






2025深度学习发论文&模型涨点之——特征融合
在数据处理的最早阶段,将不同来源或类型的特征合并在一起。例如,对于多模态数据(如图像和文本),在将图像数据转换为特征向量(如通过卷积神经网络提取的图像特征)和文本数据转换为特征向量(如通过词嵌入和循环神经网络提取的文本特征)之后,直接将这两个特征向量拼接在一起。
-
优点:能够充分利用不同模态数据之间的互补信息,模型可以学习到更丰富的特征表示。例如,在自动驾驶场景中,将车辆的传感器数据(如雷达数据和摄像头图像数据)进行早期融合,可以让车辆更准确地感知周围环境。
-
缺点:由于是在特征提取后的初步阶段进行融合,可能会导致融合后的特征维度过高,增加模型的计算复杂度。而且如果不同模态数据的特征提取方法不够准确,融合后的特征可能会受到“污染”。
小编整理了一些特征融合【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学扫码添加我
回复“特征融合”即可全部领取

论文精选
论文1:
HiFuse: Hierarchical Multi-Scale Feature Fusion Network for Medical Image Classification
HiFuse:用于医学图像分类的层次多尺度特征融合网络
方法
-
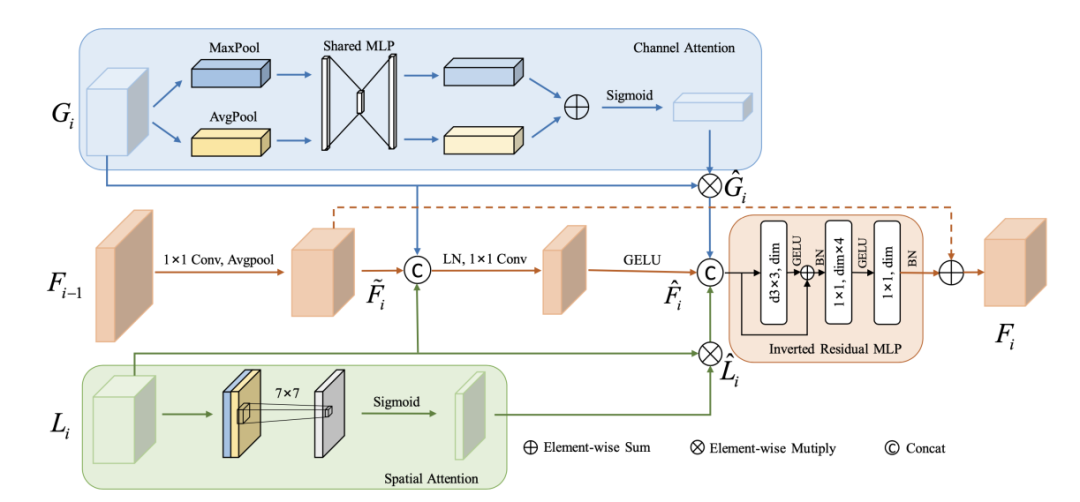
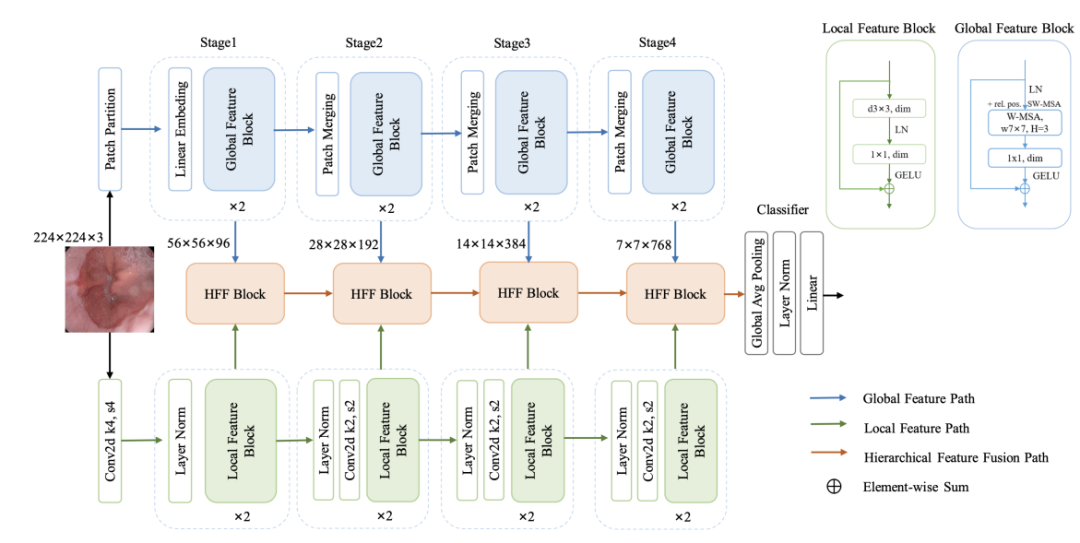
三分支结构:提出HiFuse网络,包含局部特征块、全局特征块和HFF块,分别提取局部空间信息和全局语义信息,并进行特征融合。
