




项目名称:Python音乐推荐系统(协同过滤算法)
项目功能: 📖 1:用户登陆注册,2:全部音乐的展示,3:基于协同过滤算法和Svg算法的推荐音乐展示,3:根据被用户收藏喜欢的次数的热门音乐展示,4:根据数据库相关字段的音乐数据可视化展示,5:个人中心页面的展示,6:音乐的播放和动画,7:管理员后台的实现~
项目涉及技术:Python,Django,MySQL,协同过滤算法,Bootstrap,前端...
项目核心代码展示:
数据库表(项目的数据字段)
from django.contrib.auth.models import User
from django.db import models
# 用户信息
class UserProfile(models.Model):
user = models.OneToOneField(User, on_delete=models.CASCADE)
likes = models.ManyToManyField('Music', blank=True, related_name='like_users')
dislikes = models.ManyToManyField('Music', blank=True, related_name='dislike_users')
first_run = models.BooleanField('是否第一次运行,执行冷启动策略', default=True)
genre_subscribe = models.TextField('流派订阅', blank=True)
language_subscribe = models.TextField('语言订阅', blank=True)
def __str__(self):
return self.user.username
class Meta:
verbose_name = '用户信息'
verbose_name_plural = verbose_name
# 音乐
class Music(models.Model):
song_name = models.CharField('歌曲名称', max_length=1000)
song_length = models.IntegerField('歌曲长度 单位为ms')
genre_ids = models.CharField('歌曲流派', max_length=100)
artist_name = models.CharField('歌手', max_length=1000)
composer = models.CharField('作曲', max_length=1000)
lyricist = models.CharField('作词', max_length=1000)
language = models.CharField('语种', max_length=20)
url = models.CharField('歌曲链接', max_length=1000, default="https://m701.music.126.net/20240301234259/3c4c6553837086cd21eb6013475d9d05/jdymusic/obj/wo3DlMOGwrbDjj7DisKw/27978919250/663c/4088/7b7a/0c48207cb013f953f46fe2da7dd7f803.mp3")
def __str__(self):
return self.song_name
class Meta:
verbose_name = '音乐信息'
verbose_name_plural = verbose_name
路由(项目的页面站点)
from django.conf import settings
from django.conf.urls.static import static
from django.contrib import admin
from django.urls import path, include
from music import views
# 主路由
urlpatterns = [
path('grappelli/', include('grappelli.urls')), # 后台
path('admin/', admin.site.urls), # 后台
path('', views.home), # 首页
path('recommend', views.recommend), # 推荐
path('get_top_liked_music', views.get_top_liked_music), # 热门音乐
path('music_realize', views.music_realize), # 音乐可视化
path('sign_in', views.sign_in), # 登录
path('sign_up', views.sign_up), # 注册
path('logout', views.user_logout), # 退出
path('like/<int:pk>', views.like), # 喜欢
path('dislike/<int:pk>', views.dislike), # 不喜欢
path('play', views.play), # 播放
path('play/<int:pk>', views.play), # 播放
path('user', views.user_center), # 用户中心
path('search', views.search), # 搜索
]
urlpatterns += static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)
urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)
后端业务:
recommend.py
import os
import django
import pandas as pd
from django.contrib import messages
from django.http import HttpRequest
from surprise import Dataset, Reader, Prediction
from surprise import SVD
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "MusicRecommendSystem.settings")
django.setup()
from django.contrib.auth.models import User
from music.models import UserProfile, Music
current_request = None
'''
SVD(Singular Value Decomposition)是一种基于矩阵分解的算法,通常用于推荐系统中的评分预测。
在Surprise库中的SVD算法采用了隐式反馈数据来进行预测。
SVD算法的基本原理是将用户-物品评分矩阵分解为多个低秩矩阵的乘积,从而捕捉用户和物品的隐含特征。
SVD算法的原理步骤:
