




1 前言:
今天跟大家分享又一款的招聘岗位的数据分析可视化项目,上一次是针对boss直聘的这一次的主要分析智联招聘岗位的,实现的功能基本上都大差不差,无非就是换了一个目标,网站字段也都是差不多的~
☀️ 项目简介: 1️⃣ 项目名称:基于django的智联招聘数据可视化分析. 2️⃣ 项目实现功能:1、用户登录注册,2、个人信息编辑以及个人密码修改,3、数据分页总览以及实现了用户可以对心仪岗位进行收藏和删除,4、首页大屏展示了用户的注册数据以及数据库中所有岗位数据的基本属性数据,5、针对爬取的岗位数据的各个字段做可视化图表分析处理. 3️⃣ 项目涉及技术:Python、Django、mysql、Echarts,爬虫.
最后:需要这个项目的同学可以私信我~
2 项目设计
2.1 爬虫
本项目的数据是使用Python爬虫技术从指定目标网站(智联招聘)上爬取岗位数据,如岗位名字,薪资,人数,性质,工作标签,公司福利,企业性质,详情链接等一些列字段,爬虫技术用到selenium自动化测试来获取,将数据存储到csv和mysql数据库中,详细代码如下:
import json
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
import csv
import pandas as pd
import os
import django
os.environ.setdefault('DJANGO_SETTINGS_MODULE', '智联招聘数据可视化分析.settings')
django.setup()
from myapp.models import *
class ZhilianSpider(object):
def __init__(self, job_type, page):
self.job_type = job_type
self.page = page
# https://www.zhaopin.com/sou/jl%E5%85%A8%E5%9B%BD/kw01O00U80EG06G03F01N5U02JQ4/p2?kt=3
self.spider_url = "https://sou.zhaopin.com/?jl=全国&kw=%s&p=%s"
def start_browser(self):
# 指定Chrome驱动程序的路径
browser = webdriver.Chrome(executable_path='./chromedriver129.exe')
return browser
def main(self, **info):
if info['page'] < self.page: return
browser = self.start_browser()
print('正在访问页面URL:' + self.spider_url % (self.job_type, self.page))
browser.get(self.spider_url % (self.job_type, self.page))
time.sleep(5)
job_list = browser.find_elements(by=By.XPATH, value='//*[@id="positionList-hook"]/div/div[1]/div')
for index, job in enumerate(job_list):
try:
print("正在爬取第 %d 条" % (index + 1))
job_data = []
# title 工作名字
title = job.find_element(by=By.XPATH, value='.//div[@class="jobinfo__top"]/a').text
print(title)
# companyTitle 公司名称
company_title = job.find_element(by=By.XPATH, value=".//div[@class='companyinfo__top']/a").text
print(company_title)
# workTag 技能需求
work_tag = job.find_element(by=By.XPATH, value=".//div[@class='jobinfo__tag']/div").text
print(work_tag)
# address 地址
address = job.find_element(by=By.XPATH, value='.//div[@class="jobinfo__other-info-item"]/span').text
print(address)
# city 城市
if '·' in address:
city = address.split('·')[0]
else:
city = address
print(city)
# 工作经验
work_experience = job.find_element(by=By.XPATH, value=".//div[@class='jobinfo__other-info']/div[2]").text
print(work_experience)
# 学历要求
education = job.find_element(by=By.XPATH, value=".//div[@class='jobinfo__other-info']/div[3]").text
print(education)
# 公司性质
company_state = job.find_element(by=By.XPATH, value=".//div[@class='companyinfo__tag']/div[1]").text
print(company_state)
# 公司人数
company_people = job.find_element(by=By.XPATH, value=".//div[@class='companyinfo__tag']/div[2]").text