局部特征块:使用3×3深度卷积提取局部特征,通过线性层和激活函数进行信息交互。
全局特征块:引入窗口多头自注意力机制(W-MSA),有效降低计算量,提取全局语义信息。
HFF块:包含空间注意力、通道注意力、残差逆MLP和快捷连接,自适应融合不同层次的特征。
创新点
-
融合CNN和Transformer优势:结合CNN的局部特征提取能力和Transformer的全局语义建模能力,显著提升医学图像分类性能。
层次多尺度特征融合:通过HFF块融合不同尺度的局部和全局特征,全面挖掘病变区域的深浅和全局局部特征,提升分类精度。
性能提升:在ISIC2018、Covid-19和Kvasir数据集上,HiFuse模型的准确率分别比基线提高了7.6%、21.5%和10.4%,优于其他先进模型。
论文2:
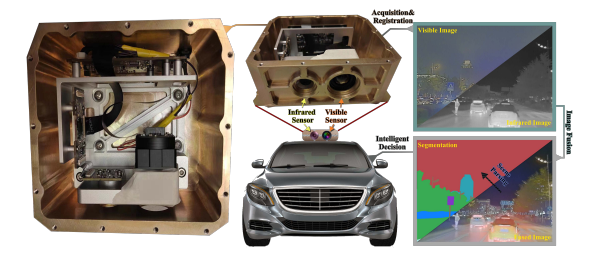
Multi-interactive Feature Learning and a Full-time Multi-modality Benchmark for Image Fusion and Segmentation
多交互特征学习和全天时多模态基准测试用于图像融合与分割
方法
-
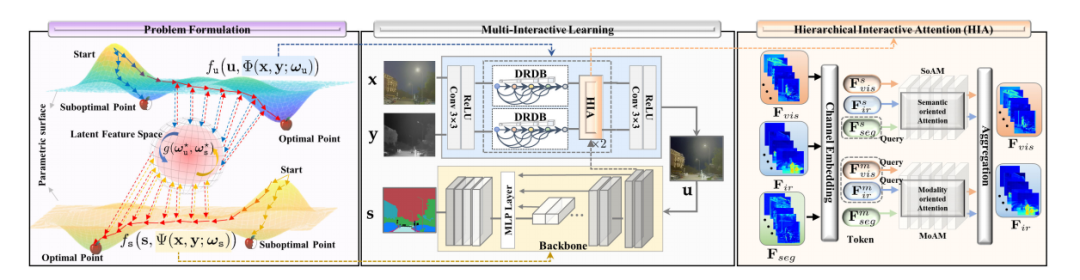
SegMiF架构:提出SegMiF,包含融合子网络和分割子网络,通过层次交互注意力(HIA)模块连接两个网络,实现特征交互。
层次交互注意力(HIA):通过语义/模态多头注意力机制,同时保留模态特征并增强语义特征。
动态权重因子:引入动态权重因子自动调整每个任务的权重,平衡特征交互,避免手动调整。
