




 本文详细介绍了如何使用梯度下降法通过三次函数拟合正弦曲线,涉及矩阵形式的公式转换、关键步骤和Python代码实现。通过实例演示了如何构造矩阵、定义损失函数和梯度,以及迭代更新参数直至达到高精度。
本文详细介绍了如何使用梯度下降法通过三次函数拟合正弦曲线,涉及矩阵形式的公式转换、关键步骤和Python代码实现。通过实例演示了如何构造矩阵、定义损失函数和梯度,以及迭代更新参数直至达到高精度。
问题: 梯度下降法拟合正弦曲线
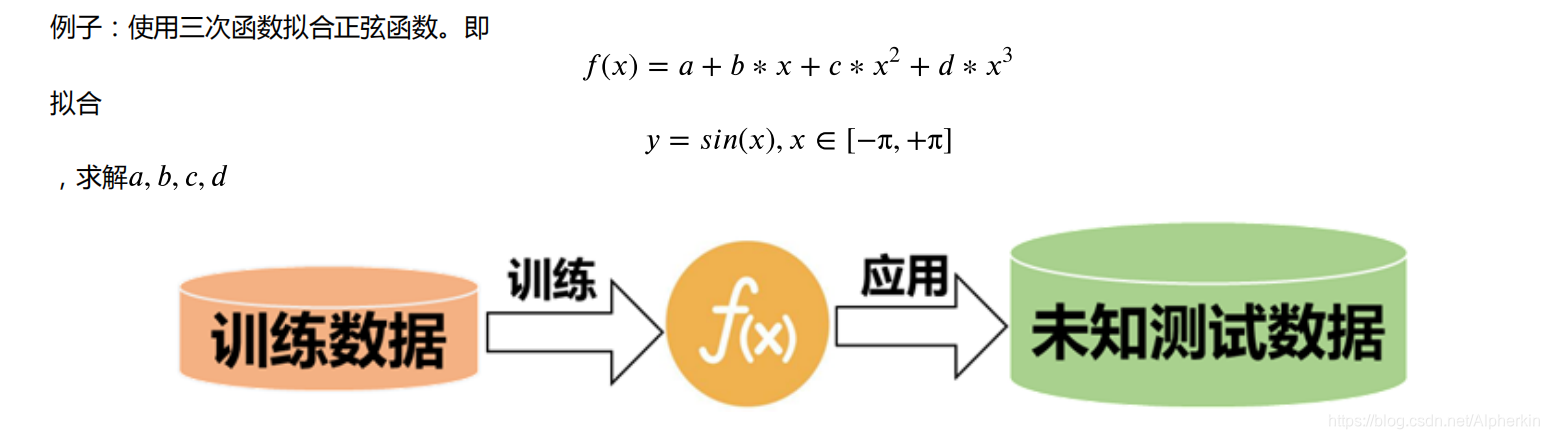
此处以三次函数为例,其他的函数拟合同理
1.梯度下降法原理
梯度下降相关公式
拟
合
的
函
数
:
h
(
x
)
=
∑
i
=
0
n
θ
i
x
i
\qquad\qquad拟合的函数:\quad h(x)=\displaystyle\sum_{i=0}^{n} θ_ix_i
拟合的函数:h(x)=i=0∑nθixi
损
失
函
数
:
J
(
θ
)
=
1
2
m
∑
i
=
1
m
(
y
(
i
)
−
h
θ
(
x
(
i
)
)
)
2
\qquad\qquad损失函数:\qquad J(θ)=\frac{1}{2m}\displaystyle\sum_{i=1}^{m}(y^{(i)}-h_θ(x^{(i)}))^2
损失函数:J(θ)=2m1i=1∑m(y(i)−hθ(x(i)))2
求
偏
导
:
∂
J
(
θ
)
∂
θ
j
=
1
m
∑
i
=
1
m
(
y
(
i
)
−
h
θ
(
x
(
i
)
)
)
x
j
(
i
)
\qquad\qquad求偏导: \qquad \quad \frac{\partial J(\theta)}{\partial θ_j}=\frac1m\displaystyle\sum_{i=1}^{m}(y^{(i)}-h_θ(x^{(i)}))x^{(i)}_j
求偏导:∂θj∂J(θ)=m1i=1∑m(y(i)−hθ(x(i)))xj(i)
迭 代 公 式 : θ j = θ j − α ∂ J ( θ ) ∂ θ j \qquad\qquad迭代公式: \qquad θ_j = θ_j - α\frac{\partial J(\theta)}{\partial θ_j} 迭代公式:θj=θj−α∂θj∂J(θ)
原理不再赘述, 请参考文档: 梯度下降原理
2.分析问题, 解题思路
把公式写成矩阵形式(嫌麻烦,这里只打出了部分) :
Θ = [ θ 1 θ 2 θ 3 θ 4 ] 4 × 1 X = [ x 0 ( 1 ) x 1 ( 1 ) x 2 ( 1 ) x 3 ( 1 ) x 0 ( 2 ) x 1 ( 2 ) x 2 ( 2 ) x 3 ( 2 ) ⋮ ⋮ ⋮ ⋮ x 0 ( m ) x 1 ( m ) x 2 ( m ) x 3 ( m ) ] m × 4 Y = [ y 1 y 2 ⋮ y m ] m × 1 Θ= \begin{bmatrix} θ_1 \\ θ_2 \\ θ_3 \\ θ_4 \end{bmatrix}_{4\times1} \qquad \qquad X=\begin{bmatrix} x^{(1)}_0 & x^{(1)}_1 & x^{(1)}_2 & x^{(1)}_3 \\ x^{(2)}_0 & x^{(2)}_1& x^{(2)}_2 & x^{(2)}_3 \\ \vdots & \vdots & \vdots & \vdots \\ x^{(m)}_0 & x^{(m)}_1 & x^{(m)}_2& x^{(m)}_3 \end{bmatrix}_{m\times4} \qquad \qquad Y=\begin{bmatrix} y_1 \\ y_2 \\ \vdots \\ y_m \end{bmatrix}_{m\times1} Θ=⎣⎢⎢⎡θ1θ2θ3θ4⎦⎥⎥⎤4×1X=⎣⎢⎢⎢⎢⎡x0(1)x0(2)⋮x0(m)x1(1)x1(2)⋮x1(m)x2(1)x2(2)⋮x2(m)x3(1)x3(2)⋮x3(m)⎦⎥⎥⎥⎥⎤m×4Y=⎣⎢⎢⎢⎡y1y2⋮ym⎦⎥⎥⎥⎤m×1