print(company_people)
# 公司业务
company_business = job.find_element(by=By.XPATH, value=".//div[@class='companyinfo__tag']/div[3]").text
print(company_business)
# type 工作类型
job_type = self.job_type
print(job_type)
# salary 薪资
salary = job.find_element(by=By.XPATH, value='//*[@id="positionList-hook"]/div/div[1]/div[1]/div[1]/div[1]/div[1]/p').text
if '·' in salary:
salary = salary.split('·')[0]
print(salary)
# logo 公司Logo
company_logo = job.find_element(by=By.XPATH, value=".//div[@class='companyinfo__logo']/img").get_attribute('src')
print(company_logo)
# companyUrl 公司链接
company_url = job.find_element(by=By.XPATH, value=".//div[@class='companyinfo__top']/a").get_attribute('href')
print(company_url)
# detailUrl 详情链接
detail_url = job.find_element(by=By.XPATH, value=".//div[@class='jobinfo__top']/a").get_attribute('href')
print(detail_url)
job_data.extend([job_type ,title, company_title, work_tag, address, city,work_experience, education, company_state, company_people,company_business,salary,company_logo,company_url, detail_url])
self.save_to_csv(job_data)
except Exception as e:
print(f"发生错误: {e}")
pass
self.page += 1
self.main(page=info['page'])
def save_to_csv(self, row_data):
with open('./zhaopin_Data.csv', 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(row_data)
def init(self):
if not os.path.exists('./zhaopin_Data.csv'):
with open('./zhaopin_Data.csv', 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(["job_type","title", "companyTitle", "work_tag","address", "city", "work_experience", "education", "company_state","company_people","company_business","salary","company_logo", "companyUrl", "detailUrl"])
def save_to_sql(self):
data = self.clear_data()
for job in data:
JobInfo.objects.create(
job_type=job[0],
title=job[1],
company_title=job[2],
work_tag=job[3],
address=job[4],
city=job[5],
work_experience=job[6],
education=job[7],
company_state=job[8],
company_people=job[9],
company_business=job[10],
salary=job[11],
company_logo=job[12],
company_url=job[13],
detail_url=job[14]
)
print("导入数据库成功,原csv文件已删除!")
os.remove("./zhaopin_Data.csv")
def clear_data(self):
df = pd.read_csv('./zhaopin_Data.csv')
df.dropna(inplace=True)
df.drop_duplicates(inplace=True)
print("总条数为%d" % df.shape[0])
return df.values
if __name__ == '__main__':
spider_obj = ZhilianSpider("后端开发", 1)
spider_obj.init()
spider_obj.main(page=20)
# spider_obj.save_to_sql()2.2 数据库设计
本项目我们是针对爬取的工作岗位的数据做分析,自然需要创建一个岗位表,同时用户可以收藏各位,自然也需要创建一个用户表和收藏表,其中收藏表和岗位表是1对多的关系,岗位表的字段根据爬取的内容而定,对应的3张表的字段结构如下:
from django.db import models
