



社区王牌专栏《一问一实验:AI 版》改版以来已发布多期(51-58),展现了 ChatDBA 在多种场景下解决问题的效果。目前我们已经开放了第一批定邀用户进行体验,如果您希望快速体验到 ChatDBA 的能力,欢迎在文末填写自己的联系方式。
温馨提示,信息填写的越完整,审核速度越快哦~
下面让我们正式进入《一问一实验:AI 版》的第 59 期。

问题
OceanBase NTP 时钟不同步的问题排查?
问题现象: OBServer 服务器 NTP 时钟同步异常,导致 OBServer 无法正常启动。
下面我们将带着问题,与 ChatDBA 进行四轮交互,精彩内容即将开始~
实验
ChatDBA 演示视频,第一时间同步社区视频号及哔哩哔哩,欢迎关注。
ChatDBA 专家模式
专家模式在第一轮对话开始后,会根据问题生成【根因分析树】,展示 ChatDBA 对问题的排查逻辑,方便启发 DBA 快速定位问题。

第一轮交互
将故障问题的输入给 ChatDBA。
ChatDBA 会根据问题生成 初步参考结果。
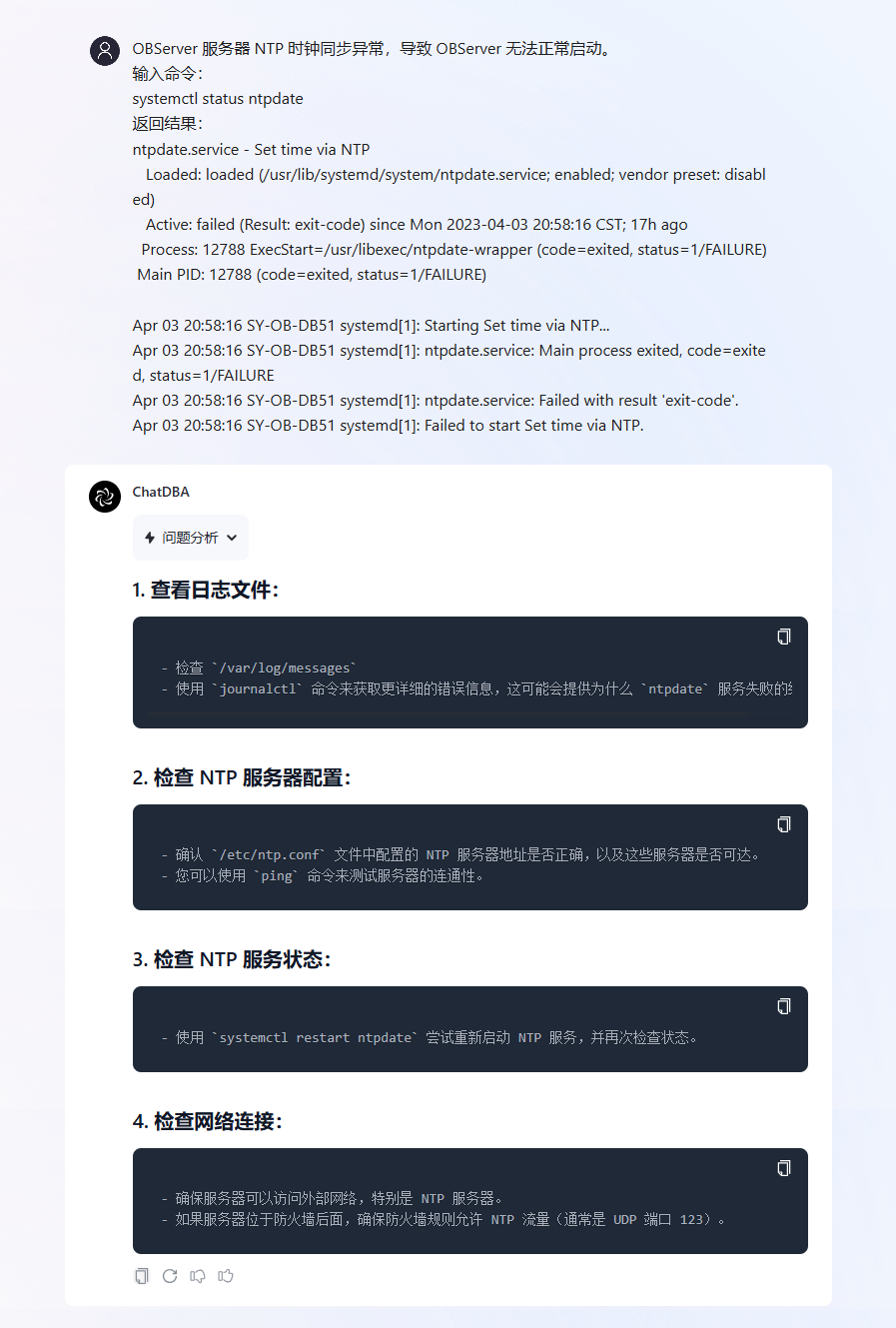
ChatDBA 给出排查步骤,提醒需要收集 journalctl 日志 来进一步分析,同时给出具体的查询命令以及需要重点观察的内容。
第二轮交互
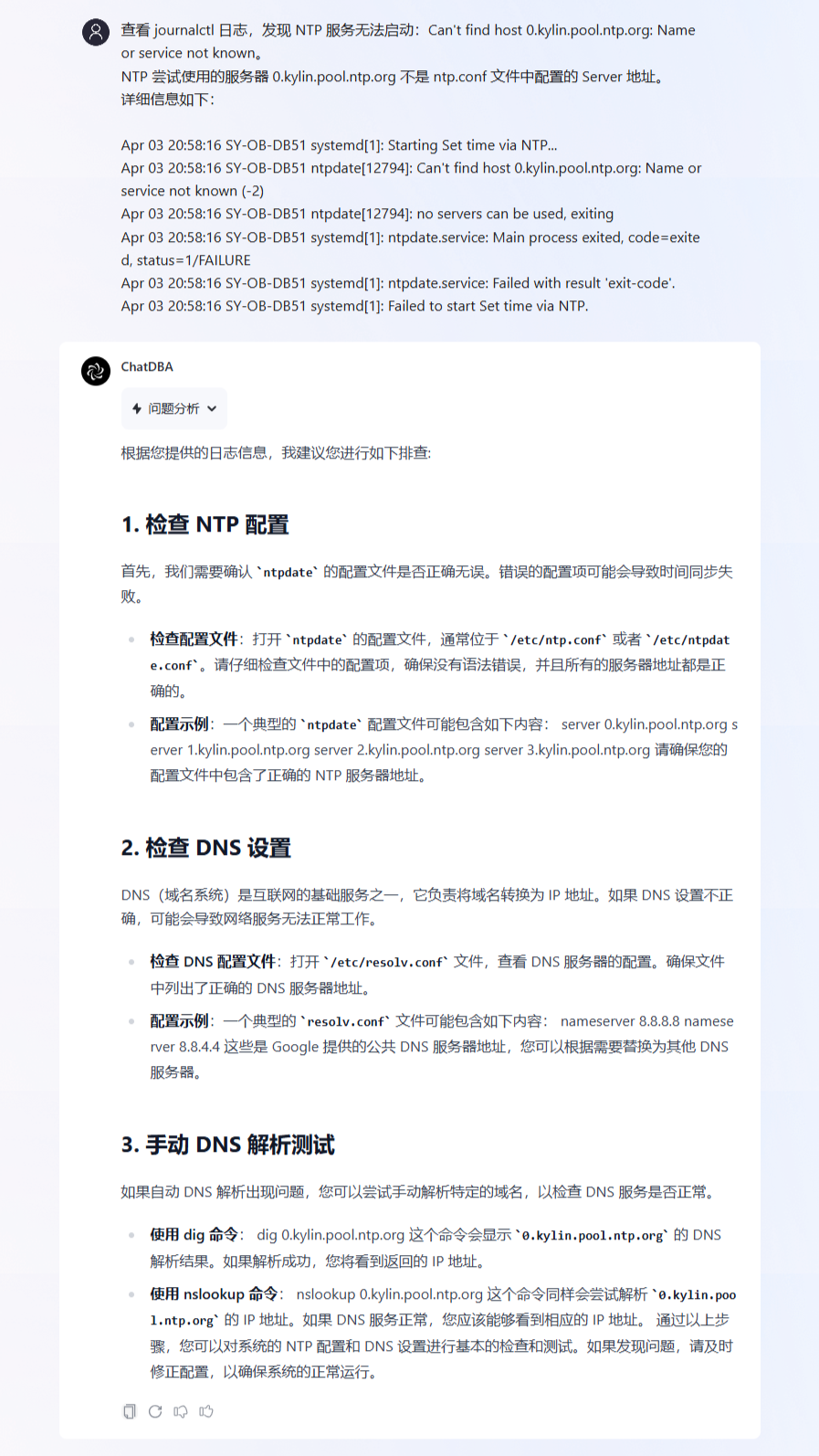
根据上一轮 ChatDBA 给出的排查步骤,查询 journalctl 日志并输入给 ChatDBA。