1. 隐含特征表示:SVD将用户-物品评分矩阵分解为三个矩阵的乘积,即U、S和V^T。
其中,U矩阵表示用户的隐含特征,S矩阵为奇异值矩阵,V^T矩阵表示物品的隐含特征。
2. 降维处理:奇异值矩阵S中的奇异值按降序排列,取前k个奇异值,可以实现对矩阵的降维处理。这样可以减少计算量,并聚焦于较重要的特征。
3. 重构评分矩阵:将U、S和V^T的前k列分别取出,构成降维后的矩阵。然后将它们相乘,再根据需要减去均值,即可得到重构的评分矩阵。
4. 预测评分:利用重构的评分矩阵,可以预测用户对未评分物品的评分。
预测评分的方法可以是简单的矩阵相乘,也可以加入一些调整因子如全局偏差、用户偏差和物品偏差等。
通过以上步骤,SVD算法可以在用户-物品评分矩阵的基础上,对未评分物品进行预测。
预测的评分值可以用于推荐系统中的排序和推荐过程。
需要注意的是,SVD算法在处理大规模数据时可能会面临内存和计算效率的问题。
'''
# 获取数据库中所有用户数据
def build_df():
data = []
for user_profile in UserProfile.objects.all(): # 获取所有的用户信息
for like_music in user_profile.likes.all(): # 循环获取所有用户喜欢的歌曲
data.append([user_profile.user.id, like_music.pk, 1]) # 保存数据data = [[1,1,1],]
for dislike_music in user_profile.dislikes.all(): # 循环获取所有用户不喜欢的歌曲
data.append([user_profile.user.id, dislike_music.pk, 0]) # 保存数据data = [[1,2,0]]
return pd.DataFrame(data, columns=['userID', 'itemID', 'rating']) # 存储格式
'''
userID itemID rating
2 1 1
2 4 1
2 9 1
2 2 0
2 3 0
... ... ...
'''
# 根据用户的评分数据来构建预测模型,并返回一组推荐的音乐列表
def build_predictions(df: pd.DataFrame, user: User):
userId = user.id # 获取用户的ID
profile = UserProfile.objects.filter(user=user) # 查找用户的个人资料信息
if profile.exists():
profile_obj: UserProfile = profile.first()
else:
return []
# print("profile", profile) # <QuerySet [<UserProfile: wyucnk>]>
# 使用Surprise库中的Reader和Dataset类来构建评分数据集
# 指定评分范围为0到1之间的连续值
reader = Reader(rating_scale=(0, 1))
# 将数据加载到评分数据集中
data = Dataset.load_from_df(df[['userID', 'itemID', 'rating']], reader)
# 使用评分数据集构建训练集
trainset = data.build_full_trainset()
# 创建一个SVD算法对象
algo = SVD()
# 通过algo.fit(trainset)方法训练算法,将训练集数据拟合到算法中
# 训练完毕
algo.fit(trainset)
# 取出当前所有有人评分过的歌曲,并去重
subsets = df[['itemID']].drop_duplicates()
# print('subsets', subsets)
'''
itemID
1
4
9
2
3
...
'''
# 测试集
testset = []
# 从评分数据中提取出所有被评分过的音乐,并将其作为测试集
for row in subsets.iterrows():
# 测试集中的评分值被设置为0,因为我们只是想预测用户是否会喜欢这些音乐,而不关心具体的评分值。
testset.append([userId, row[1].values[0], 0])
# print('testset', testset)
'''
[[4, 1, 0], [4, 4, 0], [4, 9, 0], [4, 2, 0], [4, 3, 0], [4, 5, 0], [4, 19, 0], [4, 21, 0], [4, 63, 0],
'''
# 用训练好的算法对测试集进行预测,返回一个包含预测结果的列表
predictions = algo.test(testset, verbose=True)
# print('predictions', predictions)
'''
预测结果:用户id为4的用户对物品id为1的物品的评分预测为0.8837081860340208
r_ui表示实际评分为0,est表示预测评分为0.8837081860340208。
details中的was_impossible为False表示该预测能够完成,不是不可能的预测。
[Prediction(uid=4, iid=1, r_ui=0, est=0.8837081860340208, details={'was_impossible': False}),
'''
result_set = []
user_like = profile_obj.likes.all() # 当前用户喜欢的
user_dislike = profile_obj.dislikes.all() # 当前用户不喜欢的
# 遍历所有预测结果
for item in predictions:
prediction: Prediction = item
# 对于预测评分高于0.99的音乐,它从数据库中获取相应的音乐对象
if prediction.est > 0.99:
music = Music.objects.get(pk=prediction.iid)
# 检查是否用户已经喜欢或不喜欢该音乐,如果是,则跳过该音乐。
if music in user_like:
continue
if music in user_dislike:
continue
result_set.append(music)
if len(result_set) == 0:
messages.error(current_request, '你听的歌太少了,多听点歌再来吧~')
# print('result_set', result_set)
'''
[<Music: 愛我的資格>, <Music: 裂縫中的陽光 (Before Sunrise)>, <Music: PLAYING WITH FIRE>,
'''
return result_set
# 获取用户流派推荐
def build_genre_predictions(user: User):
predictions = []
profile = UserProfile.objects.filter(user=user) # 用户信息
if profile.exists():
