



前言
我们平时使用的ChatGPT、kimi、豆包等Ai对话工具,其服务器都是部署在各家公司的机房里,如果我们有一些隐私数据发到对话中,很难保证信息是否安全等问题,如何在保证数据安全的情况下,又可以使用大语言模型,Ollma可以告诉你答案!
这是一个保姆级的教程,从下载到成功运行Qwen2.5大模型,更适合没有玩过Ollma的小白同学

image.png
1. Ollma 是什么?
★
一句话介绍:一个可以让你在本地启动并运行大型语言模型的工具!
”
Ollma是一个开源的大模型服务工具,他可以让你在一行代码不写的情况下,在本地通过一条命令即可运行大模型。
Ollma会根据电脑配置,自动选择用CPU还是GPU运行,如果你的电脑没有GPU,会直接使用CPU进行运行(可能有点慢)
2. 安装教程
Ollma官网:[https://ollama.com/]
模型仓库:[https://ollama.com/library]
2.1 首先去官网下载
从主页点击下载,直接跳转到了当前系统所兼容的下载界面,点击download,一键下载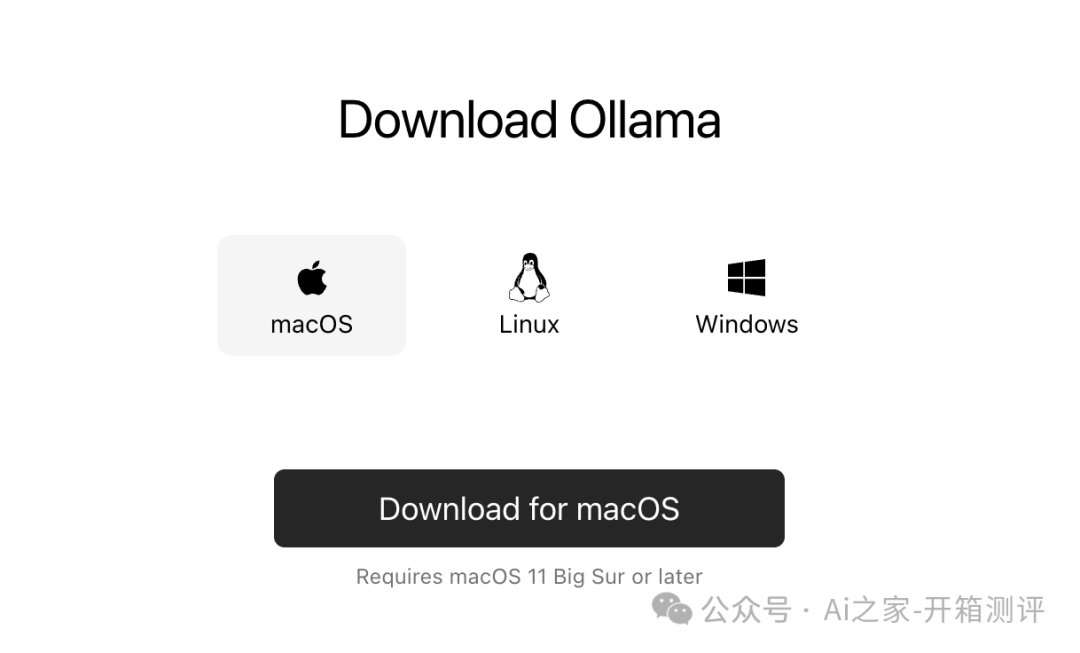
2.2 下载好之后安装
博主的电脑是Mac,下载好之后,直接把压缩包解压,然后移动到应用程序中即可,其他操作系统,参考这个文档:
[Windows 下的安装与配置](https://datawhalechina.github.io/handy-ollama/#/C2/2.%20Ollama%20%E5%9C%A8%20Windows%20%E4%B8%8B%E7%9A%84%E5%AE%89%E8%A3%85%E4%B8%8E%E9%85%8D%E7%BD%AE)``[Linux 安装Ollma ](https://datawhalechina.github.io/handy-ollama/#/C2/3.%20Ollama%20%E5%9C%A8%20Linux%20%E4%B8%8B%E7%9A%84%E5%AE%89%E8%A3%85%E4%B8%8E%E9%85%8D%E7%BD%AE)``[Docker 安装 Ollma](https://datawhalechina.github.io/handy-ollama/#/C2/4.%20Ollama%20%E5%9C%A8%20Docker%20%E4%B8%8B%E7%9A%84%E5%AE%89%E8%A3%85%E4%B8%8E%E9%85%8D%E7%BD%AE)
下载好之后,打开,当这个帅气的小羊驼显示在你的任务栏中的时候,说明已经启动成功了!