H ( X ) = X m × 4 Θ 4 × 1 = [ h ( x ( 1 ) ) h ( x ( 2 ) ) ⋮ h ( x ( m ) ) ] m × 1 D = H ( X ) − Y = [ h ( x ( 1 ) ) − y 1 h ( x ( 2 ) ) − y 2 ⋮ h ( x ( m ) ) − y m ] m × 1 H(X)=X_{m\times4}Θ_{4\times1}= \begin{bmatrix}h(x^{(1)}) \\ h(x^{(2)})\\ \vdots\\h(x^{(m)}) \end{bmatrix}_{m\times1} \qquad D = H(X)-Y =\begin{bmatrix}h(x^{(1)}) -y_1\\ h(x^{(2)})-y_2\\ \vdots\\ h(x^{(m)})-y_m \end{bmatrix}_{m\times1} H(X)=Xm×4Θ4×1=⎣⎢⎢⎢⎡h(x(1))h(x(2))⋮h(x(m))⎦⎥⎥⎥⎤m×1D=H(X)−Y=⎣⎢⎢⎢⎡h(x(1))−y1h(x(2))−y2⋮h(x(m))−ym⎦⎥⎥⎥⎤m×1
注:这个
x
2
(
i
)
x^{(i)}_2
x2(i)表示第 i 个样本值的 第2个分量, 大写通常指矩阵
代码需要用到的矩阵 :
拟
合
值
:
H
(
X
)
=
X
Θ
残
差
:
D
=
H
(
X
)
−
Y
拟合值: H(X)=XΘ \qquad \qquad \qquad \ \ 残差: D=H(X)-Y
拟合值:H(X)=XΘ 残差:D=H(X)−Y
损 失 函 数 : J ( Θ ) = 1 2 m D T D 梯 度 : ∂ J ( Θ ) ∂ Θ = 1 m X T D 损失函数: J(Θ)=\frac{1}{2m}D^TD \qquad \qquad 梯度: \frac{\partial J(Θ)}{\partial Θ}=\frac{1}{m}X^TD 损失函数:J(Θ)=2m1DTD梯度:∂Θ∂J(Θ)=m1XTD
迭 代 公 式 : Θ = Θ − α ∂ J ( Θ ) ∂ Θ 迭代公式: Θ=Θ-α\frac{\partial J(Θ)}{\partial Θ} 迭代公式:Θ=Θ−α∂Θ∂J(Θ)
注:待求向量
Θ
\Theta
Θ,设计矩阵
X
X
X,实际值向量
Y
Y
Y ,拟合值向量
H
(
X
)
H(X)
H(X),残差
D
D
D,学习率
α
α
α,总观测次数
m
m
m
把这些还有上面的名字记好咯,别后面认不得了。
详细的解题步骤及思路 :
先写一段废话, 都用Python了嘛, 处理数据就少用for循环, 多用用numpy, 要不然CPU跑起来可以烤萝卜吃了。
所以说就有了上面把梯度相关公式写成矩阵形式。
然后嘞, 我们用
Θ
4
×
1
\Theta_{4\times1}
Θ4×1 来对应储存 a, b, c, d 。
x
_
v
e
c
t
o
r
=
[
x
0
,
x
1
,
x
2
,
x
3
]
x\_vector = [x_0, x_1, x_2, x_3]
x_vector=[x0,x1,x2,x3] 来对应储存
x
0
,
x
,
x
2
,
x
3
x^0,x,x^2,x^3
x0,x,x2,x3,
然后我们一乘
(
x
_
v
e
c
t
o
r
)
Θ
(x\_vector) \Theta
(x_vector)Θ, 这不就是
h
(
x
)
=
a
+
b
x
+
c
x
2
+
d
x
3
h(x)=a+bx+cx^2+dx^3
h(x)=a+bx+cx2+dx3 嘛。 (感谢我神凯利)
废话就不多说了,下面正经走起。。。。
1.取样本点
先从区间(-π, π) 上取一些离散的样本点 x ( i ) x^{(i)} x(i),用以带入 h ( x ) = a + b x + c x 2 + d x 3 h(x)=a+bx+cx^2+dx^3 h(x)=a+bx+cx2+dx3 来逼近 y = s i n x y=sinx y=sinx
