




更多特训营笔记详见个人主页【面试鸭特训营】专栏
250103
1. Redis 中跳表的实现原理是什么?
跳表的定义
- 跳表是一个多层链表
- 最底层的链表中保存了所有的元素
- 每一层链表都是它下一层链表的子集,非最底层链表仅保存了部分元素,且层数越高保存的元素数量越少
- 每一个上层链表,都是下层链表的“索引”
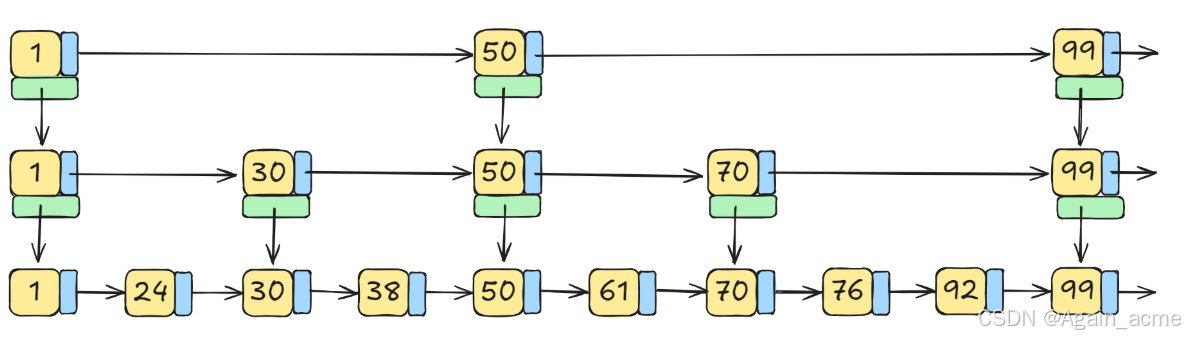
查询的原理
- 跳表的平均时间复杂度是O (logn),最差的时间复杂度是O (n)
- 假设要查找 70 这个元素
- 传统链表(最底层链表)需要查询 6 次
