






2025深度学习发论文&模型涨点之——GAN
生成对抗网络(GAN)是一种深度学习模型,由生成器(Generator)和判别器(Discriminator)两个神经网络组成,通过对抗训练生成与真实数据高度相似的新数据。
-
生成器(G):接收随机噪声作为输入,生成假数据,目标是生成与真实数据难以区分的样本。
-
判别器(D):接收真实数据和生成器生成的假数据,判断其是否为真实数据,目标是准确区分真假。
小编整理了一些GAN【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学
回复“GAN”即可全部领取
论文精选
论文1:
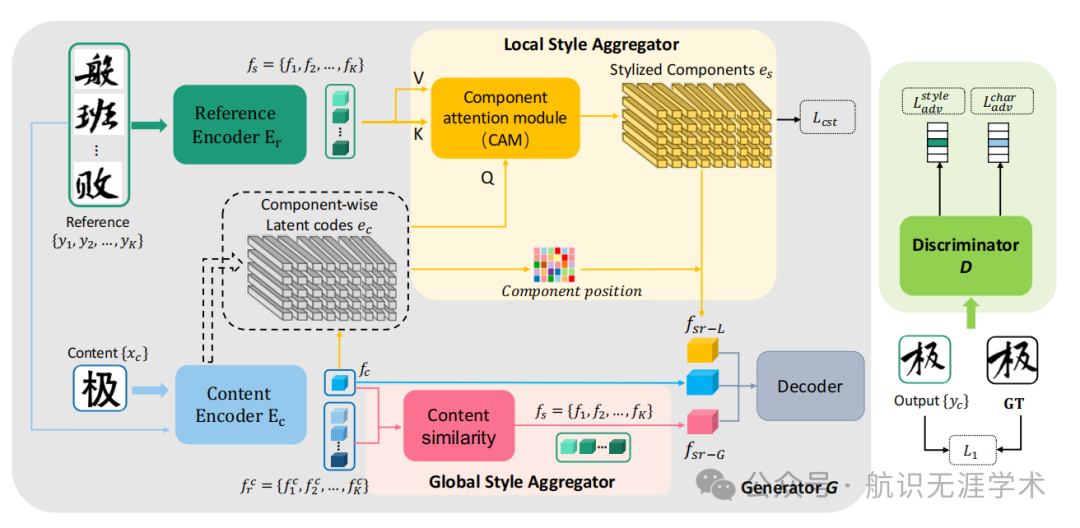
Few shot font generation via transferring similarity guided global style and quantization local style
基于相似性引导的全局风格和量化局部风格的少样本字体生成
方法
-
全局风格聚合器(GSA):通过计算目标字符与参考样本之间的内容特征距离,获得相似性分数,并将其作为权重聚合全局风格特征。
局部风格聚合器(LSA):采用交叉注意力机制,将参考字符的风格特征转移到自学习的离散潜在代码(即字符组件)上,无需手动定义组件。
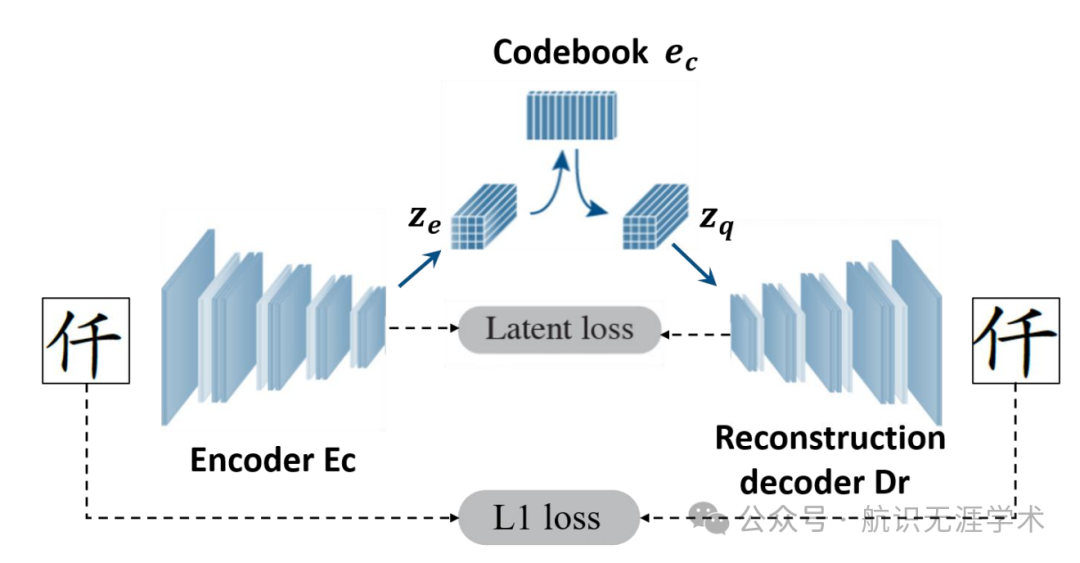
内容编码器:利用预训练的向量量化-变分自编码器(VQ-VAE)将字符分解为离散的组件表示。
生成器和判别器:生成器结合内容特征、局部风格和全局风格进行目标字符的生成,判别器用于区分真假图像并分类内容和风格。
创新点
-
全局与局部风格结合:同时利用全局风格和局部风格进行字体生成,全局风格控制字体的整体特性(如字符大小、笔画间距),局部风格捕捉字体的细节(如笔画形状、装饰性)。实验结果表明,结合全局和局部风格的方法在少样本字体生成任务中优于仅使用全局风格或局部风格的方法。