ChatDBA 根据 journalctl 日志报错信息,需要我们排查 ntpdate 配置文件以及DNS设置,以便于继续排查问题产生原因。
第三轮交互
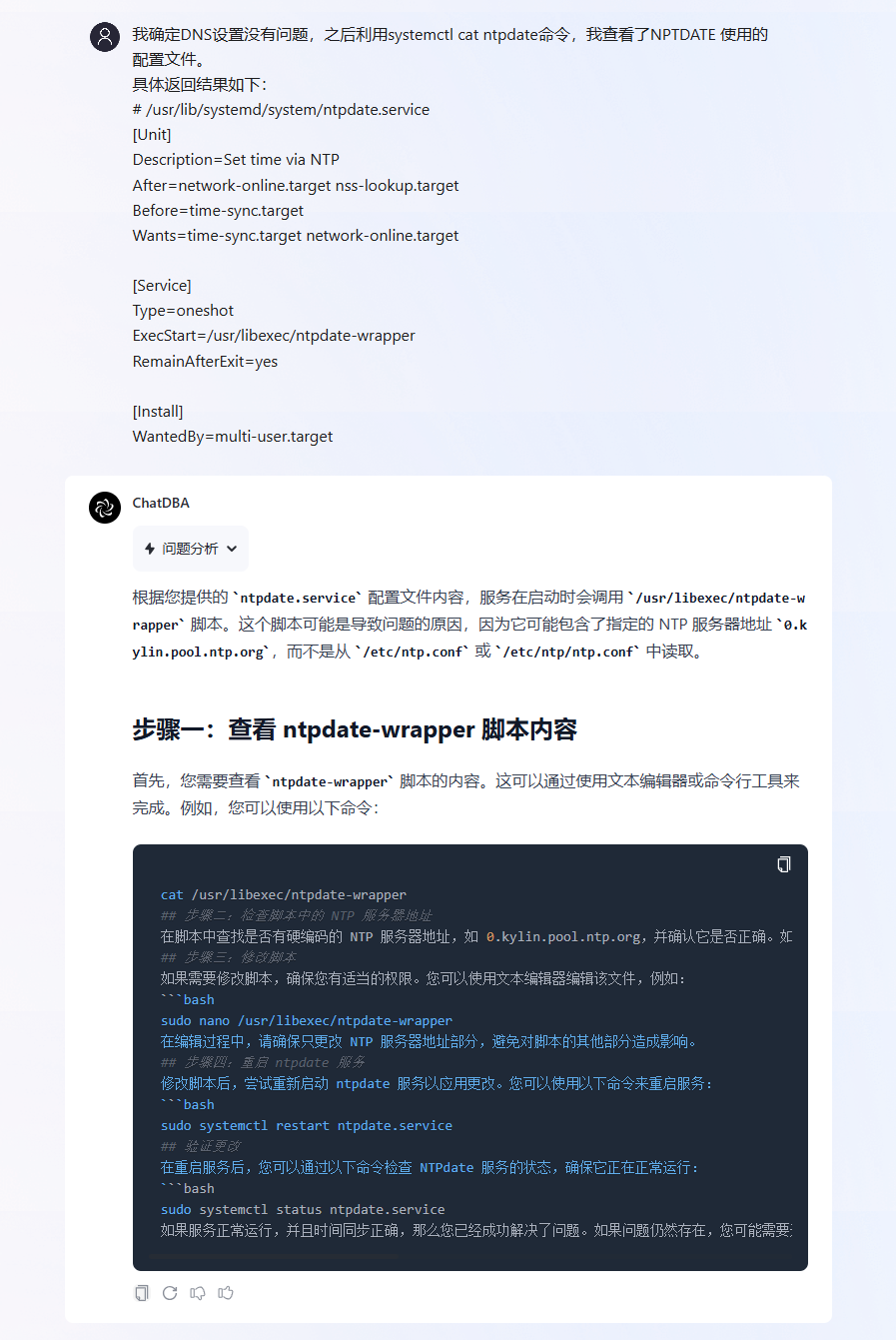
根据上一轮 ChatDBA 给出的排查步骤,我们将排查的结果以及对应 ntpdate 配置文件信息给到 ChatDBA。
ChatDBA 根据我们提供的结论以及 ntpdate 配置信息,初步确定可能由于调用 ntpdate-wrapper 脚本导致的问题。ChatDBA 建议我们查看 ntpdate-wrapper 脚本文件信息。
第四轮交互
根据 ChatDBA 给出的提示,我们查看了 ntpdate-wrapper 脚本内容。发现其中不但引入了 ntp.conf 文件还引用了 step-tickers 文件,并且会优先从 step-tickers 中获取 IP 信息。在查看了 step-tickers 文件后,我们发现了 0.kylin.pool.ntp.org,与日志报错信息一致。因此基本确定了问题产生原因。
将上述情况告知 ChatDBA,获取解决方案。

最终,ChatDBA 根据我们提供的信息,确定了问题的产生原因并向用户提供了解决方案,问题得到解决。
实验总结
OceanBase NTP 时钟不同步可能由以下几个原因造成:
NTP 服务配置问题: 如果 NTP 服务无法启动,可能是因为配置文件中指定的 NTP 服务器地址不正确或无法访问。例如,如果 ntpdate 服务尝试使用的服务器不是 ntp.conf 文件中配置的 Server 地址,就会导致服务启动失败。
