




 本文深入讲解双向链表的实现与操作,包括创建、插入、删除等核心功能,并对比顺序表的特点,探讨各自适用场景。
本文深入讲解双向链表的实现与操作,包括创建、插入、删除等核心功能,并对比顺序表的特点,探讨各自适用场景。

请回答数据结构【双向链表】
1. Intro
回顾一下之前在单链表中提到的8种链表结构,其中可以互相结合
| 单向 | 双向 |
|---|---|
| 带头 | 不带头 |
| 循环 | 不循环 |
而我们这章主要展开的是双向链表
| 单链表 | 双向带头链表 |
|---|---|
| 不带头 | 带头 |
| 不循环 | 循环 |
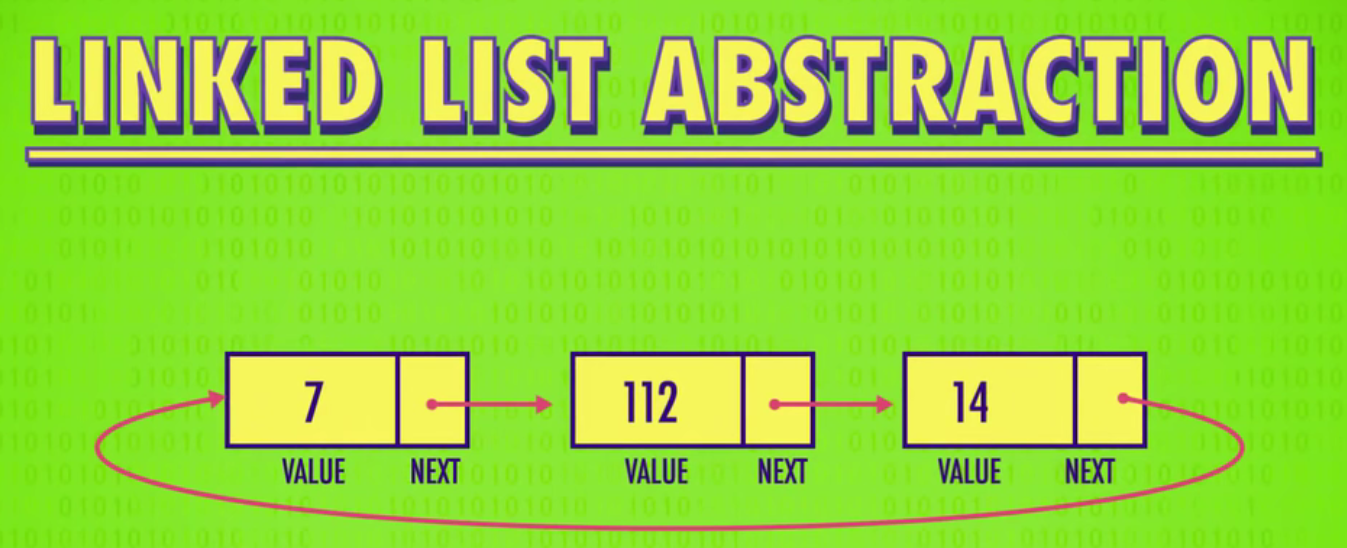
图片来源于Crash Course Computer Science
双向带头链表,虽然结构复杂但是操作反而简单,具有结构优势
2. 实现双向链表
| 文件名 | 功能作用 |
|---|---|
| DList.c | 创建双向链表,单链表主要函数的实现 |
| DList.h | 声明用头文件,实现每个函数的声明,用来引用 |
| test.c | 测试运行文件,主函数在这里 |
2.1 用结构体创建双向链表
typedef int LTDataType;
typedef struct ListNode
{
LTDataType data;
struct ListNode* next;
struct ListNode* prev;
}LTNode;
双向链表和单链表一个很大的区别就是有一个哨兵位节点,有人说哨兵位头节点可以用来存储数据,这个数据就是链表长度,但是实际上这是不好的,因为你要考虑数据的类型,因为所有的数据类型都是一样的,倘若你今天typedef了的是char类型、指针类型或者是其他自定义的类型,那么不是就存不了值了吗,所以当然不太好,是有局限性的,如果说了是存int类型或者是size_t类型等长整型那还好说
2.2 BuyLTNode
获得一个节点
LTNode* BuyLTNode(LTDataType x)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL)
{
printf("malloc fail\n");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
newnode->prev = NULL;
return newnode;
}
2.3 ListInit
void ListInit(LTNode** pphead)
{
assert(pphead);
*pphead = BuyLTNode(0);