class JobInfo(models.Model):
id = models.AutoField('id',primary_key=True)
job_type = models.CharField(verbose_name = '工作类型',max_length=100,null=True,default='')
title = models.CharField(verbose_name = '工作名字',max_length=100,null=True,default='')
company_title = models.CharField(verbose_name = '公司名称',max_length=100,null=True,default='')
work_tag = models.CharField(verbose_name = '工作标签',max_length=100,null=True,default='')
address = models.CharField(verbose_name= '工作地址',max_length=100,null=True,default='')
city = models.CharField(verbose_name= '工作城市',max_length=100,null=True,default='')
work_experience = models.CharField(verbose_name= '工作经验',max_length=100,null=True,default='')
education = models.CharField(verbose_name= '学历',max_length=100,null=True,default='')
company_state = models.CharField(verbose_name= '公司性质',max_length=100,null=True,default='')
company_people = models.CharField(verbose_name= '公司人数',max_length=100,null=True,default='')
company_business = models.CharField(verbose_name= '公司业务',max_length=100,null=True,default='')
salary = models.CharField(verbose_name= '薪资',max_length=100,null=True,default='')
company_logo = models.CharField(verbose_name= '公司头像',max_length=300,null=True,default='')
company_url = models.CharField(verbose_name = '公司详情',max_length=300,null=True,default='')
detail_url = models.CharField(verbose_name = '工作详情',max_length=300,null=True,default='')
class Meta:
db_table = "jobInfo"
verbose_name = '岗位数据'
class User(models.Model):
id = models.AutoField('id',primary_key=True)
username = models.CharField('用户名',max_length=255,default='')
password = models.CharField('密码',max_length=255,default='')
educational = models.CharField('学历',max_length=255,default='本科')
workExpirence = models.CharField('工作经验',max_length=255,default='应届生')
address = models.CharField('意向城市',max_length=255,default='杭州')
work = models.CharField('意向岗位',max_length=255,default='Python后端开发')
avatar = models.FileField("用户头像",upload_to="avatar",default="avatar/ailun.jpg")
createTime = models.DateField("创建时间",auto_now_add=True)
class Meta:
db_table = "user"
verbose_name = '用户数据'
class History(models.Model):
id = models.AutoField('id',primary_key=True)
job = models.ForeignKey(JobInfo,on_delete=models.CASCADE)
user = models.ForeignKey(User,on_delete=models.CASCADE)
count = models.IntegerField("点击次数",default=1)
def __str__(self):
return self.job_id
class Meta:
db_table = "histroy"
verbose_name = '岗位收藏'
2.3 后端业务逻辑处理
我先将代码粘贴,然后对其代码进行详细分析,也就是对登陆注册,个人中心,岗位收藏以及可视化图表的实现代码的流程做分析:
2.3.1 登录
def login(request):
if request.method == 'GET':
