



摘要
将图像量化为离散表示一直是统一生成建模中的一个基本问题。主流的方法可以分为选择最佳匹配标记的确定性量化和从预测分布中抽样的随机量化。确定性量化存在严重的码本崩溃和推理阶段不对齐问题,而随机量化存在码本利用率较低和重建目标扰动问题。本文提出了一个正则化的向量量化框架,从两个角度有效缓解了上述问题。
一是先验分布正则化,它通过度量先验token分布和预测的token分布之间的差异,以避免码本崩溃和低码本利用率的问题。二是随机掩模正则化,它通过在量化过程中引入随机性,在推理阶段不对齐和重建目标扰动之间取得了良好的平衡。此外,本文设计了一个概率对比损失作为校准度量,从而减轻了重建目标扰动问题。大量的实验表明,本文所提出的量化框架在不同生成模型中始终优于流行的矢量量化方法,包括自回归模型和扩散模型。
Introduction
随着多模态图像合成和Transformer广泛应用,统一的数据建模引起了越来越多研究者的兴趣。针对不同数据模态的通用数据表示,离散表示学习发挥着重要的作用。向量量化模型(例如,VQ-VAE和VQ-GAN)通过将图像离散成token来学习通用的图像表示,由此,包括自回归模型和扩散模型在内的生成模型,可以用于学习图像生成中sequential token的依赖性,即tokenized image synthesis。
根据离散token的挑选方式,向量量化模型可以大致分为确定性量化和随机量化。典型的确定性量化为VQ-GAN通过Argmin或Argmax直接选择最佳匹配的token,而Gumbel-VQ这样的随机量化通过从预测的token分布中随机抽样token。确定性量化中的码本崩溃是一个众所周知的问题,即大部分codebook embeddings是无效的(值接近零)。推理阶段的不对齐指的是,推理阶段的token通常不是选择最佳匹配的token,而是随机抽样生成的,因此生成的效果不是很好。随机量化使用Gumbel-Softmax根据预测的token分布来采样token,从而避免码本崩溃,减轻推理不对齐问题。然而,虽然此时大多数codebook embeddings为有效的值,但只有一小部分用于向量量化,称为低码本利用率。此外,从一个分布中随机采样token后的重建图像,通常与原始图像不对齐,这种扰动导致了不真实的图像重建。
为解决上述问题,本文引入了一个正则化的量化框架。具体来说,为了缓解码本崩溃和码本利用率低的问题,引入先验分布正则化,即假定先验token分布为uniform distribution,用量化结果近似后验token分布,度量先验token分布和后验token分布之间的差异。通过最小化训练过程中的差异,量化过程将会使用所有的codebook embeddings,从而避免崩溃问题。
为了缓解推理不对齐和重构目标扰动的问题,引入随机掩模正则化进行平衡。随机掩模正则化随机掩盖了一定比例的区域进行随机量化,而保留了未掩模区域进行确定性量化。这为token的选择和量化的结果引入了不确定性,从而缩小与生成模型推理阶段随机选择的差距。对于随机量化区域的重构目标扰动问题,引入了一种基于对比损失的弹性图像重建,代替L1损失的完美图像重建,从而显著缓解了重建目标扰动。与PatchNCE相似,对比损失将相同空间位置的patch视为正样本对,其他视为负样本对。此外,randomly sampled tokens可能会在重建目标中引入不同尺度的扰动,本文设计概率对比损失(PCL)根据sampled token embedding和best-matching token embedding之间的差异调整不同区域的pulling force。
contributions
- 提出了一个正则化的量化框架,引入了一个先验分布的正则化,以避免码本崩溃和低码本利用率;
- 提出了一种随机掩模正则化,缓解推理阶段的不对齐问题;
- 设计了一种概率对比损失,以实现弹性图像重建,并自适应地缓解不同区域的目标扰动。
Preparation
GumbelVQ
Method
如图所示,我们的正则化量化框架结合了确定性量化和随机量化,由编码器E、解码器G和码本Z。给定一个输入图像X,利用编码器产生encoded vectors,再利用codebook实现离散化,得到相应的codebook embeddings。有了这样一套流程,可以将任意一张图像表示为一组indices。从而自回归模型/扩散模型可以用于学习indices的分布。
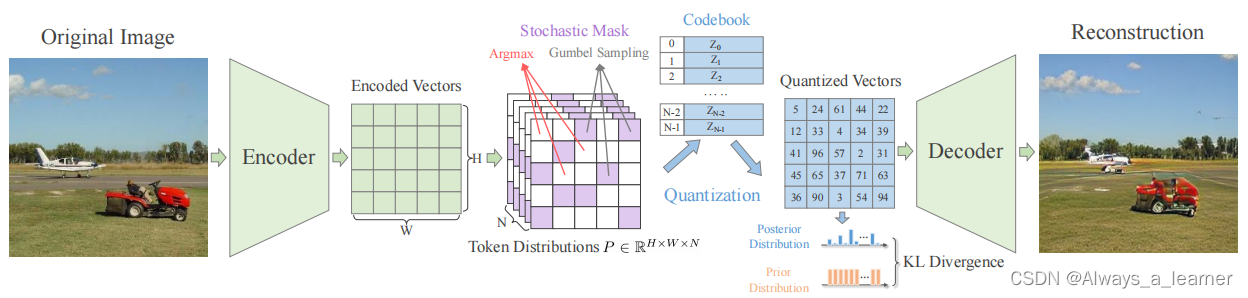
Prior Distribution Regularization
针对码本崩溃或低码本利用率的问题(即只有少量的码本嵌入是有效的或用于量化),本文提出了一个先验分布正则化来正则化向量量化过程。具体地说,假设indices有一个先验分布,理想情况下,先验分布应该是一个均匀的离散分布 P = [1/N,1/N,···,1/N]。在量化过程中,每个特征的预测量化结果可以用一个热独向量pi,i∈[1,H∗W]表示。因此,后验分布P可以用所有热独向量的平均值近似:

则先验的token分布与预测的token分布之间的差异可以通过KL散度来衡量:
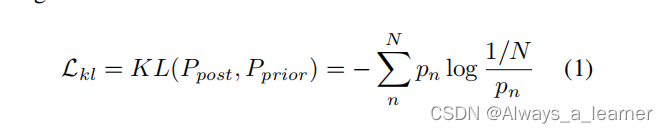
Stochastic Mask Regularization
为了在重建目标扰动和推理阶段不对齐之间达成良好的平衡,本文设计了一个随机掩模正则化结合/协调确定性量化和随机量化。具体来说,对于预测token的概率分布,随机设置一个掩模M,用“1”表示用Gumbel-softmax进行token采样的区域,用“0”表示用Argmax选择最佳匹配token的区域,重建目标如下:
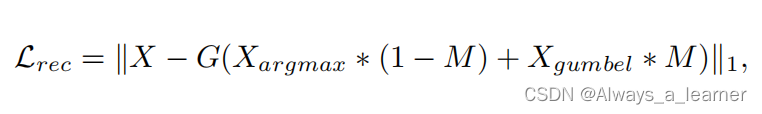
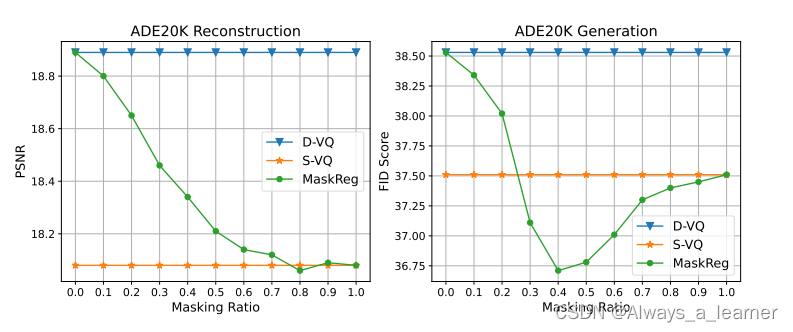
具体效果如下,在ADE20K数据集上,当M的比例取0.4时,生成效果最好。
Probabilistic Contrastive Loss
对于采用随机量化的图像区域,模型训练仍然受到由随机采样token引起的重建目标扰动。因此,我们提出了一种概率对比损失(PCL)来减轻这一现象。由于“扰动”来自于具有L1损失的原始图像完美重建,PCL将通过对比学习在随机量化区域实现了弹性图像重建。
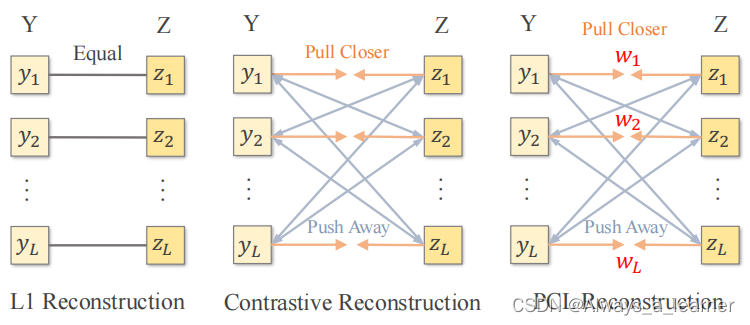
对比学习的目的不是实现完美的图像重建,而是通过拉近正对(positive pairs)并推开负对(negative pairs),从而最大化对应图像之间的互信息,如图所示。根据PatchNCE中的噪声对比估计框架,将PCL中相同空间位置的图像特征视为正对,其他特征视为负对。因此,用于图像重建的普通对比损失可以表述为:
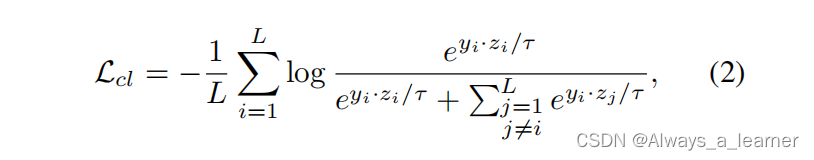
由于Gumbel抽样的随机性,抽样token往往与Argmax选择的最佳匹配标记表现出不同的差异。直观地说,与最佳匹配的token差异较大的采样token将产生更严重的目标扰动。因此,原始图像和重构图像之间的拉力应与扰动幅度自适应,以实现最优对比学习。
引入概率对比损失(PCL),采用加权参数wi根据token采样结果(即扰动幅度)调整不同特征的拉力,加权参数wi通过计算随机采样嵌入(用zs表示)与最佳匹配嵌入(用zq表示)之间的欧氏距离得到: wi =∥zs−zq∥_2^2 。然后,通过归一化加权参数{wi}调整正对的拉力,得到概率对比损失如下:
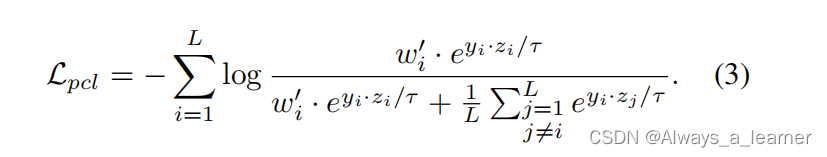
将负项用1/L进行平衡,否则负项与普通的对比损失相比会太大。



















 2180
2180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