profile_obj: UserProfile = profile.first()
else:
return predictions
genre_subscribe = profile_obj.genre_subscribe.split(',') # 获取用户订阅的流派
user_like = profile_obj.likes.all() # 获取用户喜欢的音乐
user_dislike = profile_obj.dislikes.all() # 获取用户不喜欢的音乐
# 查找遍历用户喜欢流派的所有音乐
for music in Music.objects.filter(genre_ids__in=genre_subscribe):
if music in user_like:
continue
if music in user_dislike:
continue
predictions.append(music)
return predictions
# 构建语言推荐
def build_language_predictions(user: User):
predictions = []
profile = UserProfile.objects.filter(user=user)
if profile.exists():
profile_obj: UserProfile = profile.first()
else:
return predictions
language_subscribe = profile_obj.language_subscribe.split(',') # 获取用户喜欢的语言
user_like = profile_obj.likes.all()
user_dislike = profile_obj.dislikes.all()
for music in Music.objects.filter(language__in=language_subscribe):
if music in user_like:
continue
if music in user_dislike:
continue
predictions.append(music)
return predictions
# 构建推荐
def build_recommend(request: HttpRequest, user: User):
global current_request
current_request = request
predictions = []
predictions.extend(build_predictions(build_df(), user)) # 算法预测
if not predictions:
predictions.extend(build_genre_predictions(user)) # 流派推荐
predictions.extend(build_language_predictions(user)) # 语言推荐
return predictions
if __name__ == '__main__':
# print(build_df()) # 获取用户数据
print(build_predictions(build_df(), User.objects.get(pk=4))) # 算法推荐
print(build_genre_predictions(User.objects.get(pk=4))) # 流派推荐
print(build_language_predictions(User.objects.get(pk=4))) # 语言推荐
view.py
from django.contrib import messages
from django.contrib.auth import authenticate, login, logout
from django.contrib.auth.decorators import login_required
from django.contrib.auth.models import User
from django.core.paginator import Paginator
from django.http import HttpResponseRedirect
from django.shortcuts import render, get_object_or_404
from django.db.models import Count
from .decorators import cold_boot
from .models import Music, UserProfile
from .recommend import build_recommend
from .subscribe import build_genre_ids, build_languages
from django.db.models import Count, F, Value
from django.db.models.functions import Coalesce
from collections import defaultdict
# 当前播放
current_play = None
# 当前推荐
current_recommend = []
# 首页
def home(request):
return all(request)
@cold_boot
def all(request):
page_number = request.GET.get('page', 1)
queryset = Music.objects.all()
paginator = Paginator(queryset, 10) # 分页
musics = paginator.page(page_number)
context = {
'musics': musics,
'user_likes': [],
'user_dislikes': []
}
# 如果登录的首页
if request.user.is_authenticated:
user_profile = UserProfile.objects.filter(user=request.user)
if user_profile.exists():
user_profile = user_profile.first() # 用户信息
context['user_likes'] = user_profile.likes.all() # 获取用户喜欢或不喜欢的数据
context['user_dislikes'] = user_profile.dislikes.all()
return render(request, 'list.html', context)
# 注册
def sign_up(request):
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('password')
if User.objects.filter(username=username).exists():
messages.add_message(request, messages.ERROR, '该用户已存在!')