return render(request, 'login.html')
else:
uname = request.POST.get('username')
pwd = request.POST.get('password')
md5 = hashlib.md5()
md5.update(pwd.encode())
pwd = md5.hexdigest()
try:
user = User.objects.get(username=uname,password=pwd)
request.session['username'] = user.username
return redirect('home')
except:
return errorResponse(request, '用户名或密码错误!')
def errorResponse(request,errorMsg):
return render(request,'error.html',{
'errorMsg':errorMsg
})
2.3.2 注册
def registry(request):
if request.method == 'GET':
return render(request, 'register.html')
else:
uname = request.POST.get('username')
pwd = request.POST.get('password')
checkPWD = request.POST.get('checkPassword')
try:
User.objects.get(username=uname)
except:
if not uname or not pwd or not checkPWD:return errorResponse(request, '不允许为空!')
if pwd != checkPWD:return errorResponse(request, '两次密码不符合!')
md5 = hashlib.md5()
md5.update(pwd.encode())
pwd = md5.hexdigest()
User.objects.create(username=uname,password=pwd)
return redirect('login')
return errorResponse(request, '该用户已被注册')
2.3.3 首页大屏
def home(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
def getNowTime():
timeFormat = time.localtime()
year = timeFormat.tm_year
month = timeFormat.tm_mon
day = timeFormat.tm_mday
monthList = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October",
"November", "December"]
return year, monthList[month - 1], day
year,month,day = getNowTime()
def getTagData():
educations = {"博士": 1, "硕士": 2, "本科": 3, "大专": 4, "高中": 5, "中专/中技": 6, "初中及以下": 7,"学历不限": 8}
jobs = JobInfo.objects.all()
users = User.objects.all()
educationsTop = "学历不限"
salaryTop = 0
address = {}
for job in jobs:
if educations[job.education] < educations[educationsTop]:
educationsTop = job.education
# 这段代码的作用是判断一个字典 address 中是否包含 key 为 job.address 的元素。
# 如果不包含,则向字典中添加一个 key 为 job.address,value 为 1 的元素。如果包含,则不进行任何操作。
if address.get(job.city, -1) == -1:
address[job.city] = 1
else:
address[job.city] += 1
addressStr = sorted(address.items(), key=lambda x: x[1], reverse=True)[:3]
addressTop = ""
for i in addressStr:
addressTop += i[0] + ","
return len(jobs), len(users), educationsTop, salaryTop, addressTop
jobsLen,usersLen,educationsTop,salaryTop,addressTop = getTagData()
# 用户创建时间饼状图
def getUserCreateTime():
users = User.objects.all()
data = {}
for u in users:
if data.get(str(u.createTime), -1) == -1:
data[str(u.createTime)] = 1
else:
data[str(u.createTime)] += 1
result = []
for k, v in data.items():
result.append({
'name': k,
'value': v
})
return result
userTime = getUserCreateTime()
def getUserTop5():
