import pandas as pd
import numpy as np
from tqdm import tqdm
import logging
import re
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import json
import os
import ast
from typing import List, Dict, Any, Optional, Tuple
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoModel
import torch.nn.functional as F
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
from dataclasses import dataclass
import psutil
import gc
# 设置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
@dataclass
class EvaluationConfig:
"""评估配置参数"""
max_length: int = 512
batch_size: int = 8
temperature: float = 0.1
max_new_tokens: int = 200
similarity_threshold: float = 0.7
cache_embeddings: bool = True
use_quantization: bool = True # 使用量化优化
max_workers: int = 4 # 最大并行工作数
class OptimizedRAGEvaluator:
def __init__(self, model_path: str = None, embedding_model_path: str = None,
device: str = None, config: EvaluationConfig = None):
"""
初始化优化的RAG评估器
参数:
model_path: 评估模型路径
embedding_model_path: 嵌入模型路径
device: 设备类型
config: 评估配置
"""
self.device = device if device else ('cuda' if torch.cuda.is_available() else 'cpu')
self.config = config or EvaluationConfig()
# 缓存优化
self.embedding_cache = {}
self.similarity_cache = {}
# 性能监控
self.start_time = None
self.memory_usage = []
logger.info("=" * 60)
logger.info("初始化RAG评估器")
logger.info(f"使用设备: {self.device}")
logger.info(f"配置参数: {self.config}")
# 异步加载模型
self.model, self.tokenizer = self._load_model_async(model_path)
self.embedding_model, self.embedding_tokenizer = self._load_embedding_model_async(embedding_model_path)
# 预加载停用词
self.stop_words = self._load_stop_words()
logger.info("RAG评估器初始化完成")
logger.info("=" * 60)
def _get_memory_usage(self) -> str:
"""获取内存使用情况"""
process = psutil.Process()
memory_mb = process.memory_info().rss / 1024 / 1024
return f"{memory_mb:.1f}MB"
def _load_stop_words(self) -> set:
"""加载中文停用词"""
logger.info("加载停用词表...")
try:
stop_words = {
'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到',
'说', '要', '去', '你', '会', '着', '没有', '看', '好', '自己', '这', '那', '他', '她', '它', '我们',
'他们',
'这个', '那个', '这些', '那些', '什么', '怎么', '为什么', '吗', '呢', '吧', '啊', '哦', '嗯', '唉',
'喂',
'虽然', '但是', '因为', '所以', '如果', '那么', '虽然', '尽管', '即使', '无论', '不管', '只要', '只有',
'除非',
'同时', '另外', '此外', '而且', '并且', '或者', '还是', '要么', '不仅', '而且', '既', '又', '一边',
'一面',
'首先', '其次', '最后', '总之', '例如', '比如', '正如', '像', '好像', '似乎', '大约', '大概', '可能',
'也许',
'非常', '很', '挺', '相当', '十分', '特别', '尤其', '比较', '稍微', '有点', '一些', '一点', '许多',
'很多',
'所有', '每个', '任何', '有些', '几个', '少数', '多数', '全部', '部分', '整个', '完全', '彻底', '绝对',
'相对'
}
logger.info(f"加载停用词完成,共 {len(stop_words)} 个词")
return stop_words
except Exception as e:
logger.warning(f"加载停用词失败: {e}")
return set()
def _load_model_async(self, model_path: str) -> Tuple[Any, Any]:
"""异步加载评估模型"""
if not model_path or model_path.lower() == "none":
logger.info("未指定评估模型,将使用基于规则的评估方法")
return None, None
try:
logger.info(f"开始加载评估模型: {model_path}")
start_time = time.time()
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True,
padding_side='left'
)
# 模型加载配置
model_kwargs = {
"trust_remote_code": True,
"low_cpu_mem_usage": True,
"torch_dtype": torch.float16 if self.device == 'cuda' else torch.float32,
}
if self.config.use_quantization and self.device == 'cuda':
model_kwargs["load_in_8bit"] = True
logger.info("使用8位量化优化")
if self.device == 'cuda':
model_kwargs["device_map"] = "auto"
else:
model_kwargs["device_map"] = None