自学习组件表示:通过VQ-VAE自动学习字符的组件表示,无需手动定义笔画或部首,提高了方法的通用性和效率。在中文字符生成中,使用100个组件即可有效表示字符结构,而在英文字符生成中,仅需15个组件即可获得良好结果。
风格对比损失:提出了一种风格对比损失函数,用于无监督地学习组件级别的风格,使模型能够更好地从有限的参考样本中提取和转移风格特征,提升了生成字体的质量和多样性。
论文2:
Raindrop Clarity: A Dual-Focused Dataset for Day and Night Raindrop Removal
Raindrop Clarity:一个针对白天和夜晚雨滴去除的双焦点数据集
方法
-
数据收集:使用多种设备(包括相机和手机)在不同条件下(白天和夜晚)拍摄带有雨滴的图像,包括雨滴焦点和背景焦点两种情况。
数据标注:对于每张带有雨滴的图像,提供对应的模糊背景图像和清晰背景图像,形成成对或成三的数据集。
数据多样性:数据集涵盖了不同的场景(如城市、乡村、校园等)、不同的光照条件(白天和夜晚)以及不同的雨滴大小、形状和分布密度。
创新点
-
双焦点数据集:首次提出了包含雨滴焦点和背景焦点的双焦点数据集,填补了现有数据集在雨滴焦点图像和夜晚雨滴图像方面的空白。该数据集包含15,186张高质量的图像对和三元组,其中5,442张为白天图像,9,744张为夜晚图像。
多样化场景和条件:数据集涵盖了多种场景和光照条件,包括白天和夜晚,以及不同的雨滴大小、形状和分布密度,为雨滴去除算法的研究提供了更全面和具有挑战性的数据资源。
