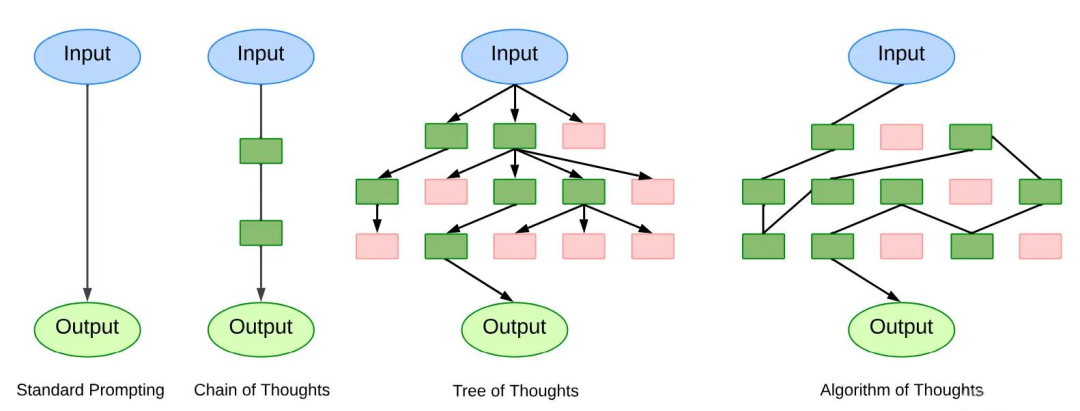
【通俗理解】 想象一下,你的孩子问你:“我有3个苹果,爸爸比我多2个,我们总共有几个?”如果你只给一个答案“8”,孩子可能不明白。但如果你分步解释:“你爸爸比我多2个,所以他有 3+2=5 个苹果。然后你们俩加起来是 3+5=8 个。” 孩子就恍然大悟了。AI也是一样!
- 例子1:
-
问题: “将’artificial intelligence’中每个单词的最后一个字母连接起来。”
答案: “le”。
-
AI的“思考过程”:
- “artificial”的最后一个字母是“l”。
- “intelligence”的最后一个字母是“e”。
- 将“l”和“e”连接起来得到“le”。
- 例子2:
-
问题: “一个正方形的四个顶点分别是(-2, 2), (2, -2), (-2, -6), 和(-6, -2),它的面积是多少?”
-
答案: 32。
AI的“思考过程”:

三:自洽性(Self-Consistency)
【学术原理】 自洽性是一种基于多数投票的推理方法。其核心思想是,一个正确的推理路径应该具有一致性。该方法通过多次采样,让模型生成多个不同的CoT推理路径和相应的答案,然后选择出现频率最高的答案作为最终结果。
【如何判定结果好坏?】 这就是自洽性的核心价值。在LLM推理中,我们有一个关键的经验法则:“更高的一致性代表更高的准确性”(Higher Consistency Indicates Higher Accuracy)。当模型通过不同的思考路径,反复得出同一个答案时,这个答案的正确率会大大增加。自洽性就是利用这个原理,通过大规模的“内部验证”,来提升最终结果的质量。
【通俗理解】 人类在解一个复杂问题时,通常会多想几遍,确认答案。AI也一样!自洽性原理就是:让AI对同一个问题生成多个不同的“思维链”,然后从中选择出现频率最高的那个答案作为最终答案。这就像一个团队开会讨论,最终采纳了大部分人的共识。
- 例子:
-
问题: “一个农场主每天收16个鸡蛋,早餐吃掉3个,烤松饼用4个,剩下的以2美元一个卖出,他每天赚多少钱?”
-
AI生成了3个不同的“思考过程”:
路径1: 剩下 16−3−4=9 个鸡蛋。所以每天赚 2×9=18 美元。
路径2: 她用 2×(16−4−3)=26 美元卖出剩下的。
路径3: 吃掉3个后剩 16−3=13 个。烤松饼后剩 13−4=9 个。所以每天赚 9×2=18 美元。
-
最终结果: 尽管思维路径不同,但有两条路径都得到了“18”这个答案。根据自洽性原则,模型会选择“18”作为最可信的答案。
四:RECITE(增强生成)
【学术原理】 RECITE是“增强生成”(Recitation-augmented Generation)的缩写,其核心思想是在生成最终答案之前,先让模型“背诵”其内部记忆中与问题相关的知识。这使得模型能够从内部记忆中提取和整理关键信息,从而提高在闭卷问答任务中的准确性。
【通俗理解】 就像我们在参加考试前,会先在脑子里回顾相关知识点一样。AI在回答一个问题时,也会先在大脑里“翻找”一遍,把所有相关的知识点都列出来,再用这些知识来构建答案。
- 例子:
-
问题: “爱因斯坦在1905年发表了哪些重要论文?”