model = AutoModelForCausalLM.from_pretrained(model_path, **model_kwargs)
if self.device != 'cuda':
model = model.to(self.device)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
load_time = time.time() - start_time
logger.info(f"评估模型加载完成,耗时: {load_time:.2f}秒")
logger.info(f"模型内存占用: {self._get_memory_usage()}")
return model, tokenizer
except Exception as e:
logger.error(f"加载评估模型失败: {e}")
return None, None
def _load_embedding_model_async(self, embedding_model_path: str) -> Tuple[Any, Any]:
"""异步加载嵌入模型"""
if not embedding_model_path or embedding_model_path.lower() == "none":
logger.info("未指定嵌入模型,将使用TF-IDF方法")
return None, None
try:
logger.info(f"开始加载嵌入模型: {embedding_model_path}")
start_time = time.time()
tokenizer = AutoTokenizer.from_pretrained(
embedding_model_path,
trust_remote_code=True
)
model_kwargs = {
"trust_remote_code": True,
"low_cpu_mem_usage": True,
"torch_dtype": torch.float16 if self.device == 'cuda' else torch.float32,
}
if self.config.use_quantization and self.device == 'cuda':
model_kwargs["load_in_8bit"] = True
if self.device == 'cuda':
model_kwargs["device_map"] = "auto"
else:
model_kwargs["device_map"] = None
model = AutoModel.from_pretrained(embedding_model_path, **model_kwargs)
if self.device != 'cuda':
model = model.to(self.device)
load_time = time.time() - start_time
logger.info(f"嵌入模型加载完成,耗时: {load_time:.2f}秒")
logger.info(f"模型内存占用: {self._get_memory_usage()}")
return model, tokenizer
except Exception as e:
logger.error(f"加载嵌入模型失败: {e}")
return None, None
def load_data_from_excel(self, file_path: str) -> Tuple[List[Dict[str, Any]], pd.DataFrame]:
"""从Excel文件加载评估数据"""
logger.info(f"开始加载数据文件: {file_path}")
start_time = time.time()
try:
# 检查文件是否存在
if not os.path.exists(file_path):
raise FileNotFoundError(f"Excel文件不存在: {file_path}")
# 读取Excel文件
df = pd.read_excel(file_path)
logger.info(f"成功从 {file_path} 加载数据,共 {len(df)} 行")
# 检查必要的列是否存在
required_columns = ['question', 'answer', 'contexts']
missing_columns = [col for col in required_columns if col not in df.columns]
if missing_columns:
raise ValueError(f"Excel文件中缺少必要的列: {missing_columns}")
# 转换为字典列表
eval_data = []
successful_rows = 0
for idx, row in tqdm(df.iterrows(), total=len(df), desc="解析数据行"):
try:
# 处理contexts字段,确保它是字符串列表形式
contexts = row['contexts']
if isinstance(contexts, str):
try:
# 尝试解析字符串形式的列表
contexts = ast.literal_eval(contexts)
except:
# 如果解析失败,尝试其他分隔符
if ';' in contexts:
contexts = [ctx.strip() for ctx in contexts.split(';') if ctx.strip()]
else:
contexts = [ctx.strip() for ctx in contexts.split(',') if ctx.strip()]
elif pd.isna(contexts):
contexts = []
elif not isinstance(contexts, list):
contexts = [str(contexts)]
# 确保contexts是字符串列表
contexts = [str(ctx) for ctx in contexts if ctx and str(ctx).strip()]
sample_data = {
"question": str(row['question']),
"answer": str(row['answer']),
"contexts": contexts,
}
# 添加可选字段
if 'ground_truth' in df.columns and pd.notna(row['ground_truth']):
sample_data["ground_truth"] = str(row['ground_truth'])
eval_data.append(sample_data)
successful_rows += 1
except Exception as e:
logger.warning(f"解析第 {idx + 1} 行数据时出错: {e}")
continue
load_time = time.time() - start_time
logger.info(f"数据加载完成,成功解析 {successful_rows}/{len(df)} 行,耗时: {load_time:.2f}秒")
return eval_data, df
except Exception as e:
logger.error(f"加载Excel文件时出错: {e}")
return [], None
def validate_dataset(self, eval_data: List[Dict[str, Any]]) -> bool:
"""验证数据集格式是否符合要求"""
logger.info("开始验证数据集格式...")