- 跳表需要查询 3 次
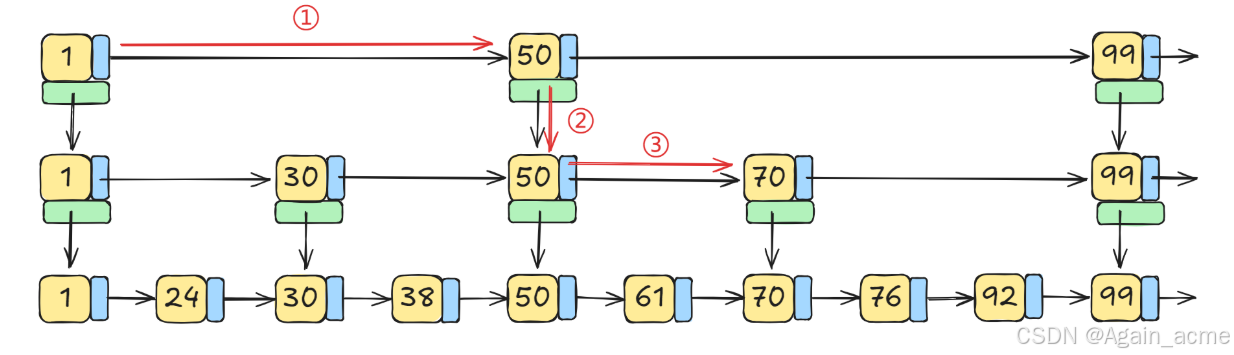
- 假设要查找 92 这个元素
- 传统链表(最底层链表)需要查询 8 次
- 跳表需要查询 6 次
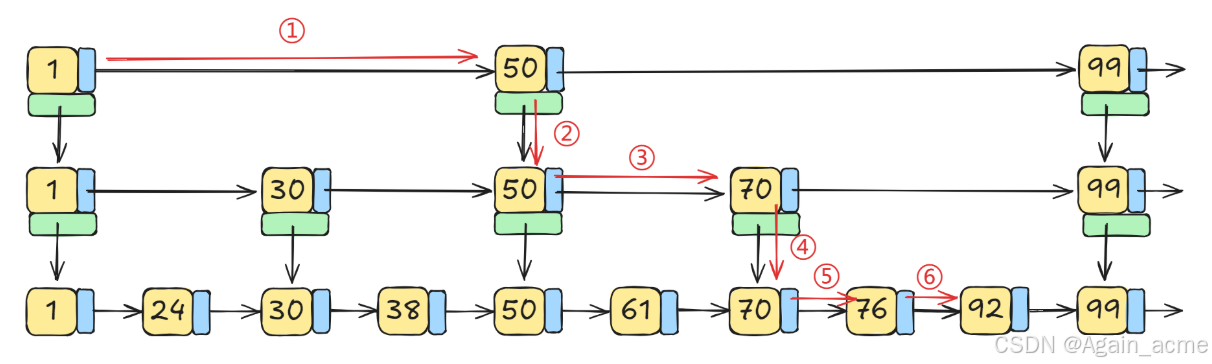
插入的原理
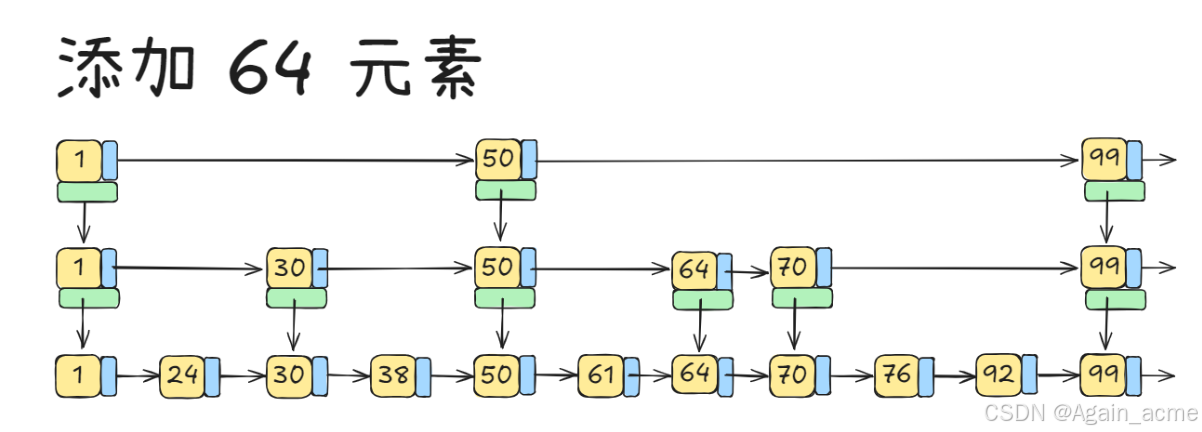
- 假设要插入 64 这个元素
- 先定位到【第一个】大于 64 的数据,为 70
- 通过随机算法随机选取一层,以第 2 层为例(也有可能会是第 1 层)