(*pphead)->next = *pphead;
(*pphead)->prev = *pphead;
}
或者是,为了统一一下,我们全部采取一级指针,甚至不传参,直接我们改成返回值的方法,就统一了不用二级指针
LTNode* ListInit()
{
LTNode* phead = BuyLTNode(0);
phead->next = phead;
phead->prev = phead;
return phead;
}
2.4 ListPushBack
双向链表的结构优势就是尾插的时候不再用考虑头节点了,而且效率极高
还有一个问题,为什么单链表要传二级指针,双向链表不用,这是因为双向链表中我们没有改变*phead,而是改变了哨兵位的结构体,那传结构体地址(指针)就可以了
而单链表是传结构体指针的指针 ,所以说倘若双向链表一开始不是头结点的话,那么也要传二级指针
void ListPushBack(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* tail = phead->prev;
LTNode* newnode = BuyLTNode(x);
tail->next = newnode;
newnode->prev = tail;
newnode->next = phead;
phead->prev = newnode;
}
当有了insert之后可以简化
ListInsert(phead, x);
2.5 ListPopBack
尾删也很简单只要改变指向哨兵指向 就可以
void ListPopBack(LTNode* phead)
{
assert(phead);//avoid vacancy
assert(phead->next != phead);
LTNode* tail = phead->prev;
LTNode* tailPrev = tail->prev;
free(tail);
tail = NULL;
tailPrev->next = phead;
phead->prev = tailPrev;
}
2.6 ListPrint
打印输出,还是用了cout修改了一下
void ListPrint(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;//不应该是从头开始
while (cur != phead)//现在遍历要走到phead结束,而不是空位置为止
{
cout<<cur->data<<"->"
}
printf("\n");
}
2.7 ListFind
实现查找功能