image.png
2.3 测试一下
打开命令行,输入ollama -h看到以下界面,就可以进行下一步,操作了~
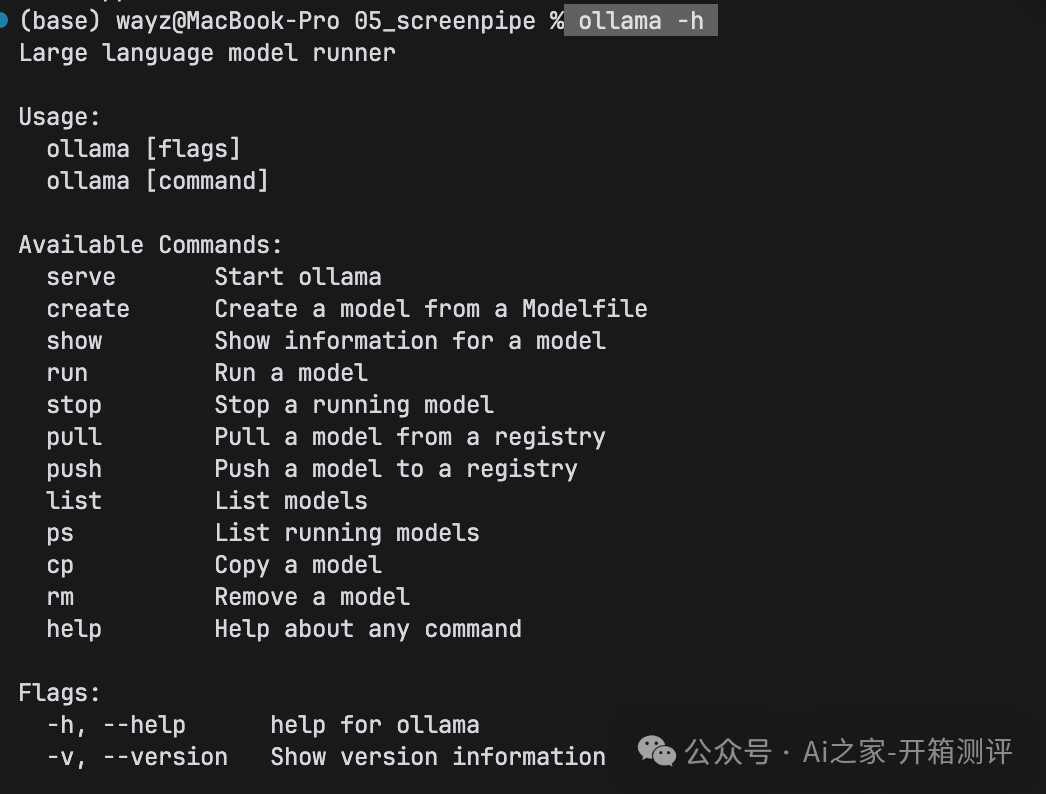
image.png
3. 导入开源Qwen 2.5 - 0.5B 大模型
3.1 去模型仓库搜索模型
我们在上面提到的Ollma模型仓库中找到最新的千问大模型
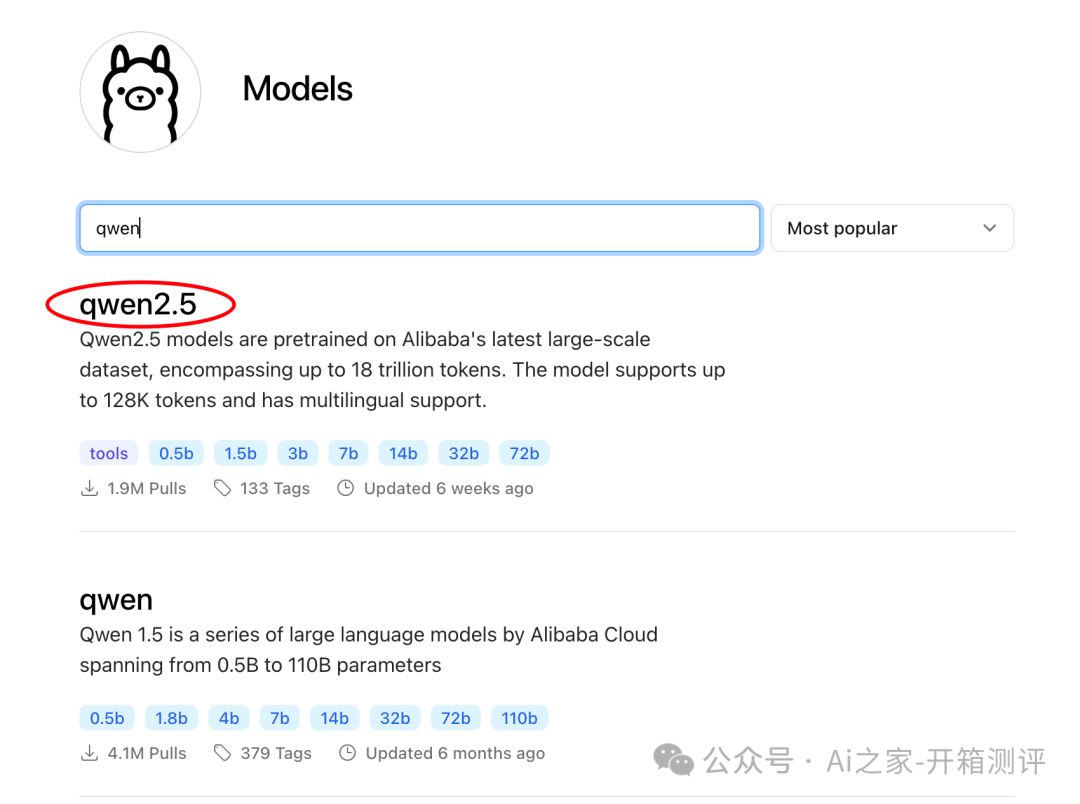 点进去,界面如下:
点进去,界面如下: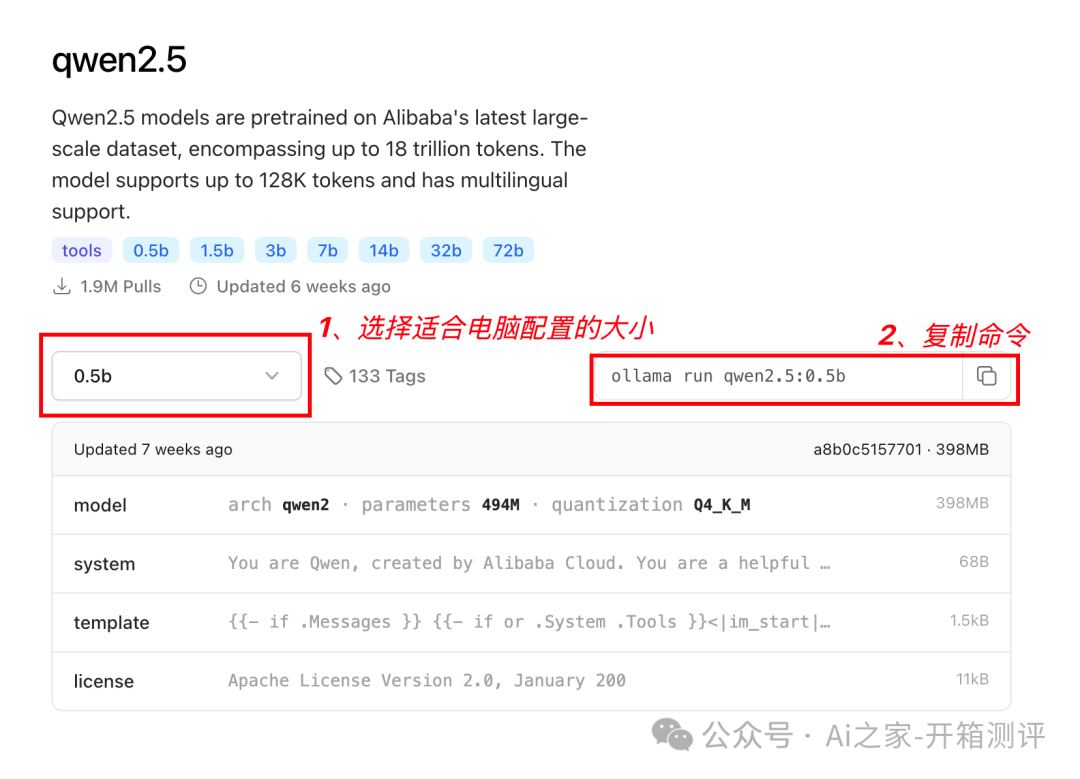
3.2 加载模型
将上面的命令复制到命令行,回车执行!等待下载

image.png
等进度100%了,即可使用模型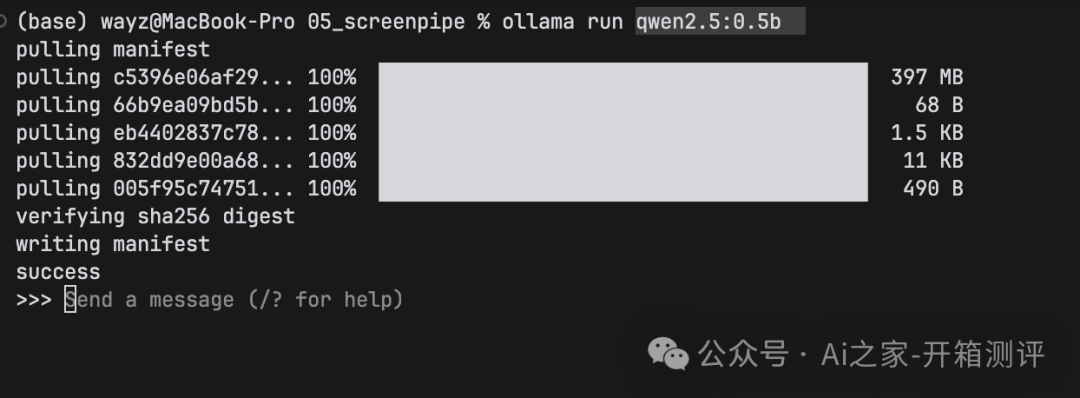
3.3 使用模型