- 具体随机算法是:第一层概率是1/2,第二层1/4,以此类推
- 在第 2 层中添加 64 这个元素
- 由于第 2 层不是最后一层,给他下面的每一层也添加 64 这个元素
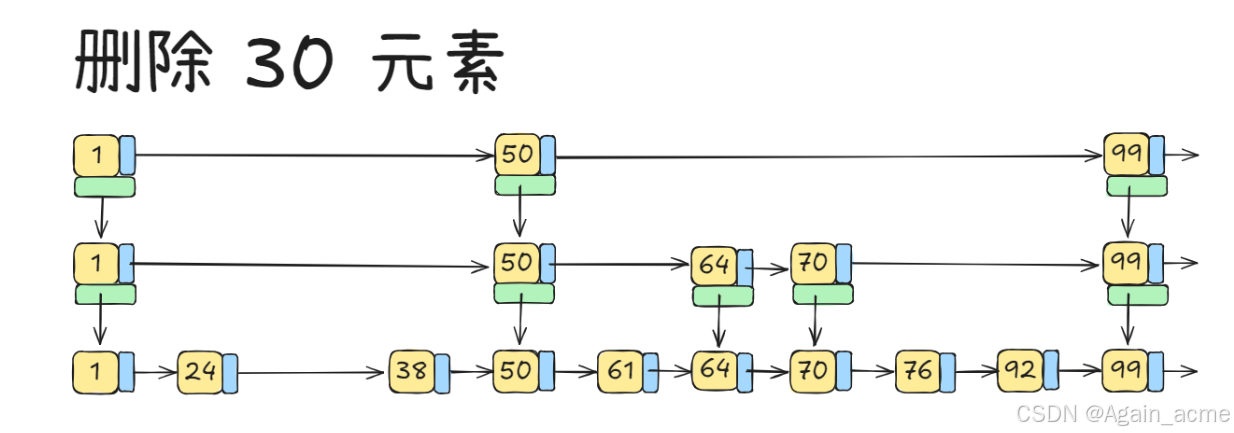
删除的原理
- 假设要删除 30 这个元素
- 先定位到【第一个】30
- 删除这个元素
- 如果他有指向下一层的指针,把下一层的 30 元素也删除
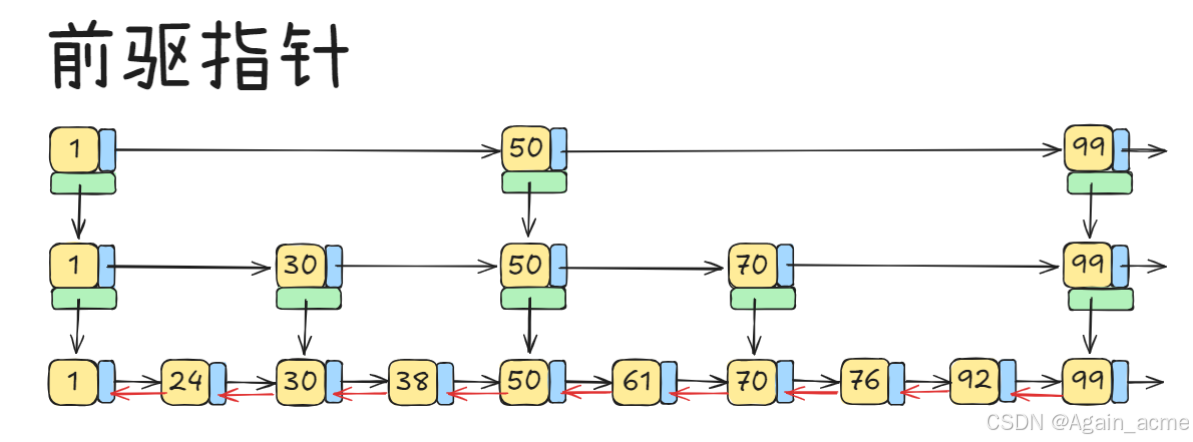
回退指针
- 为提高跳表的操作效率和灵活性,Redis 中的跳表实现了前驱指针
2. Redis 的 hash 是什么?
底层实现
- Redis 6 及之前,Hash 的底层是压缩列表 + 哈希表(ziplist + hashtable)
- Redis 7 及之后,Hash 的底层是紧凑列表 + 哈希表(listpack + hashtable)
- ziplist 和 listpack 查找 key 的效率是类似的,时间复杂度都是O(n),主要区别是 listpack 解决了 ziplist 的【级联更新】问题
- 使用 ziplist / listpack 和 hashtable 的时机
- Redis 内有两个属性
hash-max-ziplist-entries(hash-max-listpack-entries) ,用于记录 Hash 类型键的字段数量(默认512,可修改)hash-max-ziplist-value(hash-max-listpack-value) ,用于记录每个字段名和字段值的长度(默认64,可修改)
- 当 hash 小于这两个值的时候,使用 ziplist / listpack 进行存储
- 当 hash 大于这两个值的时候,使用 hashtable 进行存储
- 注意:在使用 hashtable 进行存储后,就无法再退化为 ziplist / listpack ,后续都是使用 hashtable 进行存储
- Redis 内有两个属性
常用命令
-
HSET:设置指定 hash 中的某个指定字段的赋值
-
-- 在名为 myhash 的 hash 中,将 name 的值设为 DeerLu HSET myhash name "DeerLu"
-
-
HGET:获取指定 hash 中指定字段的值
-
-- 获取名为 myhash 的 hash 中,name 属性的值 HGET myhash name
-
-
HMSET:一次性设置多个字段的值
-
-- 在名为 myhash 的 hash 中,将 name 的值设为 DeerLu,age 的值设为 18,sex 的值设为男 HMSET myhash name "DeerLu" age "18" sex "男"
-
-
HMGET:一次性获取多个字段的值
-