domain = np.arange(-np.pi, np.pi, 0.1) # 设置定义域
2.先创建用于输出数组的函数
输入一个离散点
x
(
i
)
x^{(i)}
x(i),对应运算后, 得到关于这个
x
(
i
)
x^{(i)}
x(i) 的四个分量(即一个样本的四个属性),
并储存在数组 x_vector =
[
x
0
(
i
)
,
x
1
(
i
)
,
x
2
(
i
)
,
x
3
(
i
)
]
[x^{(i)}_0, x^{(i)}_1, x^{(i)}_2, x^{(i)}_3]
[x0(i),x1(i),x2(i),x3(i)] 中, 该题中即为向量
[
(
x
(
i
)
)
0
,
x
(
i
)
,
(
x
(
i
)
)
2
,
(
x
(
i
)
)
3
]
[\ (x^{(i)})^0, \ x^{(i)}, \ (x^{(i)})^2, (x^{(i)})^3 \ ]
[ (x(i))0, x(i), (x(i))2,(x(i))3 ]
注 : 这一步很重要, 也是程序能扩展的核心代码
x_vector = lambda x: np.array([ x**0, x, x**2, x**3 ]) # 为简洁, 使用lambda表达式
3.创建列向量 Θ Θ Θ
用于对应储存待定常数a, b, c, d
直接用np.zeros()初始化这个数组 , 然后再用.reshape()给它转化成4x1的数组
这里的参数4是因为每个样本有4个属性, 即
[
x
0
(
i
)
,
x
1
(
i
)
,
x
2
(
i
)
,
x
3
(
i
)
]
[x^{(i)}_0, x^{(i)}_1, x^{(i)}_2, x^{(i)}_3]
[x0(i),x1(i),x2(i),x3(i)]
注 : 此步重要程度及原因同步骤2
theta = np.zeros(4).reshape(4, 1)
4.创建样本矩阵 X X X
把你第1步取好的离散点数组 domain 带入函数 x_vector ,你会得到一个 4×m 的数组,
你用.transpose()给它转一下,样本矩阵 x 就是m×4的了。
m = len(domain)
alpha = 0.01 # 学习率
error = 1 # 初始化拟合误差
x = hx(domain).transpose() # x的样本矩阵
y = np.sin(domain).reshape(m, 1) # 被拟合的函数
5. 定义损失函数和梯度函数
不用多说了吧,参照上面给的损失函数矩阵,对应乘就行了。
但是我还是要说一下,fun_error用来后面主程序中确定拟合精度用的,fun_error值越小,h(x)拟合sinx的效果越好
def fun_error(theta, x, y): # 定义损失函数
diff = np.dot(x, theta) - y # 残差 diff
return (1/2m)* np.dot(diff.transpose(), diff)
def fun_gradient(theta, x, y): # 定义梯度函数
diff = np.dot(x, theta) - y # 残差 diff
return (1/m) * np.dot(x.transpose(), diff)
6. 主程序:迭代 Θ \Theta Θ了
根据上面给的迭代公式算就行了。
while abs(error) >= 0.01: # 主程序: 梯度下降
error = fun_error(theta, x, y)
gradient = fun_gradient(theta, x, y)
theta = theta - alpha * gradient
7. 最后呢,画个图乐一下
毕竟对于老司机来说,图像更有视觉冲击力
print('所求参数向量θ为:\n', theta)
h = np.dot(x, theta)
plt.plot(domain, y, "*")
plt.plot(domain, h)
plt.show()