LTNode* ListFind(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
2.8 ListInsert
设计一个带头双向循环链表就非常好用,不用排除很多情况,加入要写的话,上来应该先写ListInsert和ListErase,然后头插尾插,头删尾删可以复用,直接就写好了
双向循环链表的插入
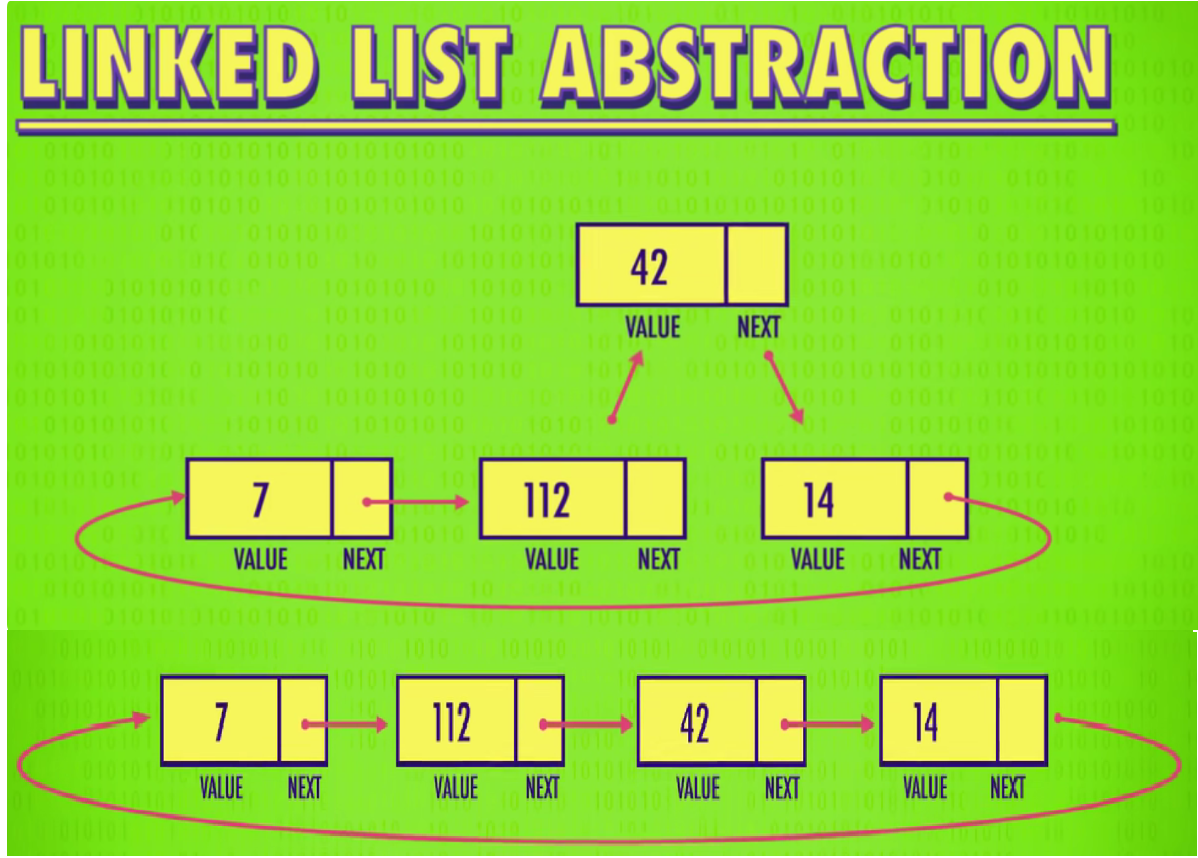
图片来源于Crash Course Computer Science
void ListInsert(LTNode* pos, LTDataType x)
{
assert(pos);
/*LTNode* newnode = BuyLTNode(x);
pos->prev->next = newnode;
newnode->prev = pos->prev;
pos->prev = newnode;
newnode->next = pos;*///代码前后顺序易出错
LTNode* newnode = BuyLTNode(x);
LTNode* posPrev = pos->prev;
//代码前后顺序随便
newnode->next = pos;
pos->prev = newnode;
posPrev->next = newnode;
newnode->prev = posPrev;
}
注意这是在某位置前插
2.9 ListPushFront
直接复用
void ListPushFront(LTNode* phead, LTDataType x)
{
assert(phead);
ListInsert(phead->next, x);
}
2.10 ListErase
void ListErase(LTNode* pos)
{
assert(pos);
LTNode* prev=pos->prev;
LTNode* next = pos->next;
delete pos;
pos =nullptr;
prev->next = next;
next->prev = prev;
}
不要传入哨兵位,因为这相当于在自断手臂,相当于phead变成了野指针,后面就不能使用plist了
还有一点是,注意这里的pos置为nullptr实际上只是一份拷贝,没有对实参影响,这里我们如果想要对pos处理,其实可以在函数外去置空,不过即使pos不置空,其实也没问题。但是强行要置空pos只能传二级指针,这样反而显得冗余,只要不去访问就可以了
LTNode* pos = ListFind(pList, 3); if (pos) { ListErase(pos); pos = NULL; }