else:
user_obj = User.objects.create_user(username=username, password=password)
UserProfile.objects.create(user=user_obj)
messages.add_message(request, messages.SUCCESS, '注册成功!')
return HttpResponseRedirect('/sign_in')
return render(request, 'sign_up.html')
# 登录
def sign_in(request):
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('password')
user = authenticate(request, username=username, password=password)
if user is not None:
login(request, user=user)
messages.success(request, '登录成功')
return HttpResponseRedirect('/')
else:
messages.add_message(request, messages.ERROR, '用户名或密码错误!')
return HttpResponseRedirect('/')
else:
return render(request, 'sign_in.html')
# 退出登录
@login_required(login_url='/sign_in')
def user_logout(request):
logout(request)
messages.info(request, '退出登录')
return HttpResponseRedirect('/')
@login_required(login_url='/sign_in')
@cold_boot
def recommend(request):
page_number = request.GET.get('page', 1)
# -------------------- 推荐 --------------------------
recommend_set = build_recommend(request, request.user) # 获取推荐的数据
# -------------------- 推荐 --------------------------
paginator = Paginator(recommend_set, 10) # 分页
musics = paginator.page(page_number) # 推荐的音乐
context = {
'musics': musics,
'user_likes': [],
'user_dislikes': []
}
user_profile = UserProfile.objects.filter(user=request.user)
if user_profile.exists():
user_profile = user_profile.first()
context['user_likes'] = user_profile.likes.all()
context['user_dislikes'] = user_profile.dislikes.all()
return render(request, 'list.html', context)
# 用户添加喜欢
@login_required(login_url='/sign_in')
def like(request, pk: int):
user_obj = UserProfile.objects.get(user=request.user)
music_obj = get_object_or_404(Music.objects.all(), pk=pk) # 通过id查找歌曲信息
user_obj.likes.add(music_obj) # 添加喜欢
user_obj.dislikes.remove(music_obj) # 删除不喜欢
messages.add_message(request, messages.INFO, '已经添加到我喜欢')
redirect_url = request.GET.get('from', '/')
if 'action' in request.GET:
redirect_url += f'&action={request.GET["action"]}'
return HttpResponseRedirect(redirect_url)
# 用户添加不喜欢
@login_required(login_url='/sign_in')
def dislike(request, pk: int):
user_obj = UserProfile.objects.get(user=request.user)
music_obj = get_object_or_404(Music.objects.all(), pk=pk) # 通过id查找歌曲信息
user_obj.dislikes.add(music_obj) # 添加到不喜欢
user_obj.likes.remove(music_obj) # 删除喜欢
messages.add_message(request, messages.INFO, '已经添加到我不喜欢')
redirect_url = request.GET.get('from', '/')
if 'action' in request.GET:
redirect_url += f'&action={request.GET["action"]}'
return HttpResponseRedirect(redirect_url)
# 播放歌曲
def play(request, pk: int = 0):
global current_play
if pk > 0: # 存在id
music_obj = Music.objects.filter(pk=pk)
if music_obj.exists():
current_play = music_obj.first()
if current_play is None:
messages.error(request, '当前没有正在播放的音乐')
return HttpResponseRedirect('/')
return render(request, 'play.html', context={
'music': current_play
})
# 用户信息
@login_required(login_url='/sign_in')
def user_center(request):
user_profile = UserProfile.objects.filter(user=request.user)
if user_profile.exists():
profile_obj: UserProfile = user_profile.first()
else:
messages.error(request, '找不到用户资料,请重新登录')
logout(request)
return HttpResponseRedirect('/')
# 添加个人信息
if request.method == 'POST':
genres = request.POST.getlist('genres', '')
languages = request.POST.getlist('languages', '')
profile_obj.first_run = False
if len(genres) > 0:
profile_obj.genre_subscribe = ','.join(genres)
profile_obj.save()
messages.success(request, '修改流派订阅成功!')
elif not profile_obj.first_run:
profile_obj.genre_subscribe = ''
profile_obj.save()
messages.success(request, '修改流派订阅成功!')
