




from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import pandas as pd
data = load_wine()
x = data.data
y = data.target_names
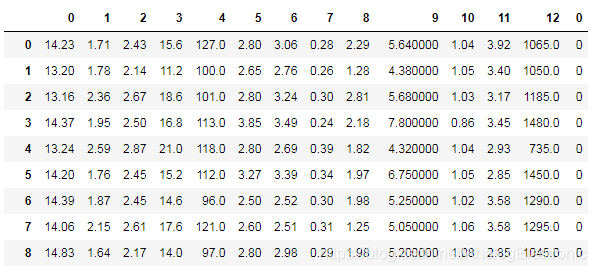
pd_data = pd.concat([pd.DataFrame(data.data),pd.DataFrame(data.target)],axis=1)
pd_data
X = pd_data.iloc[:,0:-1]
Y = pd_data.iloc[:,-1]
xtrain,xtest,ytrain,ytest = train_test_split(X,Y,test_size = 0.3,random_state=100)
mode_clf = tree.DecisionTreeClassifier()
mode_clf.fit(xtrain,ytrain)
mode_clf.score(xtest,ytest)
0.8333333333333334
mode_clf = tree.DecisionTreeClassifier(criterion="entropy")
mode_clf.fit(xtrain,ytrain)
mode_clf.score(xtest,ytest)
0.8518518518518519
mode_clf = tree.DecisionTreeClassifier(criterion="entropy",max_depth=3,random_state=1)
mode_clf.fit(xtrain,ytrain)
mode_clf.score(xtest,ytest)
0.8703703703703703
mode_clf = tree.DecisionTreeClassifier(criterion="entropy",
max_depth=3,
random_state=1,
min_samples_leaf = 4)
mode_clf.fit(xtrain,ytrain)
mode_clf.score(xtest,ytest)
0.8333333333333334
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
mode_clf = tree.DecisionTreeClassifier(random_state=1)
parameters = {'splitter':('best','random'),
'criterion':('gini','entropy'),
'max_depth':[*range(1,10)],
'min_samples_leaf':[*range(1,50,5)],
'min_samples_split':[*range(1,50,5)]}
gs_mode = GridSearchCV(mode_clf,parameters,cv=10,n_jobs=-1)
gs_mode.fit(xtrain,ytrain)
gs_mode.score(xtest,ytest)
0.8518518518518519
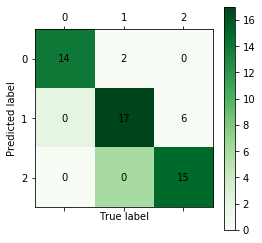
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix # 导入混淆矩阵函数
cm = confusion_matrix(y, yp) # 混淆矩阵
import matplotlib.pyplot as plt
plt.matshow(cm, cmap=plt.cm.Greens)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('Predicted label')
plt.xlabel('True label')
return plt
cm_plot(ytest,y_pridict).show()
##打印决策树
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
import graphviz
dot_data = tree.export_graphviz(mode_clf
,out_file = None
,feature_names= feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph
from sklearn.cluster import KMeans
import numpy as np
data = np.random.rand(200,2)
mode_KMeans = KMeans(n_clusters=9)
mode_KMeans.fit(data)
lable_pred = mode_KMeans.predict(data)
centroids = mode_KMeans.cluster_centers_
import matplotlib.pyplot as plt
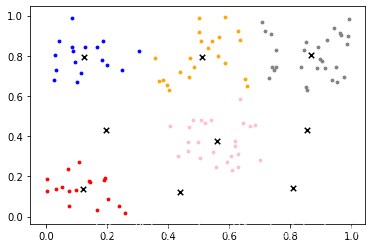
##聚类结果图形
color = ["red","pink","orange","gray","blue"]
fig, ax1 = plt.subplots(1)
for i in range(5):
ax1.scatter(data[lable_pred==i, 0], data[lable_pred==i, 1]
,marker='o' #点的形状
,s=8 #点的大小
,c=color[i]
)
ax1.scatter(centroids[:,0],centroids[:,1]
,marker="x"
,s=30
,c="black")
plt.show()
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
score_avg = silhouette_score(data,lable_pred)
score_avg
0.42415116148406695

















 2765
2765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