2.11 ListDestroy
void ListDestory(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
LTNode* next = cur->next;
//ListErase(cur);
free(cur);
cur = next;
}
free(phead);
//phead = NULL;
}
3. 双向带头链表 V.S. 顺序表
| 优缺点\表名 | 顺序表 | 链表(双向带头链表) |
|---|---|---|
| 优点 | 1. 物理空间是连续的,方便按下标进行随机访问 | 1. 按需申请内存,需要存储一个数据,就申请一块内存,不会造成过多的空间浪费,按需释放空间 |
| 2. cpu高速缓存命中率比较高(局部性原理) | 2.任意位置节点插入删除效率高O(1), | |
| 缺点 | 1. 空间不够要增容,扩容的本身有一定消耗,扩容机制也存在一定的资源浪费 | 1. 不支持下标的随机访问,有些算法不支持如排序,二分查找 |
| 2. 头部或者中间插入或者删除数据,需要挪动数据,效率低,O(N) | 2. 由于本身来说空间是不连续存储的,所以访问数据时,在缓存,命中,不在缓存,不命中,造成低命中,缓存污染 | |
| 假设栗子 | QQ发信息消息记录,每次信息记录时后发的显示在最下面,在数据存储中相当于实现一个头插,因此不可能用顺序表,太慢了,每次都要移动数据 |
那么cpu就会去找缓存,若是在缓存叫命中,直接访问,如果不在就叫不命中,明显连续的空间是会容易命中的,然而链表由于空间不连续,所以命中率低,甚至把不要的东西读入缓存,产生了缓存污染,所以还有这个点
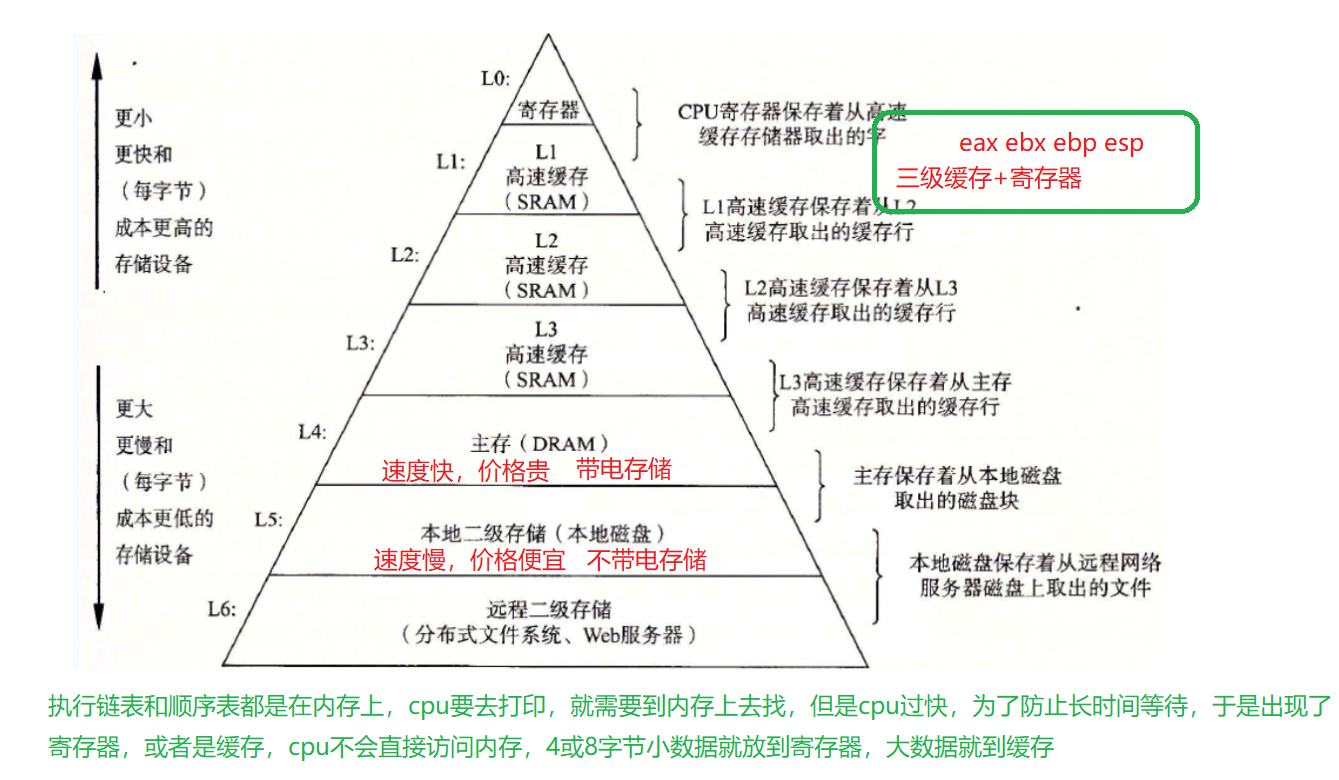
两个数据结构,是相辅相成的,互弥补对方的缺点,需要用谁存数据,具体是看场景
双向链表的模拟实现代码可至我的gitee库中查看https://gitee.com/allen9012/c-language/tree/master/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/%E5%8F%8C%E5%90%91%E9%93%BE%E8%A1%A81)
注:部分图片来源于Crash Course Computer Science,如有侵权请联系我删除


















 1279
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