多模态基准测试(FMB):构建智能多波段双目成像系统,收集包含15个像素级标注类别的全天时多模态基准测试数据集。
创新点
-
联合优化融合与分割:首次将图像融合和语义分割联合优化,通过交互特征学习实现“两全其美”,在真实场景中分割mIoU平均提升7.66%。
层次交互注意力:通过HIA模块实现融合网络和分割网络之间的细粒度特征映射,增强语义特征的同时保留模态特征。
动态权重因子:自动学习每个任务的最优权重,避免手动调整,提升模型在融合和分割任务上的性能。
全面基准测试:FMB数据集包含丰富场景和多种恶劣环境,为多模态图像融合和分割研究提供全面基准。

论文3:
SecondPose: SE(3)-Consistent Dual-Stream Feature Fusion for Category-Level Pose Estimation
SecondPose:用于类别级姿态估计的SE(3)一致性双流特征融合
方法
-
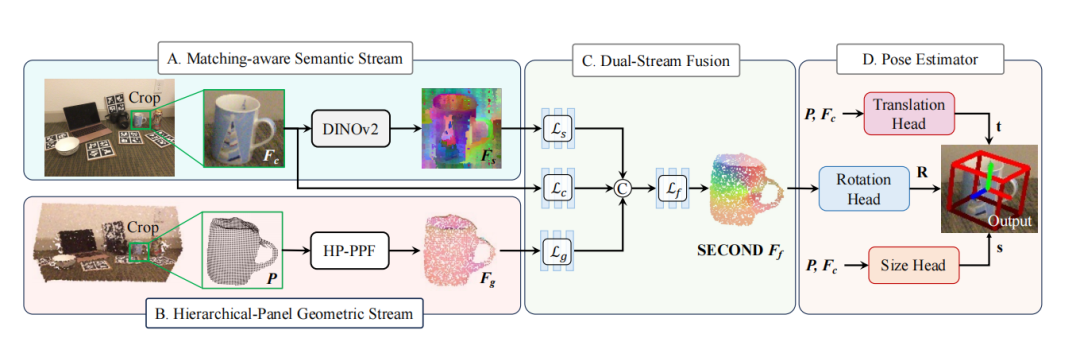
DINOv2特征提取:利用DINOv2提取语义特征,提供类别先验信息。
几何特征提取:基于点对特征(PPF)计算层次几何特征,从局部到全局编码物体结构信息。
SE(3)一致性融合:将几何特征与DINOv2特征对齐,建立SE(3)变换下一致的对象表示。
姿态估计:将融合后的特征输入姿态估计器,预测物体的6D姿态和3D尺寸。
创新点
-
融合语义与几何特征:首次将DINOv2的语义特征与几何特征融合,提升类别级姿态估计性能。
SE(3)一致性表示:通过几何特征对齐,建立SE(3)变换下一致的对象表示,简化姿态估计过程,提升准确性和效率。