性能提升:通过在该数据集上测试现有的雨滴去除算法,发现现有方法在处理雨滴焦点和夜晚雨滴图像时存在局限性,从而揭示了雨滴去除领域中尚未解决的问题,为未来的研究提供了方向。例如,在白天雨滴焦点图像的去除任务中,现有的最佳方法(Restormer)的PSNR为26.08,SSIM为0.748,而该数据集上的平均PSNR为25.52,SSIM为0.734,表明现有方法仍有改进空间。
论文3:
Scalable Multi-Temporal Remote Sensing Change Data Generation via Simulating Stochastic Change Process
通过模拟随机变化过程实现可扩展的多时相遥感变化数据生成
方法
-
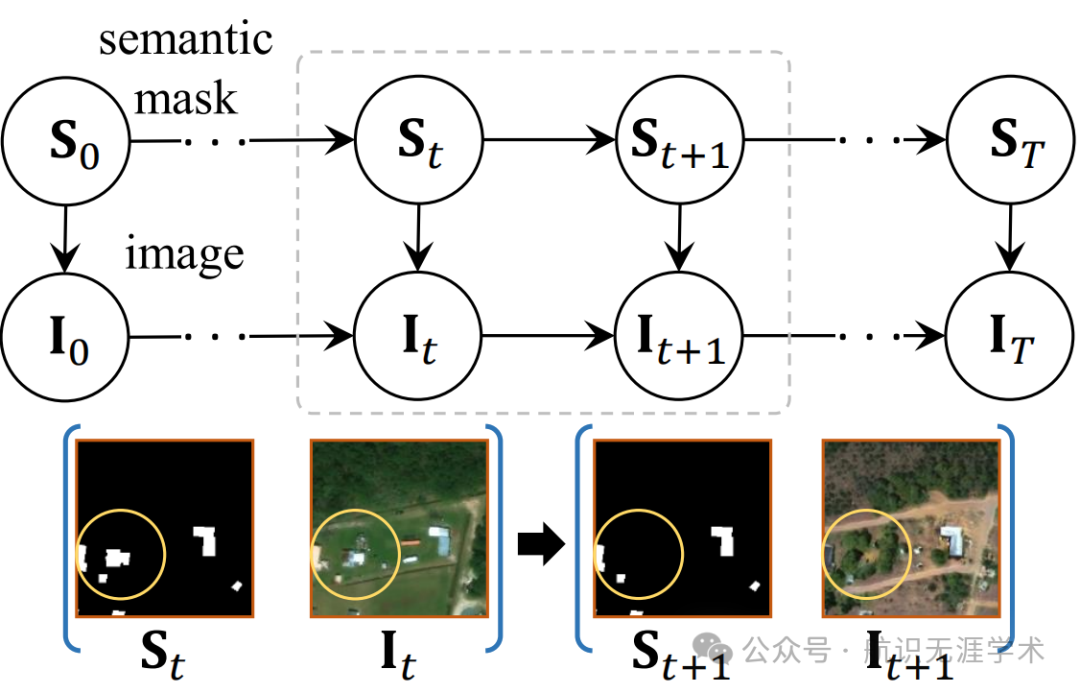
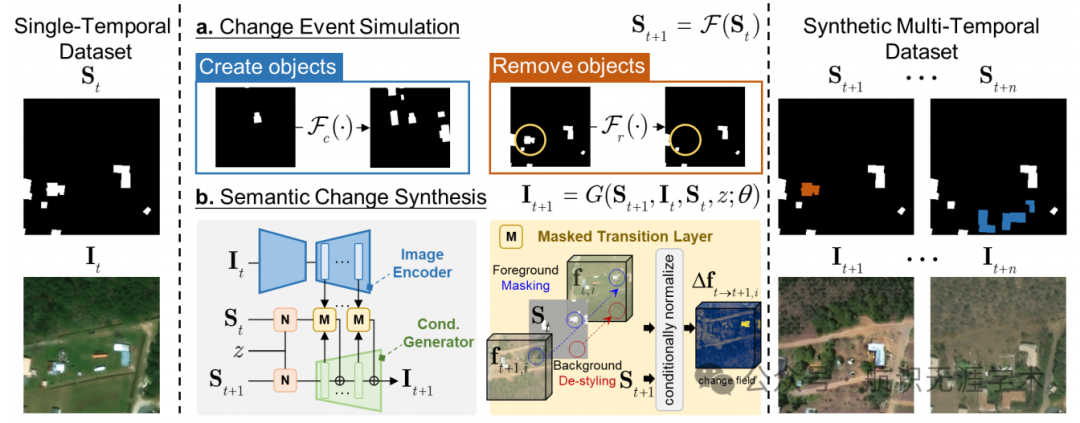
生成概率变化模型(GPCM):将随机变化过程建模为概率图模型,将图像和语义掩膜视为随机变量,通过模拟语义状态的马尔可夫转移来描述变化过程。
变化事件模拟:设计了两种学习无关的函数,分别用于在语义掩膜中创建和移除对象,以模拟真实世界中的新对象建设和现有对象破坏事件。
语义变化合成:提出了一个基于生成对抗网络(GAN)的深度生成模型,通过图像编码器、条件解码器和掩膜转换层,将预事件图像和语义掩膜逐步转化为后事件图像。

创新点
-
可扩展性:通过从单时相图像和语义掩膜生成多时相变化数据,解决了大规模多时相遥感变化数据收集和标注的困难,降低了数据获取成本,提高了数据生成的可扩展性。
可控性:能够生成具有可控对象属性(如尺度、位置、方向)和变化事件的多时相变化数据,为研究者提供了灵活的数据生成方式,可以针对特定的研究需求定制变化数据。
性能提升:在真实世界的变化数据集上进行预训练的实验表明,使用该方法生成的合成变化数据预训练的变化检测器具有更好的迁移性,能够显著提高在真实世界数据集上的性能。例如,在LEVIR-CD数据集上,使用该方法预训练的变化检测器(ChangeStar)的F1分数达到了91.1%,比使用ImageNet预训练的模型提高了0.6%;在S2Looking数据集上,F1分数提高了0.8%。