try:
if not eval_data:
raise ValueError("评估数据为空")
required_keys = {"question", "answer", "contexts"}
valid_samples = 0
for i, item in enumerate(eval_data):
# 检查必需键是否存在
if not required_keys.issubset(set(item.keys())):
missing = required_keys - set(item.keys())
raise ValueError(f"样本 {i} 缺少必要的键: {missing}")
# 检查contexts格式是否为字符串列表
contexts = item["contexts"]
if not isinstance(contexts, list):
raise ValueError(f"样本 {i} 的contexts必须是列表")
# 检查列表中的每个元素是否为字符串
for j, ctx in enumerate(contexts):
if not isinstance(ctx, str):
raise ValueError(f"样本 {i} 的contexts[{j}]必须是字符串,实际类型: {type(ctx)}")
valid_samples += 1
logger.info(f"数据集验证通过,有效样本数: {valid_samples}/{len(eval_data)}")
return True
except Exception as e:
logger.error(f"数据集验证失败: {e}")
return False
def get_embeddings_batch(self, texts: List[str]) -> np.ndarray:
"""批量获取文本嵌入向量(带缓存)"""
if not texts:
return np.array([])
# 检查缓存
uncached_texts = []
cached_embeddings = []
indices = []
for i, text in enumerate(texts):
if not text or not text.strip():
# 处理空文本
uncached_texts.append(" ")
indices.append(i)
continue
text_hash = hash(text)
if self.config.cache_embeddings and text_hash in self.embedding_cache:
cached_embeddings.append(self.embedding_cache[text_hash])
else:
uncached_texts.append(text)
indices.append(i)
# 如果有未缓存的文本,批量处理
if uncached_texts:
logger.debug(f"计算 {len(uncached_texts)} 个文本的嵌入向量")
new_embeddings = self._compute_embeddings(uncached_texts)
# 缓存新计算的嵌入
for text, embedding in zip(uncached_texts, new_embeddings):
if text.strip(): # 只缓存非空文本
text_hash = hash(text)
self.embedding_cache[text_hash] = embedding
# 合并结果
if not cached_embeddings:
return new_embeddings
# 创建结果数组
embedding_dim = new_embeddings.shape[1] if len(new_embeddings) > 0 else cached_embeddings[0].shape[0]
result_embeddings = np.zeros((len(texts), embedding_dim))
if len(new_embeddings) > 0:
result_embeddings[indices] = new_embeddings
# 填充缓存的嵌入
cache_idx = 0
for i in range(len(texts)):
if i not in indices:
result_embeddings[i] = cached_embeddings[cache_idx]
cache_idx += 1
return result_embeddings
def _compute_embeddings(self, texts: List[str]) -> np.ndarray:
"""计算文本嵌入向量"""
if self.embedding_model is None:
logger.debug("使用TF-IDF方法计算嵌入向量")
return self._get_tfidf_embeddings(texts)
try:
# 批量处理
batch_embeddings = []
total_batches = (len(texts) + self.config.batch_size - 1) // self.config.batch_size
for i in tqdm(range(0, len(texts), self.config.batch_size),
desc="计算嵌入向量", total=total_batches, leave=False):
batch_texts = texts[i:i + self.config.batch_size]
# 过滤空文本
valid_texts = [text for text in batch_texts if text and text.strip()]
if not valid_texts:
# 处理全空批次
dummy_embedding = np.random.normal(0, 1, (len(batch_texts), 768))
batch_embeddings.append(dummy_embedding)
continue
inputs = self.embedding_tokenizer(
valid_texts,
padding=True,
truncation=True,
return_tensors="pt",
max_length=self.config.max_length
).to(self.device)
with torch.no_grad():
outputs = self.embedding_model(**inputs)
embeddings = self.mean_pooling(outputs, inputs['attention_mask'])
embeddings = F.normalize(embeddings, p=2, dim=1)
# 如果有些文本被过滤掉了,需要填充结果
if len(valid_texts) < len(batch_texts):
full_embeddings = np.zeros((len(batch_texts), embeddings.shape[1]))
valid_idx = 0
for j, text in enumerate(batch_texts):
if text and text.strip():
full_embeddings[j] = embeddings[valid_idx].cpu().numpy()
valid_idx += 1
else:
full_embeddings[j] = np.random.normal(0, 1, embeddings.shape[1])
batch_embeddings.append(full_embeddings)
else:
batch_embeddings.append(embeddings.cpu().numpy())
return np.vstack(batch_embeddings)
except Exception as e:
logger.error(f"计算嵌入时出错: {e}")
return self._get_tfidf_embeddings(texts)
def _get_tfidf_embeddings(self, texts: List[str]) -> np.ndarray:
"""使用TF-IDF获取嵌入向量"""
try:
# 预处理文本
processed_texts = [' '.join(jieba.cut(text)) for text in texts if text and text.strip()]
if not processed_texts:
return np.random.normal(0, 1, (len(texts), 300))
vectorizer = TfidfVectorizer(max_features=5000)
embeddings = vectorizer.fit_transform(processed_texts).toarray()
# 处理空文本
if len(processed_texts) < len(texts):
full_embeddings = np.zeros((len(texts), embeddings.shape[1]))
valid_idx = 0
for i, text in enumerate(texts):
if text and text.strip():
full_embeddings[i] = embeddings[valid_idx]
valid_idx += 1
else:
full_embeddings[i] = np.random.normal(0, 1, embeddings.shape[1])
return full_embeddings
else:
return embeddings
except Exception as e:
logger.error(f"TF-IDF处理失败: {e}")
return np.random.normal(0, 1, (len(texts), 300))
def mean_pooling(self, model_output, attention_mask):
"""优化的平均池化"""
token_embeddings = model_output.last_hidden_state if hasattr(model_output, 'last_hidden_state') else \
model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
def evaluate_single_sample(self, sample: Dict[str, Any]) -> Dict[str, Any]:
"""评估单个样本"""
try:
question = sample["question"]
contexts = sample["contexts"]
answer = sample["answer"]
ground_truth = sample.get("ground_truth")
logger.debug(f"评估问题: {question[:50]}...")