3. 完整的源代码
import numpy as np
import matplotlib.pyplot as plt
###############此段代码根据拟合题目修改######################
x_vector = lambda x: np.array([ x**0, x, x**2, x**3 ])
theta = np.zeros(4).reshape(4, 1) # 待求参数Θ 此处4为变量个数
domain = np.arange(-np.pi, np.pi, 0.1) # 设置定义域
#########################################################
m = len(domain)
alpha = 0.01 # 学习率
error = 1 # 初始化拟合误差
x = x_vector(domain).transpose() # x的样本矩阵
y = np.sin(domain).reshape(m, 1) # 被拟合的函数
def fun_error(theta, x, y): # 定义损失函数
diff = np.dot(x, theta) - y # 残差 diff
return (1/2m)* np.dot(diff.transpose(), diff)
def fun_gradient(theta, x, y): # 定义梯度函数
diff = np.dot(x, theta) - y # 残差 diff
return (1/m) * np.dot(x.transpose(), diff)
while abs(error) >= 0.01: # 主程序: 梯度下降
error = fun_error(theta, x, y)
gradient = fun_gradient(theta, x, y)
theta = theta - alpha * gradient
print('所求参数向量θ为:\n', theta)
h = np.dot(x, theta)
plt.plot(domain, y, "*")
plt.plot(domain, h)
plt.show()
4.关于题目的推广及总结
h ( x ) = a + b x + c x 2 + d x 3 + s i n x h(x)=a+bx+cx^2+dx^3+sinx h(x)=a+bx+cx2+dx3+sinx ,傅里叶拟合正弦函数或者拟合其他函数,改一改 x _ v e c t o r x\_vector x_vector, Θ \Theta Θ 等参数(见下列代码块)就行了。
x_vector = lambda x: np.array([ x**0, x, x**2, x**3, np.sin(x) ])
theta = np.zeros(5).reshape(5, 1) # 待求参数Θ
x_vector = lambda x: np.array([ x**0, np.sin(x), np.cos(x), np.sin(2*x), np.cos(2*x) ])
theta = np.zeros(5).reshape(5, 1) # 待求参数Θ
用数组或者矩阵来处理梯度下降这个问题简洁且快速。
5.写在最后的话
敲打了一下午公式,排版了一晚上,话有点多有点啰嗦,看完一遍感觉有思路点乱可以结合目录再看一遍,要还是感觉乱还请多多包涵。观众老爷给个三连吧。
本篇参考文章,特此感谢!
参考文档:
https://blog.youkuaiyun.com/yhao2014/article/details/51554910
https://blog.youkuaiyun.com/lilyth_lilyth/article/details/8973972
https://blog.youkuaiyun.com/asahinokawa/article/details/80846439


















 334
334










 到【灌水乐园】发言
到【灌水乐园】发言