论文4:
ZGAN: An Outlier-focused Generative Adversarial Network for Realistic Synthetic Data Generation
ZGAN:一种专注于生成异常值的生成对抗网络,用于生成逼真的合成数据
方法
-
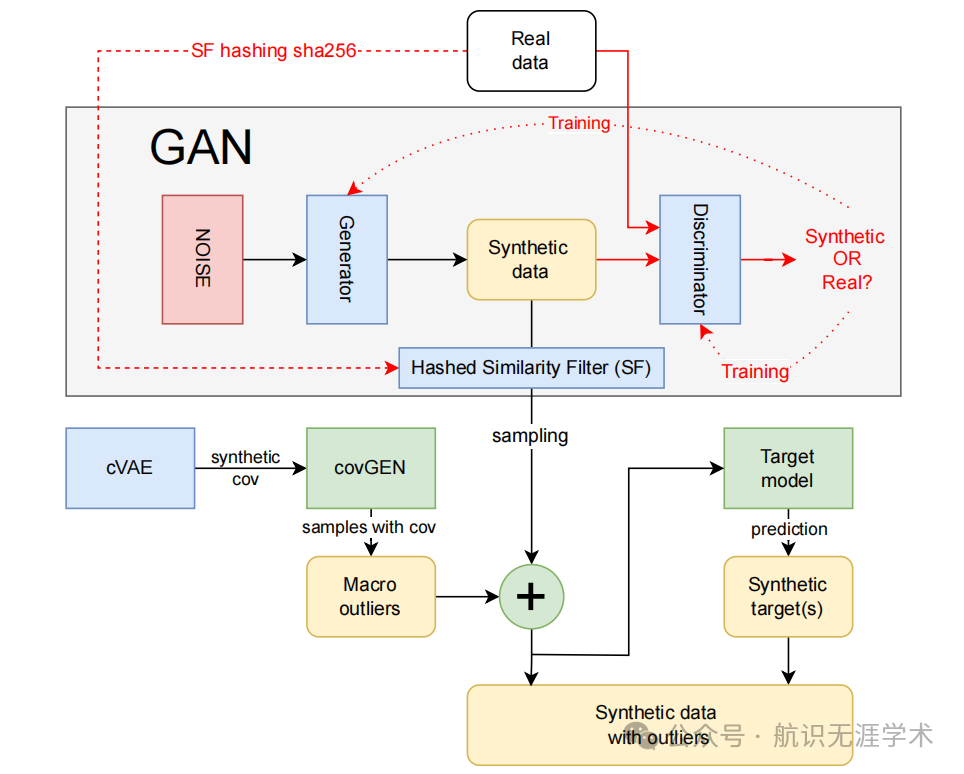
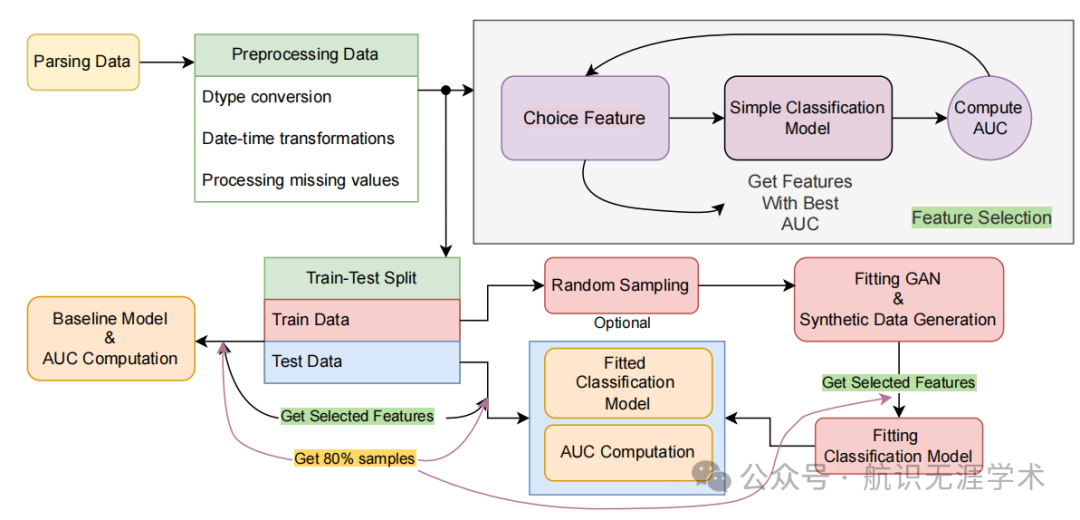
异常值条件协方差生成器(covGEN):通过从多变量手动拟合的分布中采样来生成宏观异常值,可以基于真实数据的协方差或条件变分自编码器(cVAE)生成的合成协方差矩阵。
条件变分自编码器(cVAE):用于生成与真实数据结构对应的合成协方差矩阵,通过最小化重建误差和潜在空间分布与真实数据先验分布之间的Kullback-Leibler散度来实现。
目标模型模块:基于分类模型(如Catboost)预测集成到合成数据中的目标特征,该模型在真实数据样本上进行训练,以从包含宏观和微观数据的列中收集弱解释信息。
创新点
-
异常值生成能力:ZGAN能够根据真实数据的协方差或合成协方差矩阵生成异常值,这对于建模复杂经济事件和增强预测模型训练中的异常值具有重要意义。例如,在A9数据集的实验中,当在宏观变量中生成5%的异常值时,分类任务的AUC值显著提高了0.0127。
特征相关性保持:与CTGAN和TVAE相比,ZGAN在保持原始数据特征相关性方面表现出色。
小编整理了GAN论文代码合集
需要的同学
回复“GAN”即可全部领取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









