




更多特训营笔记详见个人主页【面试鸭特训营】专栏
20241225
1. MySQL 三层 B+ 树能存多少数据?
- 前置知识点
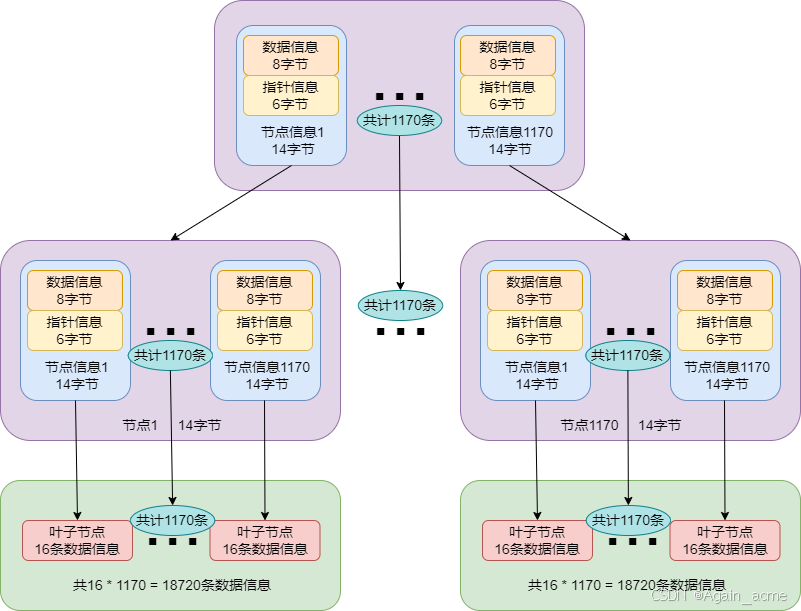
- 在MySQL的Innodb存储引擎中,B+树默认数据页的大小为16KB(即每个节点页的大小为16KB == 16384字节)
- 假设每个数据记录的主键和数据大小为1KB(实际上一般会比这个小,取整是为了方便计算)(即一条数据信息占据1KB)
- 叶子节点中仅存储数据信息
- 非叶子节点中存储指向子节点的指针(称为指针信息,假设为6字节)和保存索引信息的数据值(称为数据信息,假设为8字节)
- 【节点信息】由一个【数据信息】和一个【指针信息】组成,占据14字节
- 数据量计算
- 根节点:大小为16KB(16384字节),每个节点信息14字节,可以保存16384 / 14 = 1170 个节点信息,即可以指向 1170 个中间节点
- 中间节点:原理同根节点,可以指向 1170 个叶子节点
- 叶子节点:大小为16KB,每条数据信息1KB,可以存储16条数据信息
- 三层B+树能存储的数据总量为
1170*1170*16 = 21902400,即一个三层的B+树能存储约2000万条记录
- 图示
2. MySQL 索引的最左前缀匹配原则是什么?
前置知识1:MySQL框架
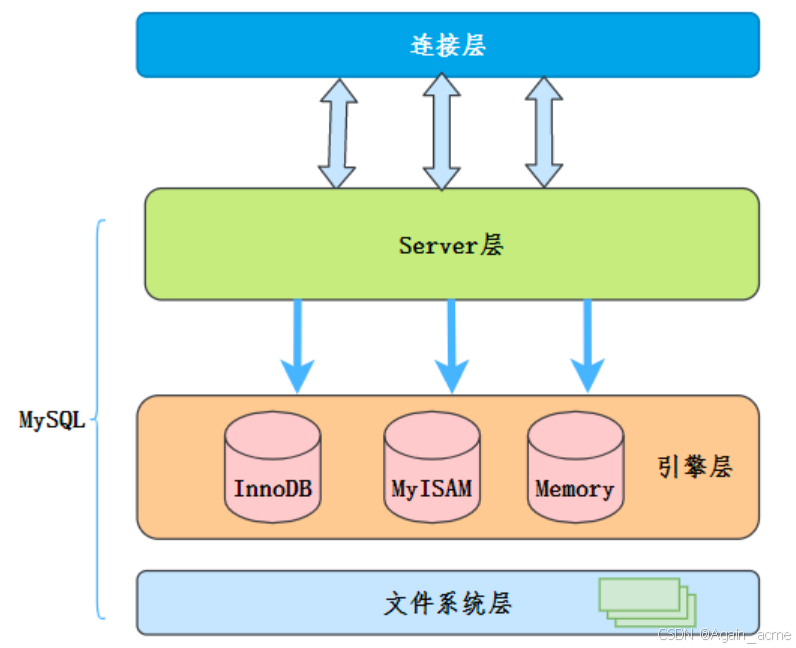
- 连接层:接收客户端的连接、完成连接处理和认证授权、检查是否超过最大连接数
- 服务层:解析 SQL 的语法、语义、实现了存储过程、触发器、视图、函数等
- 存储引擎层:负责数据的存储和提
前置知识2:索引下推
-
前置条件:使用了联合索引
-
定义:把部分查询条件从服务层下推到存储引擎层,来减少IO次数和需要从表中读取的数据行
最左匹配原则
-
前置条件:使用了联合索引
-
定义:使用联合索引进行查询时,查询条件必须包括索引中第一个列的条件信息,然后是第二个第三个列
-
底层原理:联合索引在B+树中遵循
从左到右的顺序进行排列,MySQL在查找时会优先使用联合索引中的第一个列属性作为匹配依据,然后再使用第二个第三个列。如果跳过最左侧列属性,会导致无法利用该索引。 -
举例说明
-
当前表有一个联合索引(a,b,c)
-
-- 以下查询条件 【符合】 最左匹配原则 where a = 1; where a = 1, b = 2; where a = 1, b = 2, c = 3; -
-- 以下查询条件 【不符合】 最左匹配原则 where b = 2; where c = 3; where b = 2, c = 3; -
-- 以下查询条件涉及到【索引下推】 where a = 1, c = 3; -- 在MySQL5.6版本之前,当前查询条件只能利·a = 1 条件进行筛选 -- 在MySQL5.6版本之后,当前查询条件会通过【索引下推】,在存储引擎层查询到满足 a = 1 的数据后,再利用 c = 3 过滤掉不符合的数据,然后返回给server层
-
3. 为什么 MySQL 选择使用 B+ 树作为索引结构?
在我看来红黑树是结合了二叉树和AVL树双方优点的进化版,红黑树的前身是234树,234树是一颗4阶B树,所以本质上来说红黑树就是一颗B树,下面说一下我理解的B+树和B树的对比
B+树的特点
- 多叉树、自平衡、叶子节点存数据、非叶子节点存指针、叶子层有双向链表连接、支持范围查询、高度低、查询效率稳定
B+树和B树对比
-
B树的所有节点都会存储数据信息和索引信息,B+树只有叶子节点中存储数据信息和索引信息,非叶子节点只存储索引信息
-
由于B+树的叶子层有双向链表连接,B+树支持范围查询、B树不支持范围查询
-
对于同一组查询数据,由于B+树的层数更低,B+树的平均磁盘IO次数低于B树
-
由于B+树的所有数据信息都保存在叶子层中,B+树查询效率稳定、B树查询效率不稳定

















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