users = User.objects.all()
def sort_fn(item):
return time.mktime(time.strptime(str(item.createTime), '%Y-%m-%d'))
users = list(sorted(users, key=sort_fn, reverse=True))[:6]
return users
newUser = getUserTop5()
tableData = JobInfo.objects.all()
return render(request, 'index.html',{
'username':username,
'userAvatar':userInfo.avatar,
'year':year,
"month":month,
'day':day,
'jobsLen':jobsLen,
'usersLen':usersLen,
'educationsTop':educationsTop,
'salaryTop':salaryTop,
'addressTop':addressTop,
'userTime':userTime,
'newUser':newUser,
'tableData':tableData
})2.3.4 个人中心
def selfInfo(request):
def getPageData():
jobs = JobInfo.objects.all()
jobsType = {}
educations = ["博士", "硕士", "本科", "大专", "高中", "中专/中技", "学历不限"]
workExperience = ['在校/应届生', '经验不限', '1-3年', '3-5年', '5-10年', '10年以上']
for i in jobs:
if jobsType.get(i.job_type, -1) == -1:
jobsType[i.job_type] = 1
else:
jobsType[i.job_type] += 1
return educations, workExperience, jobsType.keys()
def changeSelfInfo(newInfo, FileInfo):
user = User.objects.get(username=newInfo['username'])
user.educational = newInfo['educational']
user.workExpirence = newInfo['workExpirence']
user.address = newInfo['address']
user.work = newInfo['work']
if FileInfo['avatar'] != None:
user.avatar = FileInfo['avatar']
user.save()
username = request.session.get("username")
userInfo = User.objects.get(username=username)
educations,workExperience,jobsTypes = getPageData()
if request.method == 'GET':
return render(request,'selfInfo.html',{
'username': username,
'userInfo': userInfo,
'educations':educations,
'workExperience':workExperience,
'jobsTypes':jobsTypes
})
else:
changeSelfInfo(request.POST,request.FILES)
userInfo = User.objects.get(username=username)
return render(request, 'selfInfo.html', {
'username': username,
'userInfo': userInfo,
'educations': educations,
'workExperience': workExperience,
'jobsTypes': jobsTypes
})2.3.4 修改密码
def changePassword(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
if request.method == 'GET':
return render(request,'changePassword.html',{
'username': username,
'userInfo': userInfo,
})
else:
res = changePassword(request.POST,userInfo)
if res != None:
return render(request,'error.html',{
'errorMsg':res
})
userInfo = User.objects.get(username=username)
return render(request, 'changePassword.html', {
'username': username,
'userInfo': userInfo,
})2.3.5 数据总览
def tableData(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
tableData = JobInfo.objects.all()
paginator = Paginator(tableData, 6)
# 根据请求地址的信息来跳转页码数据
cur_page = 1
if request.GET.get("page"):