# 确保contexts是字符串列表
if contexts and isinstance(contexts[0], list):
# 如果是列表的列表,展平它
contexts = [item for sublist in contexts for item in sublist if isinstance(item, str)]
elif not isinstance(contexts, list):
contexts = [str(contexts)] if contexts else []
# 过滤掉空字符串
contexts = [ctx for ctx in contexts if ctx and str(ctx).strip()]
# 评估各个指标
faithfulness = self.evaluate_faithfulness(contexts, answer)
answer_relevance = self.evaluate_answer_relevance(question, answer)
context_precision = self.evaluate_context_precision(contexts, answer, ground_truth)
context_recall = self.evaluate_context_recall(contexts, ground_truth) if ground_truth else 0.0
result = {
"question": question,
"answer": answer,
"faithfulness": faithfulness,
"answer_relevance": answer_relevance,
"context_precision": context_precision,
"context_recall": context_recall,
}
if ground_truth:
result["ground_truth"] = ground_truth
logger.debug(f"评估完成: 忠实度={faithfulness:.3f}, 相关性={answer_relevance:.3f}, "
f"精确度={context_precision:.3f}, 召回率={context_recall:.3f}")
return result
except Exception as e:
logger.error(f"评估单个样本时出错: {e}")
return self._create_error_result(sample, str(e))
def evaluate_batch(self, samples: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""批量评估(并行处理)"""
# 先验证数据集格式
if not self.validate_dataset(samples):
raise ValueError("数据集格式验证失败")
logger.info(f"开始批量评估,样本数: {len(samples)}")
logger.info(f"使用并行处理,工作线程数: {self.config.max_workers}")
results = []
processed_count = 0
with ThreadPoolExecutor(max_workers=self.config.max_workers) as executor:
future_to_sample = {
executor.submit(self.evaluate_single_sample, sample): sample
for sample in samples
}
# 使用tqdm显示进度
with tqdm(total=len(samples), desc="批量评估") as pbar:
for future in as_completed(future_to_sample):
sample = future_to_sample[future]
try:
result = future.result()
results.append(result)
processed_count += 1
# 定期记录进度和内存使用
if processed_count % 10 == 0:
memory_usage = self._get_memory_usage()
logger.info(f"已处理 {processed_count}/{len(samples)} 个样本,内存使用: {memory_usage}")
except Exception as e:
logger.error(f"评估样本失败: {e}")
results.append(self._create_error_result(sample, str(e)))
processed_count += 1
pbar.update(1)
logger.info(f"批量评估完成,成功处理 {len([r for r in results if 'error' not in r])}/{len(samples)} 个样本")
return results
def run_evaluation(self, eval_data: List[Dict[str, Any]], use_parallel: bool = True) -> List[Dict[str, Any]]:
"""运行评估(兼容接口)"""
self.start_time = time.time()
logger.info("=" * 60)
logger.info("开始RAG评估")
logger.info(f"总样本数: {len(eval_data)}")
logger.info(f"使用并行处理: {use_parallel}")
logger.info(f"开始时间: {time.strftime('%Y-%m-%d %H:%M:%S')}")
logger.info("=" * 60)
try:
if use_parallel and len(eval_data) > 1:
results = self.evaluate_batch(eval_data)
else:
# 顺序处理
logger.info("使用顺序处理模式")
results = []
for i, sample in enumerate(tqdm(eval_data, desc="顺序评估")):
if i % 10 == 0:
memory_usage = self._get_memory_usage()
logger.info(f"处理进度: {i}/{len(eval_data)},内存使用: {memory_usage}")
results.append(self.evaluate_single_sample(sample))
total_time = time.time() - self.start_time
logger.info("=" * 60)
logger.info("RAG评估完成")
logger.info(f"总耗时: {total_time:.2f}秒")
logger.info(f"平均每个样本: {total_time / len(eval_data):.2f}秒")
logger.info(f"完成时间: {time.strftime('%Y-%m-%d %H:%M:%S')}")
logger.info("=" * 60)