DNS 解析问题: 如果 NTP 服务报告无法找到主机,可能是因为 DNS 解析问题。例如,日志中显示 Can't find host 0.kylin.pool.ntp.org: Name or service not known,这表明 NTP 尝试使用的服务器地址无法被解析。
配置文件错误: 如果 ntpdate-wrapper 脚本或 ntp.conf 配置文件中有错误,也可能导致 NTP 服务无法正常工作。例如,如果 step-tickers 文件中填写了错误的 NTP 服务器地址,而该文件会被 ntpdate 服务优先使用,就会导致时钟同步失败。
网络问题: 如果网络连接不稳定或配置不当,也可能导致 NTP 服务无法与 NTP 服务器通信,从而无法同步时间。
权限问题: 如果 NTP 服务没有以正确的用户权限运行,也可能导致服务启动失败。
时钟源问题: OceanBase 集群的正常运行依赖稳定的时钟源。如果使用的是虚拟机而不是物理机,可能会导致时间不稳定,从而影响时钟同步。
NTP 服务未以正确的模式启动: NTP 服务需要以 -x 模式启动(slew mode),以保证在有时钟偏差的情况下可以缓慢调整偏移。如果没有以这种模式启动,可能会导致时钟同步问题。
本次出现的问题是由于配置文件错误,导致的问题产生。
NTP 服务配置详解