性能提升:在NOCS-REAL275数据集上,SecondPose的平均精度(mAP)比之前最佳方法提升了12.4%,在HouseCat6D数据集上也大幅领先。
论文4:
Time-space-frequency feature Fusion for 3-channel motor imagery classification
3通道运动想象分类的时间-空间-频率特征融合
方法
-
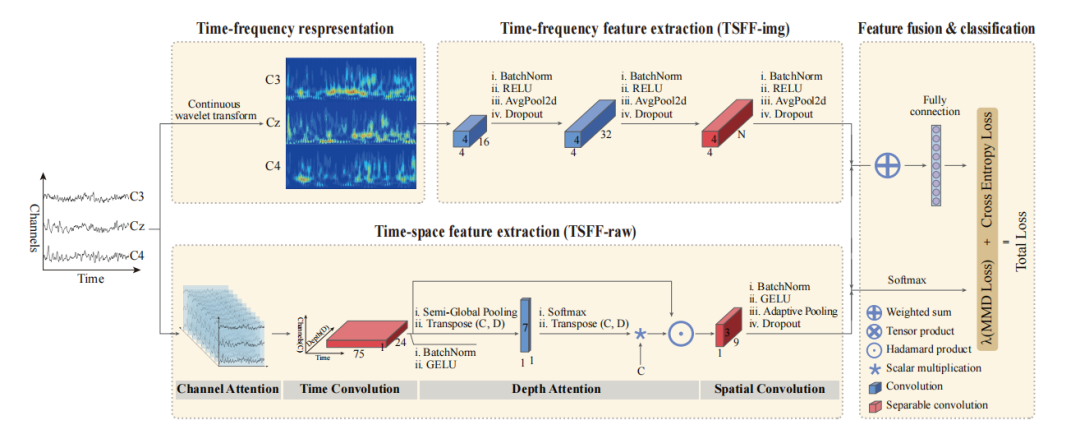
时间-频率表示:使用连续小波变换(CWT)将EEG信号转换为时间-频率谱图。
时间-频率特征提取:设计轻量级网络TSFF-img,提取时间-频率谱图中的特征。
时间-空间特征提取:基于LMDA-Net架构,提取时间序列EEG信号的时间-空间特征。
特征融合与分类:通过MMD损失和加权融合方法,将时间-频率特征和时间-空间特征结合,进行分类。
创新点
-
多模态特征融合:提出TSFF-Net,融合时间-空间-频率特征,弥补单一模态特征提取网络的不足。
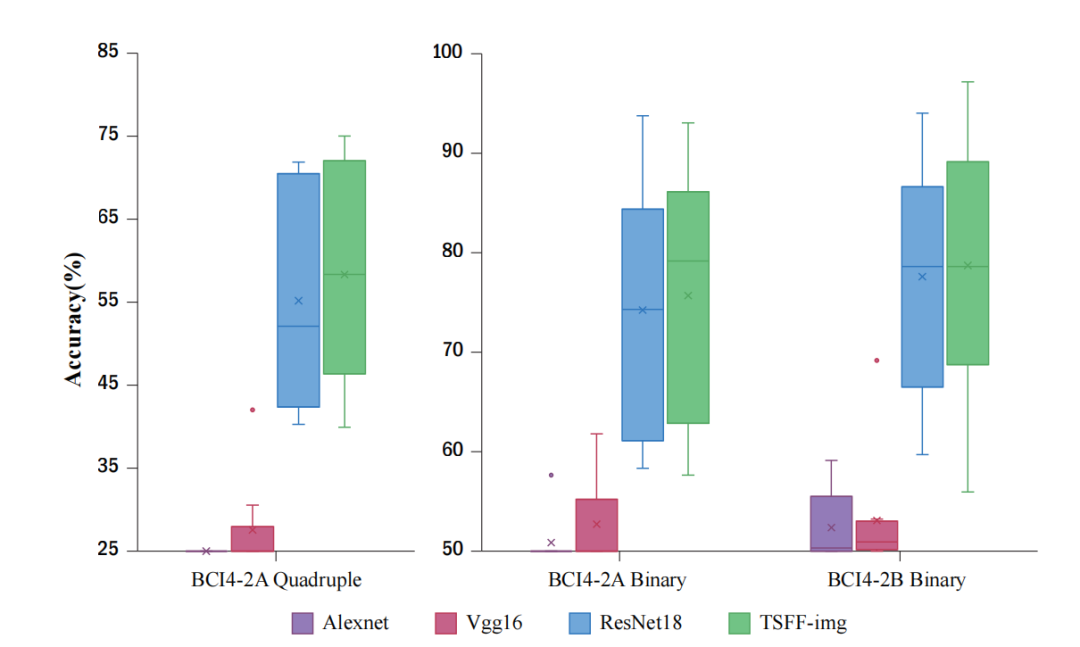
轻量级网络设计:TSFF-img网络轻量且浅层,适合从EEG时间-频率谱图中提取特征,性能优于AlexNet、VGG和ResNet。
性能提升:在BCI4-2A和BCI4-2B数据集上,TSFF-Net的分类准确率高于其他先进方法,仅用3个通道就超过部分基于22个通道的方法。
小编整理了特征融合论文代码合集
需要的同学扫码添加我
回复“ 多特征融合”即可全部领取


















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