return results
except Exception as e:
logger.error(f"评估过程中发生错误: {e}")
return []
def save_results_to_excel(self, original_df: pd.DataFrame, results: List[Dict[str, Any]],
output_path: str) -> pd.DataFrame:
"""将评估结果保存到Excel文件"""
logger.info(f"开始保存评估结果到: {output_path}")
start_time = time.time()
try:
# 复制原始DataFrame
result_df = original_df.copy()
# 添加评估结果列
result_df["faithfulness"] = [r.get("faithfulness", 0.0) for r in results]
result_df["answer_relevance"] = [r.get("answer_relevance", 0.0) for r in results]
result_df["context_precision"] = [r.get("context_precision", 0.0) for r in results]
result_df["context_recall"] = [r.get("context_recall", 0.0) for r in results]
# 如果有错误信息,也保存
error_count = sum(1 for r in results if "error" in r)
if error_count > 0:
result_df["error"] = [r.get("error", "") for r in results]
logger.warning(f"有 {error_count} 个样本评估出错")
# 确保输出目录存在
os.makedirs(os.path.dirname(output_path) if os.path.dirname(output_path) else ".", exist_ok=True)
# 保存到Excel
result_df.to_excel(output_path, index=False, engine='openpyxl')
save_time = time.time() - start_time
logger.info(f"评估结果已保存到: {output_path}")
logger.info(f"保存耗时: {save_time:.2f}秒")
# 打印统计信息
self._print_statistics(result_df)
return result_df
except Exception as e:
logger.error(f"保存结果到Excel时出错: {e}")
# 尝试使用不同的引擎
try:
result_df.to_excel(output_path, index=False, engine='xlsxwriter')
logger.info(f"使用xlsxwriter引擎保存成功: {output_path}")
return result_df
except Exception as e2:
logger.error(f"所有Excel引擎保存均失败: {e2}")
return None
def _print_statistics(self, result_df: pd.DataFrame):
"""打印评估统计信息"""
logger.info("=" * 60)
logger.info("评估结果统计")
logger.info("=" * 60)
metrics = ['faithfulness', 'answer_relevance', 'context_precision', 'context_recall']
for metric in metrics:
if metric in result_df.columns:
scores = result_df[metric].dropna()
if len(scores) > 0:
avg_score = scores.mean()
std_score = scores.std()
min_score = scores.min()
max_score = scores.max()
logger.info(f"{metric}: 平均={avg_score:.4f}, 标准差={std_score:.4f}, "
f"最小={min_score:.4f}, 最大={max_score:.4f}")
# 计算总体平均分
overall_scores = []
for metric in metrics:
if metric in result_df.columns:
scores = result_df[metric].dropna()
if len(scores) > 0:
overall_scores.extend(scores.values)
if overall_scores:
overall_avg = np.mean(overall_scores)
logger.info(f"总体平均分: {overall_avg:.4f}")
logger.info("=" * 60)
def _create_error_result(self, sample: Dict[str, Any], error_msg: str) -> Dict[str, Any]:
"""创建错误结果"""
return {
"question": sample.get("question", "未知问题"),
"answer": sample.get("answer", "未知答案"),
"faithfulness": 0.0,
"answer_relevance": 0.0,
"context_precision": 0.0,
"context_recall": 0.0,
"error": error_msg
}
def _extract_key_phrases(self, text: str, min_length: int = 2) -> List[str]:
"""提取关键短语(优化版本)"""
try:
if not text or not text.strip():
return []
words = jieba.cut(text)
phrases = [
word for word in words
if (len(word) >= min_length and
word not in self.stop_words and
re.match(r'^[\u4e00-\u9fff\w]+$', word))
]
return list(set(phrases))
except:
return re.findall(r'[\u4e00-\u9fff\w]{2,}', text)
def evaluate_faithfulness(self, contexts: List[str], answer: str) -> float:
"""评估答案的忠实度"""
try:
context_str = " ".join(contexts) if contexts else ""
if not contexts or not answer:
return 0.0
logger.debug("评估忠实度...")