在命令行中,即可开启与千问大模型的对话,看到这里,是不是感觉很简单,快去点个赞!
输入/bye方可结束对话。
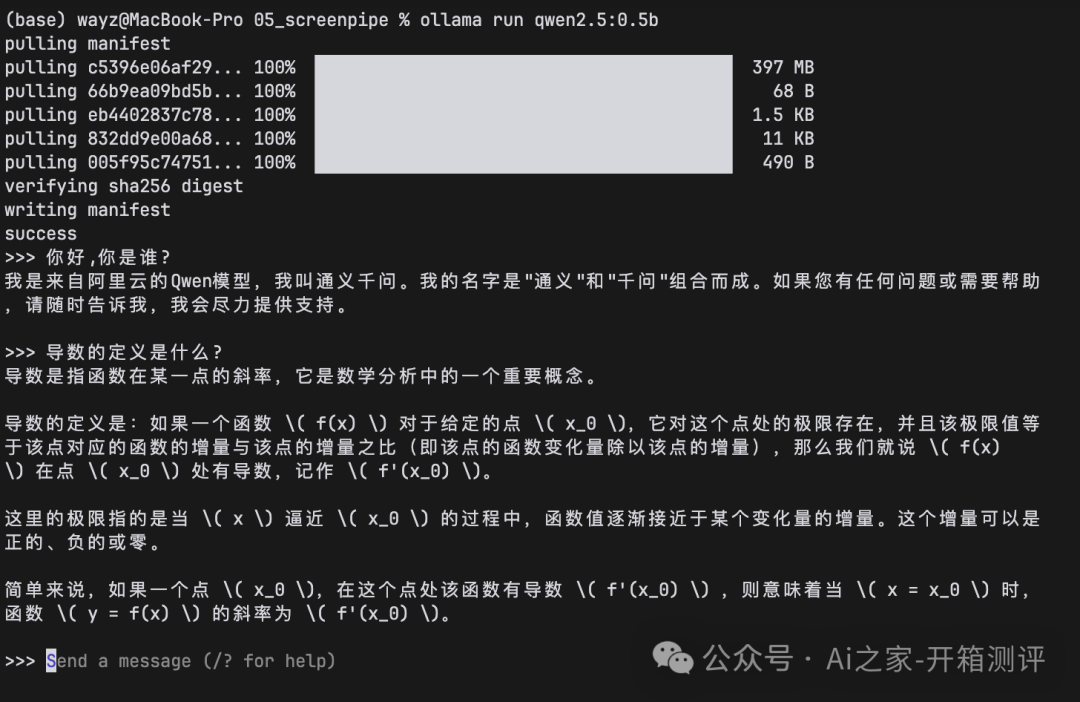
image.png
都看到这里了,点个赞再走吧!码字实属不易呀。
4. 部署webUI可视化对话
本文使用FastAPI 部署Ollma可视化页面,简单4步即可
1、克隆仓库
git clone https://github.com/AXYZdong/handy-ollama
克隆完成进入目标目录:
cd handy-ollama/notebook/C6/fastapi_chat_app
2、安装依赖
pip install -r requirements.txt
pip install 'uvicorn[standard]'
3、修改app.py 代码