if len(languages) > 0:
profile_obj.language_subscribe = ','.join(languages)
profile_obj.save()
messages.success(request, '修改语言订阅成功!')
elif not profile_obj.first_run:
profile_obj.language_subscribe = ''
profile_obj.save()
messages.success(request, '修改语言订阅成功!')
context = {
'user_likes': profile_obj.likes.all(),
'user_dislikes': profile_obj.dislikes.all(),
'genres': build_genre_ids(),
'languages': build_languages(),
'genre_subscribe': profile_obj.genre_subscribe.split(','),
'language_subscribe': []
}
# 去除空字符
for lang in profile_obj.language_subscribe.split(','):
lang = lang.strip()
context['language_subscribe'].append(lang)
return render(request, 'user.html', context=context)
# 搜索歌曲
def search(request):
if 'keyword' not in request.GET:
messages.error(request, '请输入搜索关键词')
return HttpResponseRedirect('/')
keyword = request.GET.get('keyword')
action = request.GET.get('action')
# 两种方式搜索
musics = []
if action == 'song_name':
musics = Music.objects.filter(song_name__contains=keyword)
if action == 'artist_name':
musics = Music.objects.filter(artist_name__contains=keyword)
messages.info(request, f'搜索关键词:{keyword},找到 {len(musics)} 首音乐')
context = {
'musics': musics,
'user_likes': [],
'user_dislikes': []
}
if request.user.is_authenticated:
user_profile = UserProfile.objects.filter(user=request.user)
if user_profile.exists():
user_profile = user_profile.first()
context['user_likes'] = user_profile.likes.all()
context['user_dislikes'] = user_profile.dislikes.all()
return render(request, 'list.html', context)
def get_top_liked_music(request):
def get_top_liked_musics():
# 获取所有被喜欢的歌曲及其喜欢数量
top_liked_musics = Music.objects.filter(
like_users__isnull=False # 确保只考虑有用户喜欢的歌曲
).annotate(
like_count=Count('like_users') # 计算每首歌曲的喜欢数量
).order_by('-like_count') # 按喜欢数量降序排序
return top_liked_musics[:50]
# 使用示例
top_liked_musics = get_top_liked_musics()
for music in top_liked_musics:
print(f"歌曲名称: {music.song_name}")
print(f"被标记为喜欢的用户数量: {music.like_count}")
