



前言
- 训练一个好的向量模型的重点在于最大限度地利用了更多、更高质量的负样本,来训练模型。
- 腾讯提出的Conan-embedding,采用了动态硬负样本挖掘方法,以便在整个训练过程中向模型展示更多具有挑战性的负样本。
- 最近发布Conan-embedding-V2版本,在MTEB榜单上已经超越了BGE等一众传统豪强。

- 支持中、英双语,


一、Conan-embedding-V2
- V1版本主要基于通用预训练的双向Bert模型进行Embedding任务的训练。
- V2版本从头训练了原创词表和模型结构的大模型基座——Conan-1.4B,在此基础上进行了中、英、多语言的Embedding任务的训练。
- 上下文长度从v1版本的512,提升到了32k

训练的4个阶段
-
第1和第2阶段,大语言模型(LLM)训练阶段
-
- 加入嵌入数据,以更好地使LLM与嵌入任务对齐
- 设计了Conan-1.4B,包含8层Attention Layers,Hidden Size为3584,最长上下文32k。
- 参数量是1.4B,能够在较少的参数下提供更大的Embedding维度。
- 从基础的字母、符号上,在约40万条多语言语料上训练了Conan的BBPE分词器,目标词表大小15万,完成了词表训练。
-
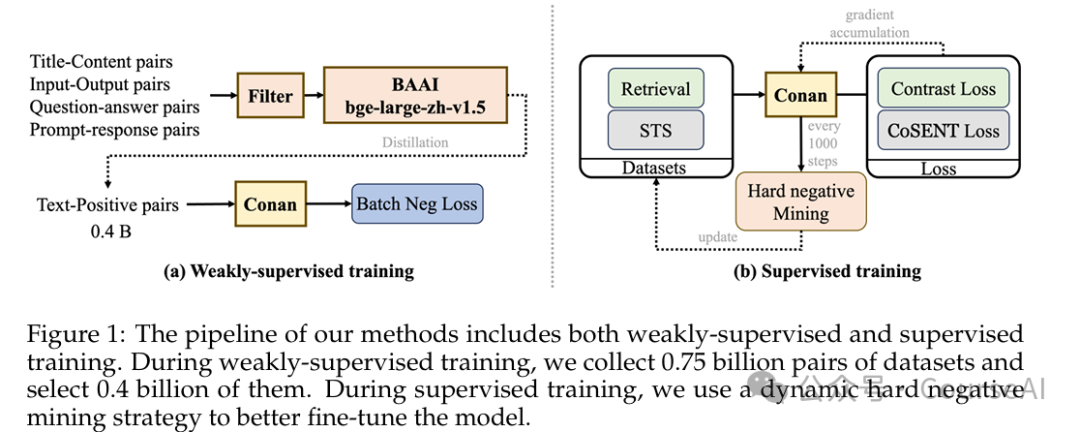
第3阶段,弱监督训练阶段
-
- 使用与LLM监督微调(SFT)相同的配对数据,并应用软掩码来弥合LLM与嵌入模型之间的差距。
- 使用gte-Qwen2-7B-instruct模型进行评分,并丢弃得分低于0.4的数据
- 训练中采用了InfoNCE损失函数,并结合In-Batch Negative采样
-
第4阶段,监督训练阶段
-
- 引入了跨语言检索数据集和动态硬负例挖掘方法,以提高数据的多样性和价值
- 针对不同的下游任务进行任务特定的微调。
- 将任务分为四类:检索、跨语言检索、分类和语义文本相似度(STS)。
- 前三类任务:包括一个查询、一个正例文本和一些负例文本,使用经典的InfoNCE损失函数。
- STS任务涉及区分两个文本之间的相似度,采用CoSENT损失来优化。
为了更好的对比Conan-embedding提升了哪些内容,下面也简单介绍一下Conan-embeddingV1,尤其注意一下难例数据挖掘的方法,v2版本也是用同样的方法
二、Conan-embeddingV1
总共分为:预训练和微调两个阶段
2.1 预训练阶段
- 筛选数据:bge-large-zh-v1.5模型评分,丢弃所有得分低于 0.4 的数据。
- 使用带批内负样本的 InfoNCE 损失进行训练,它利用小批量内的其他样本作为负样本优化模型。
- 即,在每个小批量中,除了目标样本的正样本对之外的所有样本都被视为负样本。
- 通过最大化正样本对的相似性并最小化负样本对的相似性,批内负样本 InfoNCE 损失可以有效地提高模型的判别能力和表示学习性能。
- 此方法通过充分利用小批量内的样本,提高了训练效率,减少了生成额外负样本的需求。

其中,是正样本的查询, 是正样本的段落,是同一批次中其他样本的段落,被视为负样本。
2.2 监督微调
监督微调时对不同的下游任务执行特定的微调任务。将任务分为两类:
-
检索任务:
-
- 包括查询、正文本和负文本,经典的损失函数是 InfoNCE 损失。
-
STS 任务:
-
- 涉及区分两个文本之间的相似性,经典的损失函数是交叉熵损失。
CoSENT 损失略优于交叉熵损失,因此采用 CoSENT 损失来优化 STS 任务。

- 其中,是尺度温度, 是余弦相似度函数,是和 之间的相似度。
三、难例数据挖掘
一种动态难样本挖掘方法介绍:
- 对于每个数据点,记录当前相对于查询的难样本的平均分数。
- 每 100 次迭代,如果分数乘以 1.15 小于初始分数,并且分数的绝对值小于 0.8,将认为负样本不再困难,并进行新一轮的难样本挖掘。
- 在每次动态困难负例挖掘过程中,如果需要替换困难负例,使用 (i-1)\times n + 10到i\times n +10 的案例作为负例,其中 i表示第 i次替换,而 n表示每次使用的困难负例数量。

- 上图展示了动态困难负例挖掘与标准困难负例挖掘中正例和负例的得分-步数曲线
- 随着步骤的增加,标准困难负例挖掘中负例的得分停止下降并开始振荡,表明模型已经完成了从该批负例中学习。
- 相反,动态困难负例挖掘一旦检测到负例不再对模型构成挑战,就会替换这些困难负例。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1757
1757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