答案: 爱因斯坦在1905年发表了关于光电效应、布朗运动和狭义相对论的论文。
-
AI的“思考过程”:
- (RECITE阶段) 模型首先从内部记忆中提取知识:“1905年是爱因斯坦的奇迹年,他发表了关于光电效应、布朗运动和狭义相对论的四篇革命性论文。”
- (生成阶段) 基于提取的知识,模型开始构建答案:“爱因斯坦在1905年发表了多篇重要论文,其中包括关于光电效应、布朗运动和狭义相对论的论文。这些论文共同奠定了现代物理学的基础。”
五:聚合与检索(Aggregation and Retrieval)
【学术原理】 聚合与检索是LLM推理中的一个关键范式,它将LLM的内部知识与外部信息源相结合,以增强其推理能力。该范式通常分为两个步骤:检索(Retrieval)和聚合(Aggregation)。
- 检索:模型根据用户输入,从外部知识库(如互联网、数据库)中检索相关信息。
- 聚合:模型将检索到的外部信息与自身内部知识进行融合,从而形成一个更全面、更准确的答案。这个过程与RECITE类似,但更强调利用外部信息源。
【通俗理解】 这就像是AI在回答问题前,会先去“上网查资料”。它不仅会利用自己大脑里的知识,还会去图书馆(外部数据库)或互联网上搜索相关信息,然后把所有这些信息综合起来,最终给出一个最全面的答案。
- 例子:
- 问题: “请解释一下《辛德勒的名单》这部电影在哪些方面获得了奥斯卡奖,以及它对历史的影响。”
- AI的“思考过程”:
- (检索) 模型会去外部知识库检索关于《辛德勒的名单》奥斯卡获奖信息,以及相关的历史评论。
- (聚合) 模型将检索到的信息(如获得最佳影片、最佳导演等7项大奖,以及它对公众认识大屠杀的影响)与自身关于电影的内部知识融合。
- (生成) 最终生成一个完整的答案,既包含获奖细节,也包含了其在历史和文化上的深远影响。
六:模型(而非人类)生成思考过程
【学术原理】 在大模型的训练和微调过程中,使用由模型本身生成的推理路径(而非人类手动编写的)来作为训练数据,是一种高效的策略。这背后的原因是,高质量的人类标注数据昂贵且稀缺,而模型可以大规模、快速地生成推理数据。
【通俗理解】 假设我们需要教一个AI做大量的数学题。让数学老师一道道去写解题步骤会非常耗时耗力。而我们可以让一个表现不错的AI自己去写解题步骤,然后用这些步骤去训练一个新模型。这种方法可以大大加快训练速度,让AI在短时间内学到更多知识。
- 例子:
- 场景: 训练一个用于复杂数学题解答的大模型。
- 传统方法(人类生成):雇佣许多数学家,为成千上万道数学题编写详细的解题步骤。
- 模型生成方法(更高效):
- 用一个基础模型生成大量的、包含解题过程的数学题。
- 用自洽性等方法验证这些解题过程的正确性。
- 将这些经过验证的、高质量的“模型思考过程”作为新的训练数据,来训练一个更强大的模型。
小 结
通过以上这些核心技术,我们看到大模型正在从一个“快速回答器”进化为一个有能力进行多步逻辑推理的“思考者”。这些推理方法,尤其是思维链和自洽性,正在让大模型变得更加强大和可信。
AI的未来不仅仅是算法的进步,更是我们对智能本质的理解。我们正在从一个只做模式识别的AI时代,走向一个能够进行复杂推理和解决问题的时代。这些技术的进步,正在逐步实现我们对更高级人工智能(AGI)的期望,使其能够处理更复杂、更抽象的任务,最终为人类带来更多的价值。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1316
1316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