cur_page = int(request.GET.get("page"))
if cur_page:
c_page = paginator.page(cur_page)
else:
c_page = paginator.page(1)
page_range = []
visibleNumber = 15
min = int(cur_page - visibleNumber / 2)
if min < 1:
min = 1
max = min + visibleNumber
if max > paginator.page_range[-1]:
max = paginator.page_range[-1]
for i in range(min,max):
page_range.append(i)
return render(request, 'tableData.html',{
'username': username,
'userInfo': userInfo,
'tableData':tableData,
"pagination":paginator,
"c_page":c_page,
'page_range':page_range
})
def historyTableData(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
historyData = getHistoryTableData.getHistoryData(userInfo)
return render(request, 'historyTableData.html', {
'userInfo': userInfo,
'historyData': historyData
})2.3.6 数据收藏
# 添加收藏岗位
def addHistory(request, jobId):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
getHistoryTableData.addHistory(userInfo, jobId)
2.3.7 (5个页面可视化)
# 城市容纳可视化页面
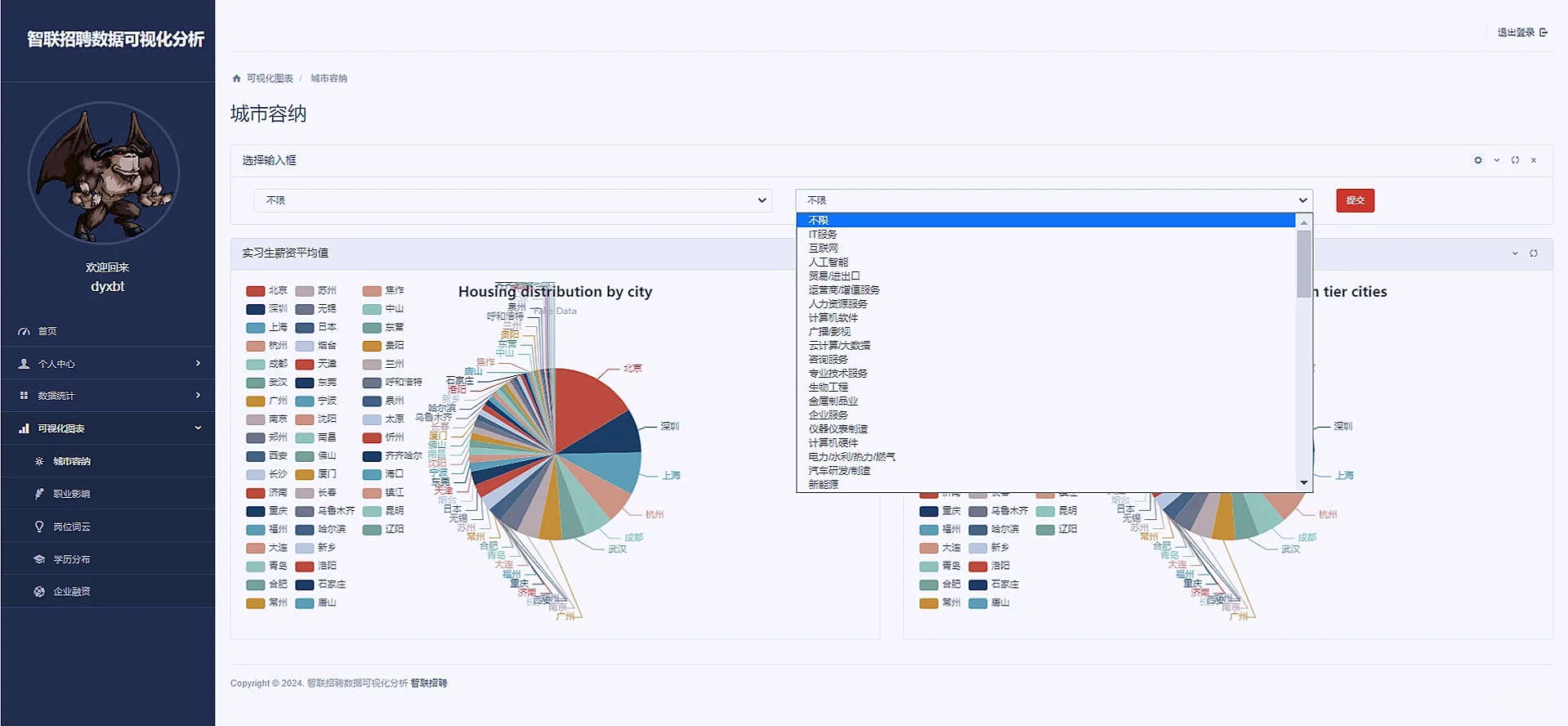
def cityContain(request):
defaultType1 = '不限' ; defaultType2 = '不限'
username = request.session.get("username")
userInfo = User.objects.get(username=username)
statename = request.GET.get('statename')
business_name = request.GET.get('businessname')
state_list = list(JobInfo.objects.values_list('company_state', flat=True).distinct())
business_list = list(JobInfo.objects.values_list('company_business', flat=True).distinct())
# 查询不同城市的各个不同性质和业务的公司数量
if statename == None or statename == '不限':
company_counts_state = JobInfo.objects.all().values('city').annotate(count=Count('city'))
# 查询数据库,统计每个城市有多少家该性质的公司
else:
defaultType1 = statename
company_counts_state = JobInfo.objects.filter(company_state=statename).values('city').annotate(count=Count('city'))
if business_name == None or business_name == '不限':
company_counts_business = JobInfo.objects.all().values('city').annotate(count=Count('city'))
# 查询数据库,统计每个城市有多少家该性质的公司
else:
defaultType2 = business_name
company_counts_business = JobInfo.objects.filter(company_business=business_name).values('city').annotate(count=Count('city'))
# 将结果转换为字典形式
result_state = {item['city']: item['count'] for item in company_counts_state}
result_business = {item['city']: item['count'] for item in company_counts_business}
result = dict(sorted(result_state.items(), key=lambda item: item[1], reverse=True)[:50])
result_business = dict(sorted(result_business.items(), key=lambda item: item[1], reverse=True)[:50])
list_state = [];list_business = []
for k,v in result.items():
list_state.append({ 'value': v, 'name': k })
for k,v in result_business.items():