输入vim websocket_handler.py命令(确保你在fastapi_chat_app目录下先)更改model代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import ollama
from fastapi import WebSocket
async def websocket_endpoint(websocket: WebSocket):
await websocket.accept()
user_input = await websocket.receive_text()
stream = ollama.chat(
model='qwen2.5:0.5b',
messages=[{'role': 'user', 'content': user_input}],
stream=True
)
try:
for chunk in stream:
model_output = chunk['message']['content']
await websocket.send_text(model_output)
except Exception as e:
await websocket.send_text(f"Error: {e}")
finally:
await websocket.close()
4、运行模型
输入命令:
uvicorn app:app --reload``
即可开始对话:
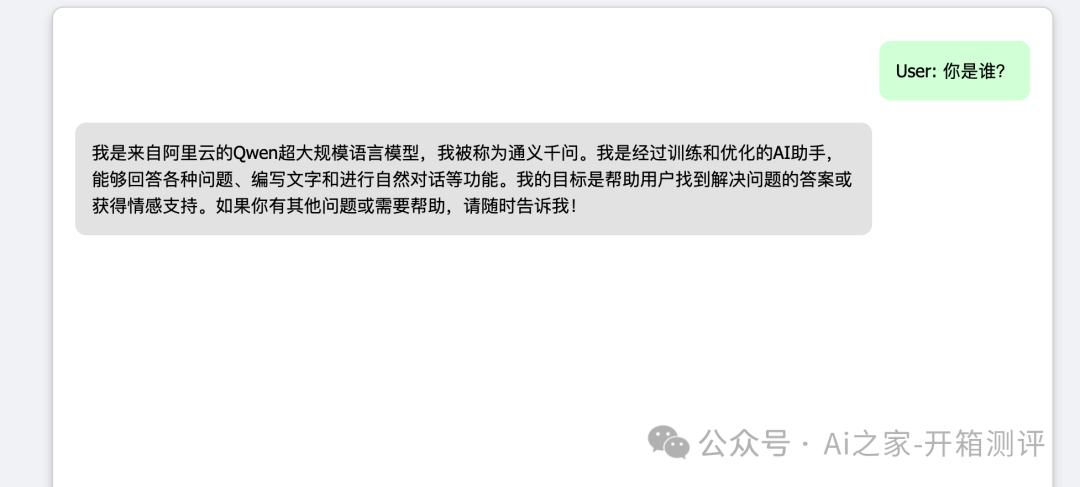
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 1293
1293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









