




更多特训营笔记详见个人主页【面试鸭特训营】专栏
250102
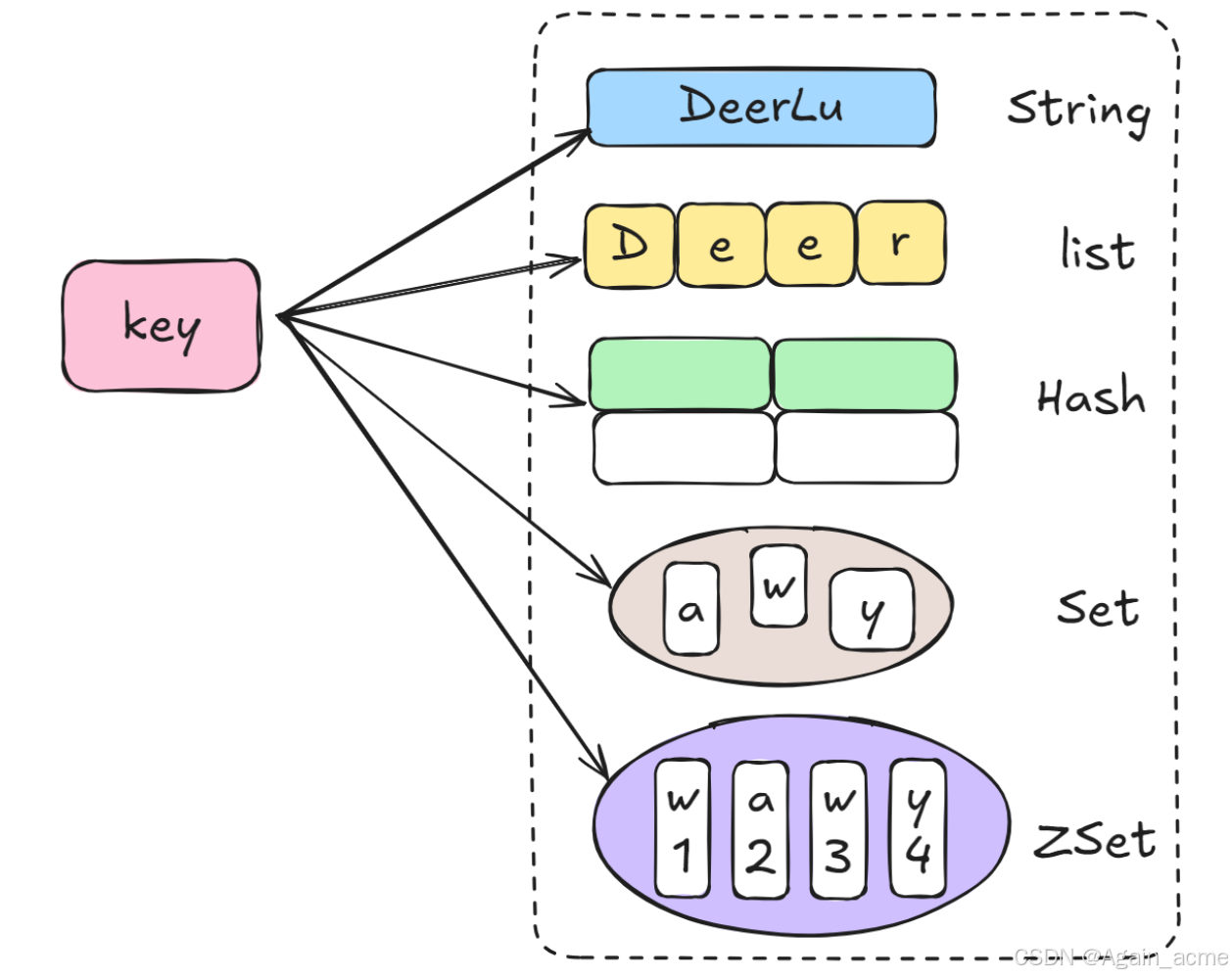
1. Redis 中常见的数据类型有哪些?
| 数据结构 | 描述 | 最大容量 | 适用场景 |
|---|---|---|---|
| string | 底层是字节数组 | 512MB数据 | 缓存、计数器、分布式锁 |
| hash | key / field / value 三个字段 | 42亿个键值对 | 实体类数据(购物车数据) |
| list | 类似于LinkedList | 42亿个元素 | 消息队列、历史记录 |
| set | 类似于HashSet | 42亿个元素 | 标签系统、用户关注、点赞 |
| zset | 有序的set集合,类似于TreeSet | 42亿个元素 | 排行榜、任务调度 |
Redis 9 种基本数据类型应用场景汇总
- String
- 缓存对象、计数器、分布式锁、分布式锁
- List
- 阳塞队列、消息队列
- 使用 List 用作消息队列时,【需要自己实现生产者是全局同一的】且【不能以消费者组来消费数据】
- 阳塞队列、消息队列
- Hash
- 缓存对象、购物车实体数据
- Set
- 点赞、共同关注、收藏
- Zset
- 排行榜(面试常问)
- BitMap(2.2 版新增)
- 主要有0和1两种状态
- 用于去重、签到统计、用户登录态判断等
- HyperLogLog(2.8 版新增)
- 海量数据基数统计的场景,有一定的误差,可以根据场景选择使用
- 用于网页 PV、UV 的统计
- GEO(3.2 版新增)
- 存储地理位置信息的场景,比如说百度地图、高德地图、附近的人等
- Stream (5.0 版新增)
- 用于实现消息队列
- 相比与 list 多了两个特性【自动生成全局唯一消息 ID 】和【支持以消费组形式消费数据】
2. Redis 为什么这么快?
| 特性 | MySQL | Redis |
|---|---|---|
| 存储位置 | 磁盘 | 主要保存在内存,持久化后可以保存在磁盘中 |
| 持久化 | 默认持久化,数据存储在磁盘文件中 | 默认将数据存储在内存,支持 RDB 和 AOF 两种持久化方案 |
| 性能 | 频繁 I/O 操作导致性能较低 | 内存内操作,性能较高 |
| ACID | 高,支持 ACID 事务特性,数据可靠 | 可以配置为高持久性,但不提供 ACID 支持 |
| 同时操作线程数 | 多线程,可能会竞争资源 | 单线程,不存在上下文切换,避免争夺资源 |
| 适用场景 | 适用于结构化数据、大规模关系型数据存储 | 适用于高频访问、低延迟的缓存、实时数据存储 |
3. 为什么 Redis 设计为单线程?6.0 版本为何引入多线程?
单线程
- 可以避免多线程时的线程上下文切换锁带来的性能开销
- 使用 I/O多路服用模型可以调高 Redis 的 I/O 利用率
多线程
- 数据量和请求量的增多,会导致网络 I/O 限制 Redis 的性能
- 仅针对网络请求的模块采用多线程模式,对于读写命令部分依旧采取单线程模式,依旧能够保证线程安全
- Redis 6.0 的默认是你用多线程的,只会使用主线程,需要开启的话将配置
io-threads-do-reads参数为no

















 1431
1431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









