



超多pdf文件名整合到一个表格文件中
代码展示
import os
#加载os库,用于读取文件和目录
data = r'D:\迅雷下载\B题-特殊医学用途配方食品数据分析\数据\特医食品说明书'
#导入路径,保存到data变量中
pdf_file = []
#新建一个空列表,用于存储整合文件名
for file in os.listdir(data):
#for循环遍历,os.listdir(data)返回当前目录下的所有文件及子目录的名称列表
if file.endswith('.pdf'):
pdf_file.append(file)
#判断:如果文件后缀名是.pdf,那就把它加入到列表的末尾位置
print(pdf_file)
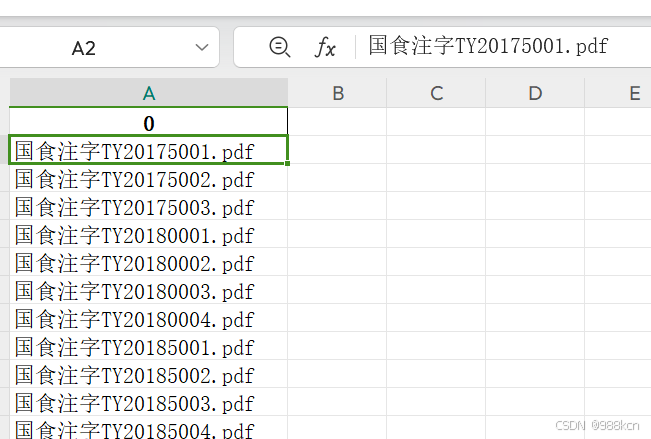
保存为Excel文件
import pandas as pd
pdf_file = pd.DataFrame(pdf_file)
pdf_file.to_excel('pdf_file.xlsx', index=False)
…………我会陆续更新处理PDF内容的部分
我很乐于助人,也想要得到成长,如果看到这篇帖子的友友们有需要处理的数据,可以私信博主帮忙(点个小赞就好)


















 4026
4026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