if self.model is None:
score = self._rule_based_faithfulness(context_str, answer)
logger.debug(f"规则-based忠实度得分: {score:.3f}")
return score
prompt = f"""请严格评估答案是否基于上下文。只输出一个0-1的分数。
上下文: {context_str[:50000]}
答案: {answer[:50000]}
分数:"""
score = self._get_llm_score(prompt, temperature=0.1)
final_score = score if score is not None else self._rule_based_faithfulness(context_str, answer)
logger.debug(f"忠实度得分: {final_score:.3f}")
return final_score
except Exception as e:
logger.error(f"评估忠实度时出错: {e}")
context_str = " ".join(contexts) if contexts else ""
return self._rule_based_faithfulness(context_str, answer)
def _rule_based_faithfulness(self, context: str, answer: str) -> float:
"""基于规则的忠实度评估"""
try:
if not context or not answer:
return 0.0
context_lower = context.lower()
answer_lower = answer.lower()
context_phrases = set(self._extract_key_phrases(context_lower))
answer_phrases = self._extract_key_phrases(answer_lower)
if not answer_phrases:
return 0.0
overlapping = [phrase for phrase in answer_phrases if phrase in context_phrases]
overlap_ratio = len(overlapping) / len(answer_phrases)
if len(answer_phrases) > 3:
similarity = self._calculate_semantic_similarity(context, answer)
final_score = 0.7 * overlap_ratio + 0.3 * similarity
else:
final_score = overlap_ratio
return min(1.0, max(0.0, final_score))
except:
return 0.5
def _calculate_semantic_similarity(self, text1: str, text2: str) -> float:
"""计算语义相似度(带缓存)"""
if not text1 or not text2:
return 0.0
cache_key = hash(f"{text1}_{text2}")
if cache_key in self.similarity_cache:
return self.similarity_cache[cache_key]
try:
embeddings = self.get_embeddings_batch([text1, text2])
if len(embeddings) < 2:
return 0.0
similarity = cosine_similarity([embeddings[0]], [embeddings[1]])[0][0]
final_similarity = max(0.0, min(1.0, similarity))
self.similarity_cache[cache_key] = final_similarity
return final_similarity
except:
return 0.0
def evaluate_answer_relevance(self, question: str, answer: str) -> float:
"""评估答案相关性"""
try:
if not question or not answer:
return 0.0
logger.debug("评估答案相关性...")
direct_similarity = self._calculate_semantic_similarity(question, answer)
if self.model is None or direct_similarity > 0.8:
logger.debug(f"直接相似度得分: {direct_similarity:.3f}")
return direct_similarity
score = self._answer_relevance_with_qg(question, answer, direct_similarity)
logger.debug(f"答案相关性得分: {score:.3f}")
return score
except Exception as e:
logger.error(f"评估答案相关性时出错: {e}")
return self._calculate_semantic_similarity(question, answer) if question and answer else 0.0
def _answer_relevance_with_qg(self, question: str, answer: str, direct_similarity: float) -> float:
"""使用问题生成评估相关性"""
try:
prompt = f"基于答案生成相关问题:\n答案: {answer[:300]}\n生成2个问题:"
inputs = self.tokenizer.encode(prompt, return_tensors="pt").to(self.device)
with torch.no_grad():
outputs = self.model.generate(
inputs,
max_length=inputs.shape[1] + 80,
num_return_sequences=1,
temperature=0.7,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id
)
response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
generated_questions = []
lines = response.split('\n')
for line in lines:
line = line.strip()
if line and not line.startswith('基于答案'):
generated_questions.append(line)
if len(generated_questions) < 1:
return direct_similarity
all_texts = [question] + generated_questions[:2]
embeddings = self.get_embeddings_batch(all_texts)
if len(embeddings) < 2:
return direct_similarity
question_embedding = embeddings[0:1]
generated_embeddings = embeddings[1:]
similarities = cosine_similarity(question_embedding, generated_embeddings)[0]
qg_similarity = np.mean(similarities) if len(similarities) > 0 else 0.0
combined_score = 0.4 * direct_similarity + 0.6 * qg_similarity
return max(0.0, min(1.0, combined_score))
except:
return direct_similarity
def evaluate_context_precision(self, contexts: List[str], answer: str, reference: str = None) -> float:
"""评估上下文精确度"""
try:
context_str = " ".join(contexts) if contexts else ""
if not contexts:
return 0.0
logger.debug("评估上下文精确度...")
