




 本文详细介绍了如何使用百度智能云实现语音控制,包括语音识别、文件转码、API调用及语音生成,重点讲解了Python SDK的安装和关键步骤。
本文详细介绍了如何使用百度智能云实现语音控制,包括语音识别、文件转码、API调用及语音生成,重点讲解了Python SDK的安装和关键步骤。
这次的目标是继上次的健康时报打卡机器人,现在要实现语音控制。
一、部署工作
使用的是百度智能云:具体操作文档https://ai.baidu.com/ai-doc/SPEECH/Gk38lyqzo
入门者看着新手指南就可以了。
之后进入百度智能云登录账号后领取可以实现语音识别的额度:
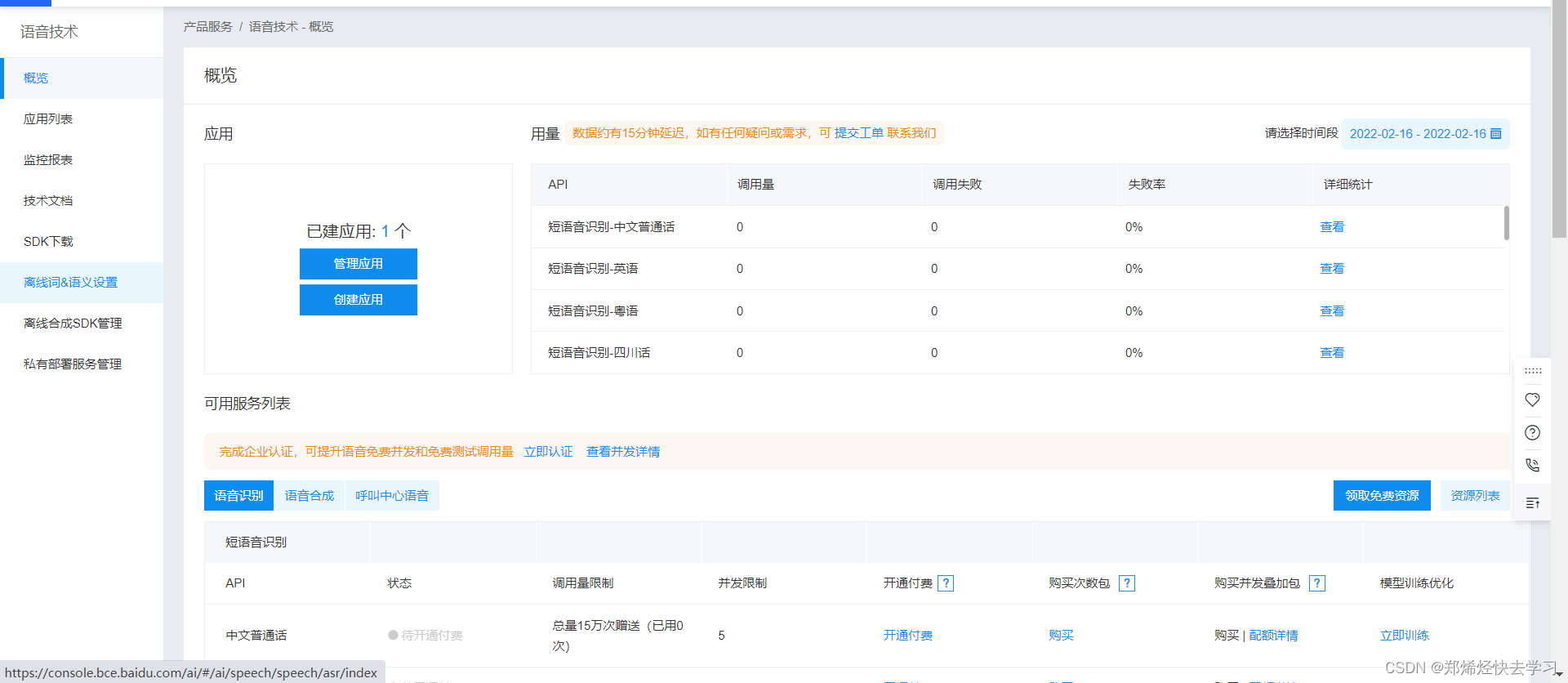 之后点击创建任务:
之后点击创建任务:
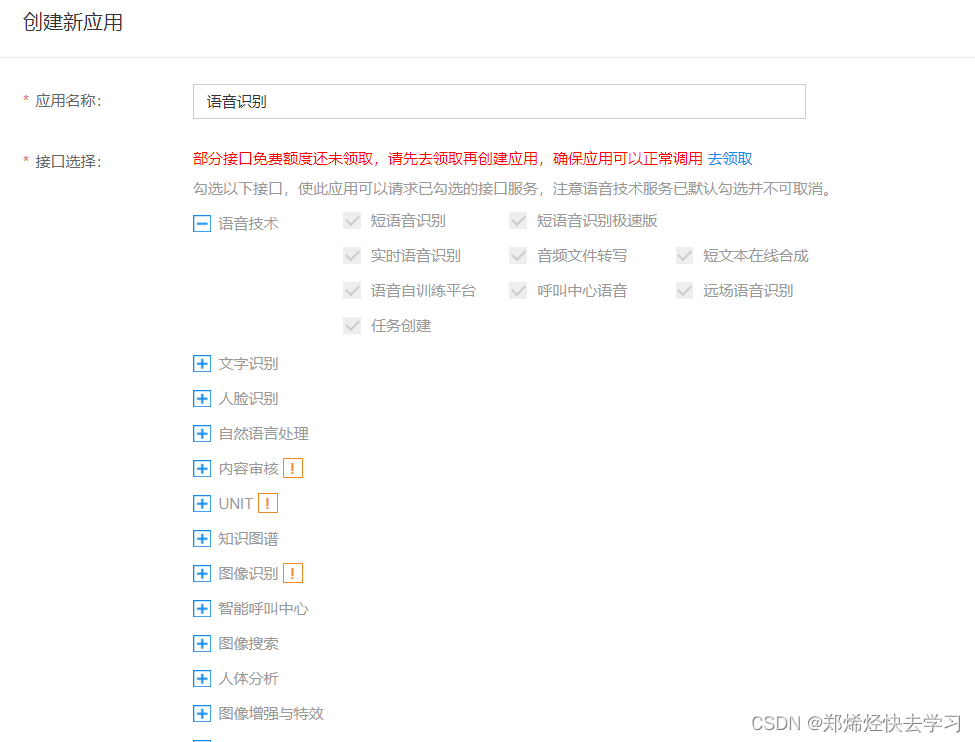
之后就获取了语音识别的AppID、API Key、Secret Key:
 点击隔壁的技术文档:
点击隔壁的技术文档:
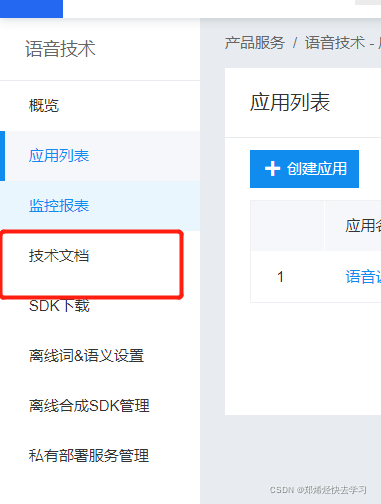
