




第12章
NLP常见任务

词典生成
在进行NLP任务时,因为输入的是文本序列。文本是由多个词构成的,词是有意义的最小单元,所以在NLP任务中,一般处理的基本单元是词。NLP模型处理的最小输入输出单元叫做Token。
特殊的Token


BPE算法原理:
BPE通过迭代合并最高频的字节对来构建词汇表:
# BPE算法示例
初始词汇:所有字符
统计所有相邻字符对频率
循环直到达到vocab_size:
合并最高频的字符对
更新词汇表
Token编码
原文链接
词嵌入(Word Embedding)是一种将Token编码成低维、稠密向量的技术。词嵌入的目标是通过学习,将语义相似的词映射到空间中相近的位置上。这里的词指的就是Token。
Google在2013年提出的Word2Vec,是最著名的词嵌入实验。Word2Vec用了两种训练方法,分别是CBOW(Continuous Bag of Words)和 Skip-gram。
这两种训练方法的目标相同:从大量无标签文本中学习高质量的词向量,这些向量能够捕捉词语的语义和语法信息。但它们的实现方式和侧重点有所不同。
核心思想:
两者都基于分布式假设:一个词的语义由其出现的上下文决定。
它们都是浅层神经网络模型。
它们都采用无监督学习,只需要大量的原始文本。
CBOW
是一种通过上下文预测中心词的词向量训练模型。其核心思想是用上下文词向量的平均值预测中心词。这里的词指的就是Token。
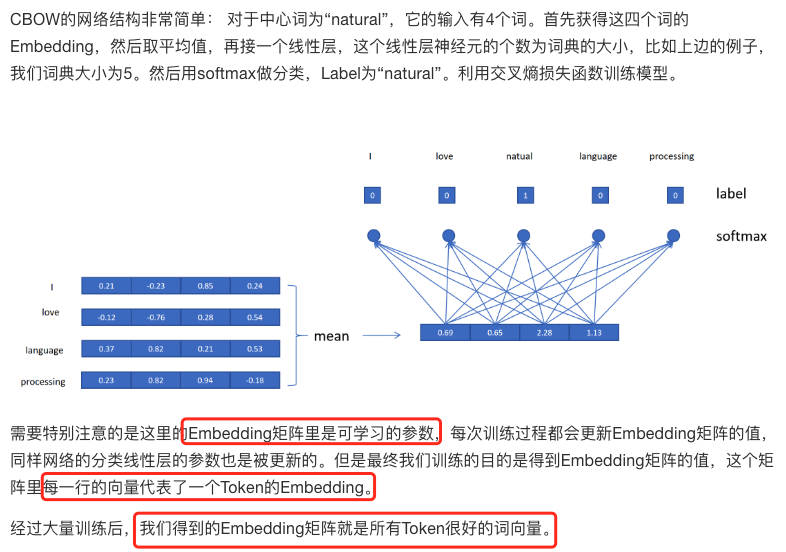
Skip-gram
Skip-gram与CBOW刚好相反,它是利用中心词来预测上下文的词。Skip-gram模型的输入只有一个Token,所以不需要进行多Token Embedding的平均,直接用输入Token的Embedding作为输入,然后和CBOW一样接一个线性分类头,预测输出Token。经过大量训练后也可以得到很好的Embedding矩阵。
值得注意的是在训练CBOW和Skip-gram模型时,需要平衡常见词和罕见词的影响。可以对常见词进行下采样,或者对罕见词进行上采样。
语言模型采样
Beam Search



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