-- 在名为 myhash 的 hash 中,获取 name age sex 的值 HMGET myhash name age sex
-
-
HGETALL:获取哈希表中所有的字段和值
-
-- 获取名为 myhash 的 hash 的所有字段和值 HGETALL myhash -- 输出结果为 "name" "DeerLu" "age" "18" "sex" "男"
-
-
HDEL:删除一个或多个字段
-
-- 在名为 myhash 的 hash 中,删除 name 字段 HDEL myhash name -- 在名为 myhash 的 hash 中,删除 age sex 字段 HDEL myhash age sex
-
-
HLEN:获取字段数量
-
-- 获取名为 myhash 的 hash 的字段数量 HLEN myhash
-
-
HINCRBY:给某个字段加上一个整数
-
-- 在名为 myhash 的 hash 中,给 age 字段加 1 HINCRBY myhash age 1
-
3. Redis Zset 的实现原理是什么?
底层实现
- 两个条件
- 元素数量 <=
zset-max-ziplist-entries(默认128) - 元素成员名和分值的长度 <=
zset-max-ziplist-value(默认 64 字节)
- 元素数量 <=
- 两个条件都满足时,Redis 会使用压缩列表(Zip List)来存储
- 两个条件有任何一个不满足,Zset 将使用
跳表 + 哈希表作为底层实现- 跳表:用于存储数据的排序和快速查找
- 哈希表:用于存储成员与其分数的映射,提供快速查找
插入
- 使用哈希表存储成员和分数的映射关系,分数作为哈希表中的值
- 将成员和分数插入跳表中,跳表根据分数进行排序
- 时间复杂度为 O(log N),其中 N 是跳表中元素的数量
- 跳表中查找插入位置的时间复杂度是 O(log N)
- 哈希表中添加元素的时间复杂度是 O(1)
删除
- 哈希表中删除成员映射关系
- 跳表中删除该成员
- 时间复杂度是 O(log N),其中 N 是跳表中元素的数量
修改
- 哈希表中更新成员的分数
- 跳表中更新成员的位置
- 时间复杂度为 O(log N),其中 N 是跳表中元素的数量
- 跳表中查找插入位置的时间复杂度是 O(log N)
- 哈希表中修改元素的时间复杂度是 O(1)
范围查询
- 跳表中根据分数区间查询成员
- 哈希表中快速查找成员的分数
- 时间复杂度为 O(log N + M),其中 N 是跳表中元素的数量,M是返回的成员数量
应用场景
- 主要用于需要排序和快速查找的场景
- 排行榜:游戏积分排行榜
- 延迟队列:任务调度和延迟任务
- 粉丝数排名:抖音等用户粉丝数排行榜

















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