if self.model is None:
score = self._rule_based_context_precision(context_str, answer)
logger.debug(f"规则-based精确度得分: {score:.3f}")
return score
if reference:
prompt = f"上下文与参考答案的相关性(0-1):\n参考: {reference[:300]}\n上下文: {context_str[:500]}\n分数:"
else:
prompt = f"上下文与答案的相关性(0-1):\n答案: {answer[:300]}\n上下文: {context_str[:500]}\n分数:"
score = self._get_llm_score(prompt)
final_score = score if score is not None else self._rule_based_context_precision(context_str, answer)
logger.debug(f"上下文精确度得分: {final_score:.3f}")
return final_score
except Exception as e:
logger.error(f"评估上下文精确度时出错: {e}")
context_str = " ".join(contexts) if contexts else ""
return self._rule_based_context_precision(context_str, answer)
def _rule_based_context_precision(self, context: str, answer: str) -> float:
"""基于规则的上下文精确度评估"""
try:
if not context or not answer:
return 0.0
answer_phrases = self._extract_key_phrases(answer.lower())
context_lower = context.lower()
if not answer_phrases:
return 0.0
found_count = sum(1 for phrase in answer_phrases if phrase in context_lower)
precision = found_count / len(answer_phrases)
similarity = self._calculate_semantic_similarity(context, answer)
combined_score = 0.6 * precision + 0.4 * similarity
return min(1.0, max(0.0, combined_score))
except:
return 0.5
def evaluate_context_recall(self, contexts: List[str], reference: str) -> float:
"""评估上下文召回率"""
if not reference:
return 0.0
try:
context_str = " ".join(contexts) if contexts else ""
if not contexts:
return 0.0
logger.debug("评估上下文召回率...")
if self.model is None:
score = self._calculate_semantic_similarity(context_str, reference)
logger.debug(f"语义相似度召回率得分: {score:.3f}")
return score
prompt = f"""请评估参考答案中的信息在上下文中出现的比例。输出0-1的分数。
上下文: {context_str[:50000]}
参考答案: {reference[:50000]}
分数:"""
score = self._get_llm_score(prompt)
final_score = score if score is not None else self._calculate_semantic_similarity(context_str, reference)
logger.debug(f"上下文召回率得分: {final_score:.3f}")
return final_score
except Exception as e:
logger.error(f"评估上下文召回率时出错: {e}")
context_str = " ".join(contexts) if contexts else ""
return self._calculate_semantic_similarity(context_str, reference)
def _get_llm_score(self, prompt: str, temperature: float = 0.1) -> Optional[float]:
"""从LLM获取分数"""
if not self.model or not self.tokenizer:
return None
try:
inputs = self.tokenizer.encode(prompt, return_tensors="pt").to(self.device)
with torch.no_grad():
outputs = self.model.generate(
inputs,
max_length=inputs.shape[1] + 20,
num_return_sequences=1,
temperature=temperature,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id
)
response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
score = self._extract_score_from_text(response)
return score if score is not None else None
