




Background & Motivation
按文章中的说法,在此之前的 image-level 对比学习方法没有具体到下游任务上,比如:分类、检测和分割等,往往作为预训练模型提供给下游任务。
在“预训练-迁移”范式下,不论是有监督、无监督还是怎么样的学习方法,预训练后的模型作为迁移的起点,不只是基于特征重用这一出发点。当源域和目标域的特征差异较大时,预训练的模型更多是为目标域的任务提供一个合适的初始点(初始化),使训练更加平稳。
这种做法是次优的(sub-optimal),不如直接与下游任务对齐,用对比方法训练出一个用于检测的模型。
An obvious representation gap exists between image-level pretraining and the object-level bounding boxes of object detection.
与之前对比学习方法(MoCo)的区别是:
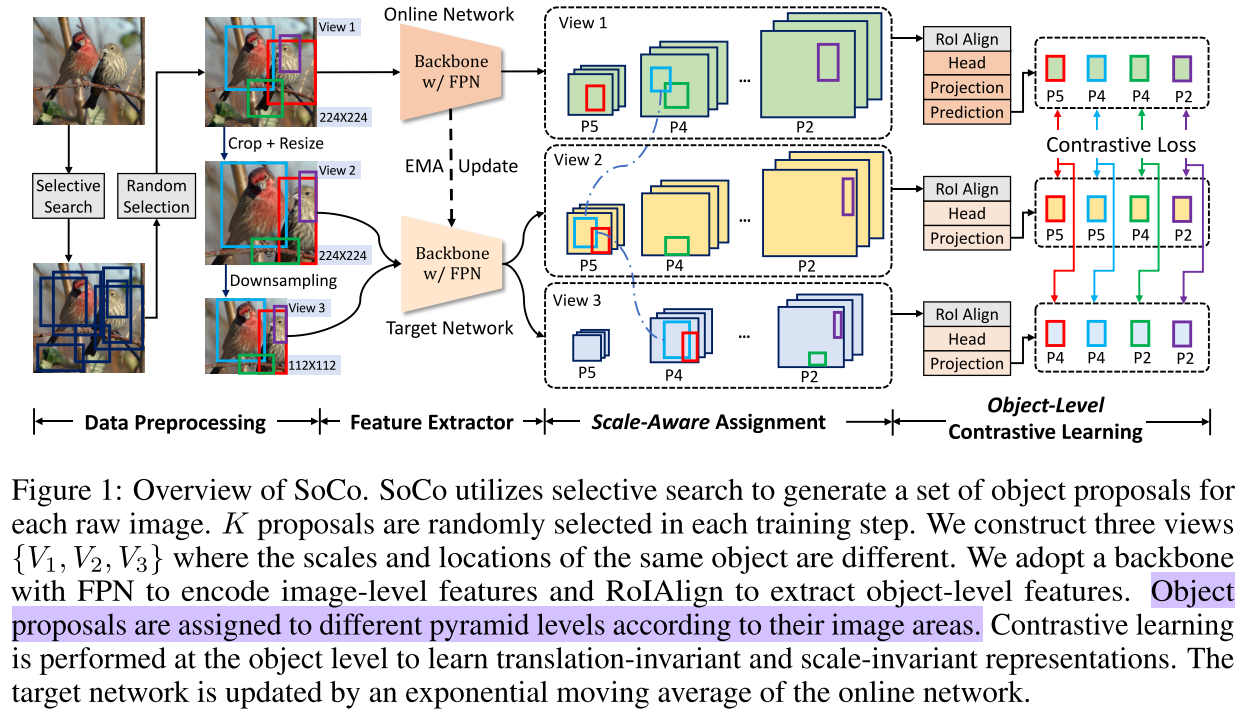
- 之前的做法是采用 image-level 的对比学习,而本文提出了一种 object-level 的对比学习方法;
- 之前的方法只能训练 backbone,而本文的方法可以同时训练 FPN、RPN 和 RoI Head 等模型中的其他模块,这样的话所有模块都可以被 well-initialized;
- 本文的方法可以学习到检测 object-level 所需要的平移不变性和尺度不变性,也即直接完成了“预训练-迁移”范式中的迁移,可以直接用在检测任务上;
- 同时受 SNIP 的启发,得到 proposal 后不在从统一大小的特征图上提取特征(如 Faster Rcnn 中的7*7),而是根据大小从 FPN 不同层的特征图上提取特征。
VADer [29], PixPro [10] and DenseCL [11] propose to learn pixel-level representations by matching point features of the same physical location under different views.
UP-DETR [31] proposes a pretext task named random query patch detection to pretrain DETR detector. Self-EMD [32] explores self-supervised representation learning for object detection without using Imagenet images.
Method
本文基于 Mask Rcnn,模型结构如下:
Training Schedule
将
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2208
2208



 到【灌水乐园】发言
到【灌水乐园】发言