# 如果需要,您可以继续打印其他字段
# print(f"歌曲长度: {music.song_length} ms")
# ...(其他字段)
print("---")
context = {'top_liked_musics': top_liked_musics}
return render(request,'get_top_liked_music.html',context)
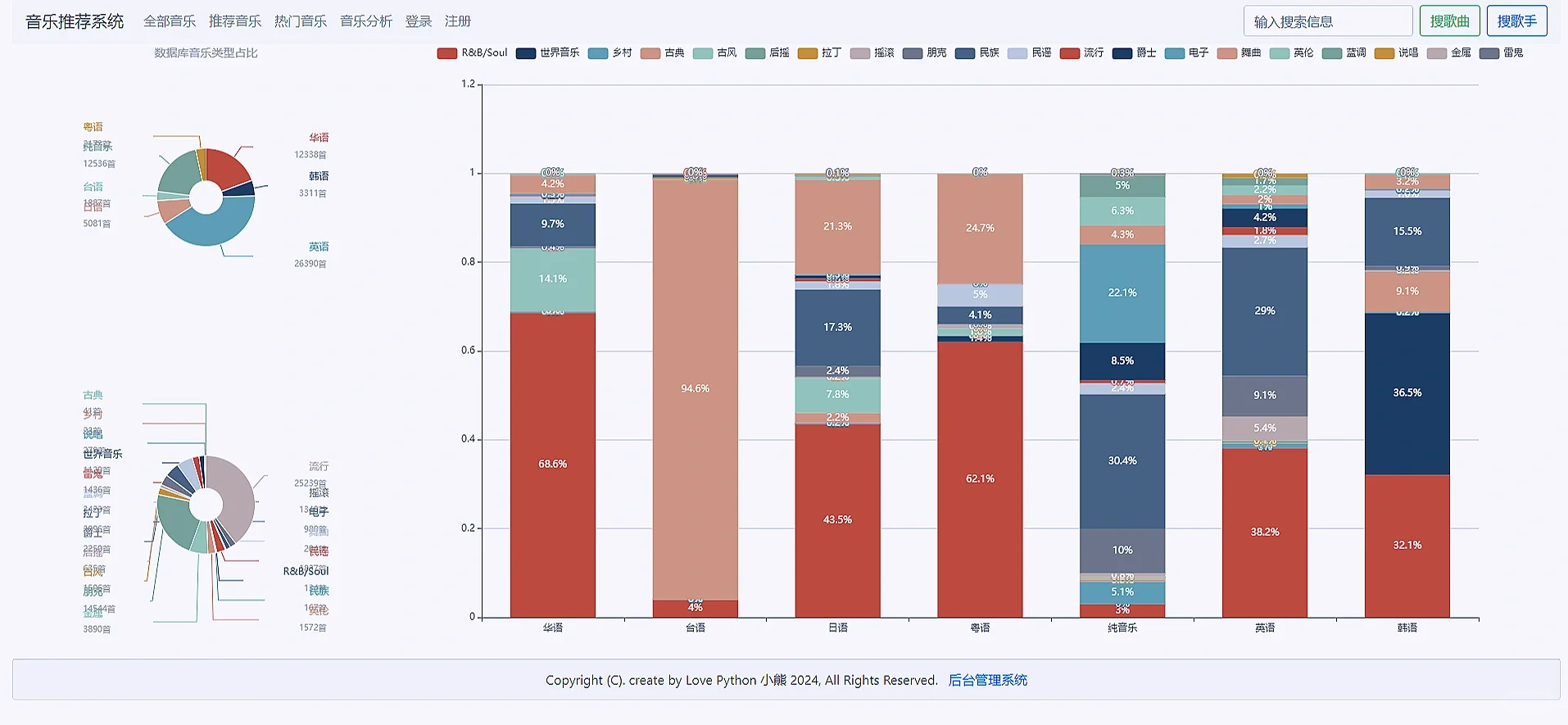
# 音乐可视化分析
def music_realize(request):
# 使用 defaultdict 来统计每个流派下每种语种的音乐数量
genre_language_counts = defaultdict(lambda: defaultdict(int))
# 用于存储所有唯一的流派和语种
all_genres = set()
all_languages = set()
# 查询所有音乐
for music in Music.objects.all():
genre = music.genre_ids
language = music.language
# 更新统计
genre_language_counts[genre][language] += 1
# 添加到唯一集合中
all_genres.add(genre)
all_languages.add(language)
# 将 defaultdict 转换为列表格式
result_list = []
for genre, languages in genre_language_counts.items():
sublist = [languages.get(lang, 0) for lang in sorted(all_languages)] # 使用 sorted 确保顺序一致
result_list.append(sublist)
# 将集合转换为列表
genres_list = sorted(list(all_genres))
languages_list = sorted(list(all_languages))
print(languages_list)
print(genres_list)
print(result_list)
##############################
# 使用 values 和 annotate 方法进行分组和计数
language_counts = Music.objects.values('language').annotate(count=Count('id'))
# 将查询结果转换为字典列表
result_language = [{'name': item['language'], 'value': item['count']} for item in language_counts]
for item in result_language:
print(item)
################################
# 使用 values 和 annotate 方法进行分组和计数
genre_counts = Music.objects.values('genre_ids').annotate(count=Count('id'))
# 将查询结果转换为字典列表
result_genre = [{'name': item['genre_ids'], 'value': item['count']} for item in genre_counts]
for item in result_genre:
print(item)
context = {'genres_list': genres_list, 'languages_list':languages_list, 'result_list':result_list,'result_genre':result_genre, 'result_language':result_language}
return render(request, 'music_realize.html',context)
项目部分截图:
 最后:项目可以私信我,项目简单,适合学习参考和二次修改开发~
最后:项目可以私信我,项目简单,适合学习参考和二次修改开发~




















 4075
4075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