except:
return None
def _extract_score_from_text(self, text: str) -> Optional[float]:
"""从文本中提取分数"""
try:
score_match = re.search(r'(\d\.\d+)', text)
if score_match:
score = float(score_match.group(1))
if 0 <= score <= 1:
return score
percent_match = re.search(r'(\d+)%', text)
if percent_match:
return float(percent_match.group(1)) / 100.0
fraction_match = re.search(r'(\d+)/(\d+)', text)
if fraction_match:
numerator, denominator = int(fraction_match.group(1)), int(fraction_match.group(2))
if denominator > 0:
return numerator / denominator
return None
except:
return None
# 使用示例
if __name__ == "__main__":
# 配置参数
config = EvaluationConfig(
batch_size=16, #推理阶段一次喂给 GPU 的样本条数
max_length=512, #把输入 prompt 加输出结果的总 token 数限制在 512 以内
cache_embeddings=True, #把样本或参考答案的向量缓存到内存/磁盘
use_quantization=True, #启用量化(INT8/INT4)
max_workers=4 #评估阶段用 4 个进程/线程
)
# 初始化评估器
evaluator = OptimizedRAGEvaluator(
model_path="", # 生成模型路径
embedding_model_path="", # 嵌入模型路径
config=config
)
# 加载数据
excel_file_path = "1.xlsx"
eval_data, original_df = evaluator.load_data_from_excel(excel_file_path)
if not eval_data:
logger.error("无法加载评估数据")
exit(1)
# 批量评估
results = evaluator.run_evaluation(eval_data, use_parallel=True)
# 保存结果
output_path = "report/optimized_results.xlsx"
result_df = evaluator.save_results_to_excel(original_df, results, output_path)
if result_df is not None:
logger.info("评估完成!结果已保存到: " + output_path)
else:
logger.error("评估结果保存失败")按照以下条件优化程序数据需包含以下字段:
question:用户问题
answer:RAG 生成的答案
contexts:检索到的上下文(列表形式)
ground_truth:真实答案(用于 Context Recall)
RAGAs 提供四大关键指标(无需人工标注):
Faithfulness(忠实度):生成答案是否基于给定上下文(避免幻觉)。
定义:衡量生成答案与检索上下文的事实一致性。
计算方式:
faithfulness_score = (可推断的事实数) / (总事实数)
案例:答案含5个事实,其中4个可由上下文推断,则忠实度为0.8。
Answer Relevance(答案相关性):答案与问题的匹配程度。
定义:评估答案是否直接回答用户问题,避免冗余或偏离主题。
计算方式:
answer_relevancy_score = (相关模拟问题数) / (总模拟问题数)
实现:用LLM从答案生成多个问题变体,计算与原始问题的余弦相似度均值。
Context Precision(上下文精确度):检索内容是否包含答案关键信息。
定义:衡量检索到的上下文与问题之间的语义相关性。
计算方式:
context_relevance_score = (相关片段数) / (总片段数)
优化方向:调整检索策略(如混合稀疏/稠密检索)、优化分块策略(如按主题分块)。
Context Recall(上下文召回率):检索内容覆盖真实答案的程度(需 Ground Truth)。
定义:评估检索系统是否覆盖了回答问题的所有关键信息。
计算方式:
context_recall_score = (覆盖的关键信息数) / (总关键信息数)
案例:若问题需5个关键信息,检索到4个,则召回率为0.8。
指标分析:
高召回率但低忠实度:检索有效但生成模型未充分利用上下文,需优化Prompt或调整生成策略。
低答案相关性:可能因检索到冗余信息或生成模型跑题,需优化检索过滤或增加相关性约束。
优化方向:
检索层:混合检索(如BM25+向量检索)、动态调整Top-K候选数。
生成层:通过Prompt设计约束模型(如“严格基于上下文回答”)、引入奖励模型优化忠实度。
端到端:结合人类反馈强化学习(RLHF)对齐用户意图。





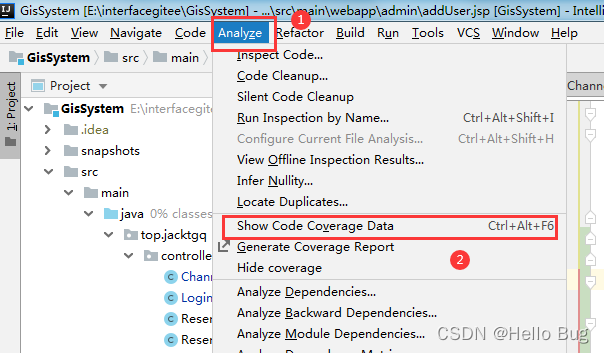
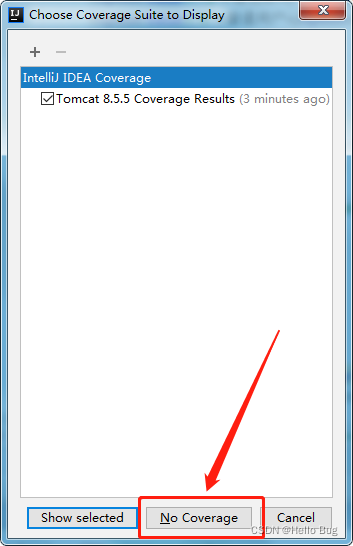
 本文详细介绍了如何通过快捷键【Ctrl+Alt+F6】解决IEDA监控中误触导致的覆盖率问题,包括步骤演示和NoCoverage页面操作。老手读者可互相交流经验。
本文详细介绍了如何通过快捷键【Ctrl+Alt+F6】解决IEDA监控中误触导致的覆盖率问题,包括步骤演示和NoCoverage页面操作。老手读者可互相交流经验。
 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