之后点击下载SDK:
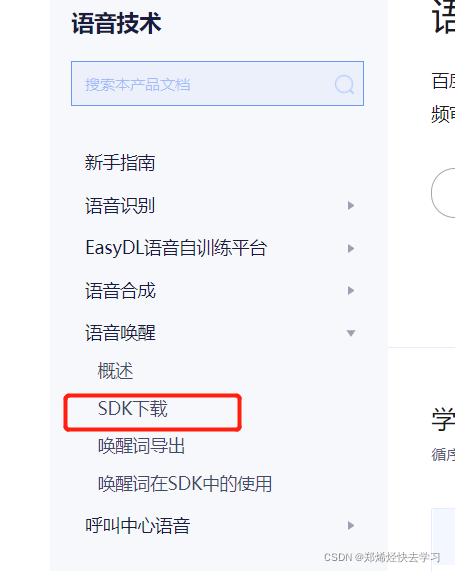
下载Python SDK:
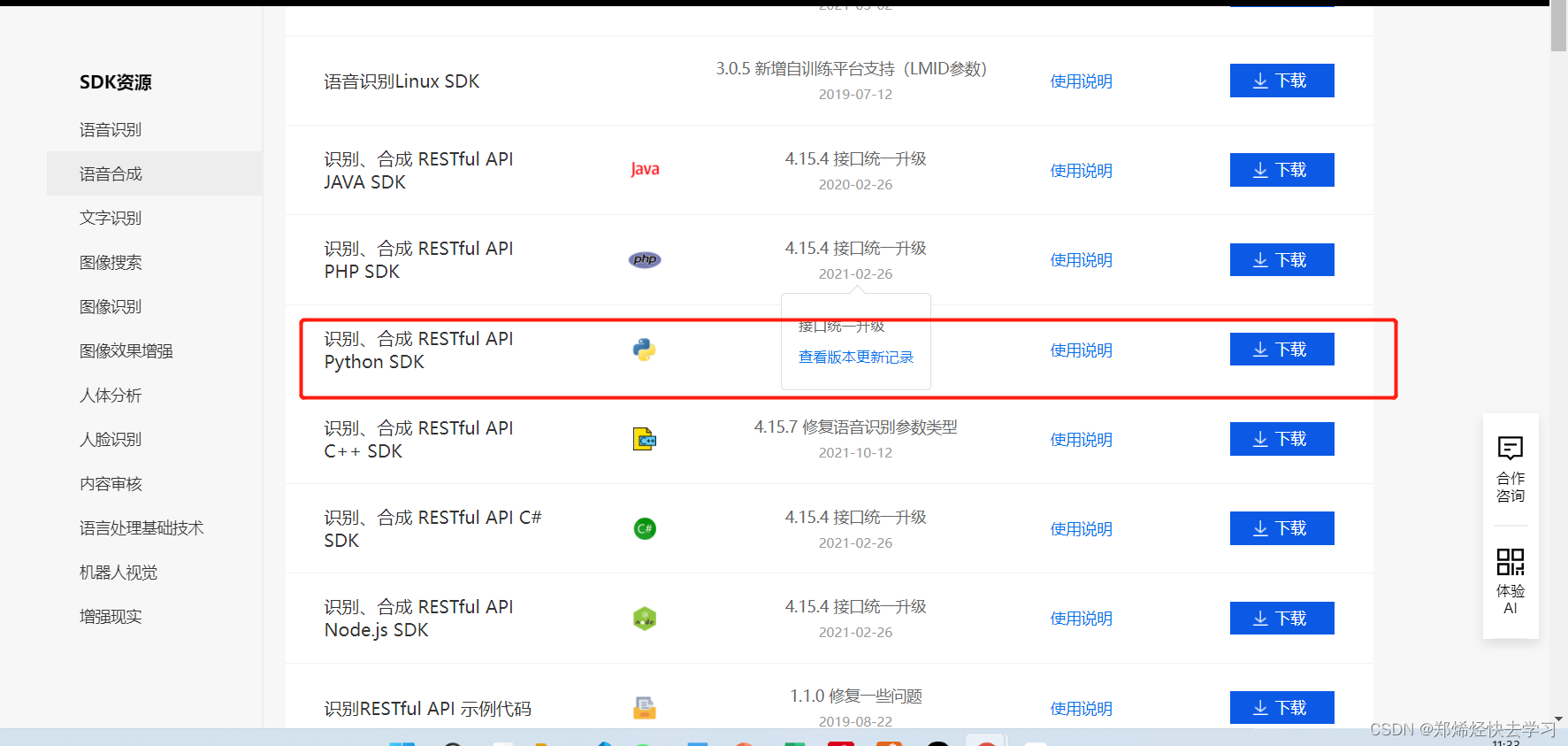
注意看一下使用说明:
 之后就开始入门吧。
之后就开始入门吧。
二、语音识别

安装Python SDK:
pip install baidu-api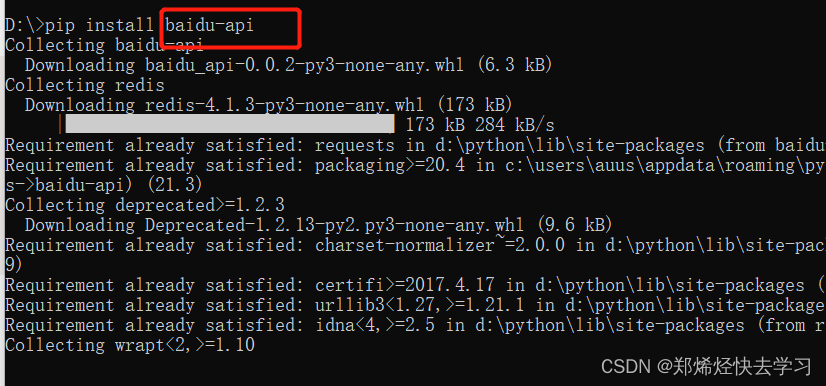
或者在Pycharm中找到baidu-aip进行下载:
之后打开pycharm,新建ApiSpeech:参考如下代码
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)按照技术文档进行操作,要对一段语音文件进行识别:
需要注意的是下面需要调用ffmpeg,在上次的文章中我已经下载完成了:
在cmd中输入ffmpeg表示配置成功。
开启pycharm,在pycharm中的用法如下:
ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s.pcm第一个%s表示原始文件
第二个%s也表示原始文件,但是它加了后缀.pcm
在请求时需要指定一个pcm格式的文件,而技术文档给的是如下的代码:
# 读取文件
def get_file_content(filePath):
with open(filePath, 'rb')as fp:
return fp.read()
# 识别本地文件
a = client.asr(get_file_content('录音.pcm'), 'pcm', 16000, {'dev_pid': 1537})
print(a)看看它需要的参数有如下:

有参数表我们可得知需要格式为pcm、wav或者amr的格式。
如果我单纯只用电脑录音,只会让它报错:
Traceback (most recent call last): File "D:/PythonvideoTest/mian.py
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