网络时间协议(NTP)服务通过配置文件 ntp.conf 来确保系统时间的准确性,文件列出了多个时钟服务器地址,以便在主服务器不可用时自动切换到备用服务器。另外,step-tickers 文件,用于指定当系统时间偏差较大时,NTPDATE 工具使用的时钟服务器。
通常情况下,step-tickers 文件为空,这时 NTPDATE 会使用 ntp.conf 中的服务器。如果 step-tickers 文件中指定了服务器,NTPDATE 会优先使用这些服务器来同步时间。这也是产生本次问题的根本原因。因此,为了避免 NTPD 和 NTPDATE 服务使用不同的配置文件,有时需要注释掉 step-tickers 文件中的域名信息。
什么是 ChatDBA?

更多技术文章,请访问:https://opensource.actionsky.com/
关于 SQLE
SQLE 是一款全方位的 SQL 质量管理平台,覆盖开发至生产环境的 SQL 审核和管理。支持主流的开源、商业、国产数据库,为开发和运维提供流程自动化能力,提升上线效率,提高数据质量。
✨ Github:https://github.com/actiontech/sqle
📚 文档:https://actiontech.github.io/sqle-docs/
💻 官网:https://opensource.actionsky.com/sqle/
👥 微信群:请添加小助手加入 ActionOpenSource

















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