list_business.append({ 'value': v, 'name': k })
context = {'result': result, 'username': username, 'userInfo': userInfo, 'state_list': state_list,'list_state': list_state, 'defaultType1': defaultType1, 'defaultType2': defaultType2,'list_business': list_business, 'business_list': business_list}
return render(request, 'cityContain.html',context)
# 工作类型影响可视化页面
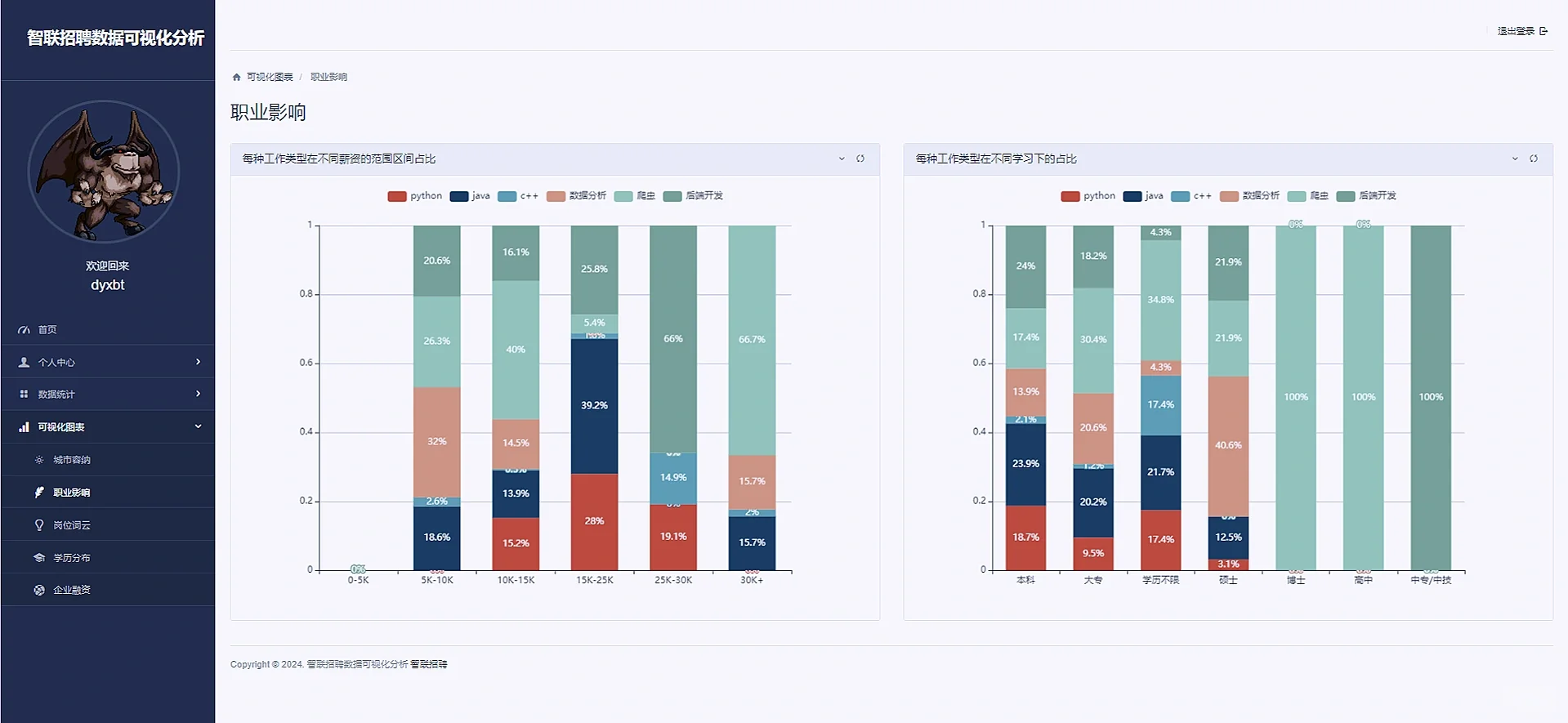
def jobTypeAffecte(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
def convert_salary_to_average(salary_range):
"""
将薪资范围字符串转换为平均值(以k为单位)
如果薪资范围格式不正确,则返回None
"""
try:
# 尝试拆分薪资范围字符串
min_salary_str, max_salary_str = salary_range.split('-')
except ValueError:
# 如果拆分失败,可能是因为薪资范围格式不正确
print(f"薪资范围格式不正确: {salary_range}")
return None
# 定义一个函数来将薪资字符串转换为以元为单位的整数
def to_yuan(salary_str):
if '万' in salary_str:
return int(float(salary_str.replace('万', '')) * 10000)
elif '千' in salary_str:
return int(float(salary_str.replace('千', '')) * 1000)
else:
# 如果不包含'万'或'千',则无法确定薪资单位,返回None
print(f"无法确定薪资单位: {salary_str}")
return None
# 将薪资字符串转换为以元为单位的整数
min_salary_yuan = to_yuan(min_salary_str.strip()) # 使用strip()去除可能的空白字符
max_salary_yuan = to_yuan(max_salary_str.strip())
# 如果转换后的薪资为None,则返回None
if min_salary_yuan is None or max_salary_yuan is None:
return None
# 计算平均值并转换为以k为单位的浮点数
average_salary_yuan = (min_salary_yuan + max_salary_yuan) / 2
average_salary_k = average_salary_yuan / 1000
# 返回保留一位小数的平均值
return round(average_salary_k, 1)
def get_salary_range_category(average_salary):
if average_salary is None:
return None
if average_salary < 5:
return '0-5K'
elif 5 <= average_salary < 10:
return '5K-10K'
elif 10 <= average_salary < 15:
return '10K-15K'
elif 15 <= average_salary < 25:
return '15K-25K'
elif 25 <= average_salary < 30:
return '25K-30K'
else:
return '30K+'
def get_job_data():
job_infos = JobInfo.objects.values('job_type', 'salary').annotate(count=Count('id'))
job_types = list(JobInfo.objects.values_list('job_type', flat=True).distinct())
salary_counts = {}
for job_info in job_infos:
job_type = job_info['job_type']
salary_range = job_info['salary']
count = job_info['count']
average_salary = convert_salary_to_average(salary_range)
if average_salary is not None:
category = get_salary_range_category(average_salary)
if job_type not in salary_counts:
salary_counts[job_type] = {}
if category not in salary_counts[job_type]:
salary_counts[job_type][category] = 0
salary_counts[job_type][category] += count
# 准备薪资区间列表(用于生成表格表头或选项)
salary_ranges = ['0-5K', '5K-10K', '10K-15K', '15K-25K', '25K-30K', '30K+']
# 准备每种job_type对应的薪资区间数量数据(二维列表)
rawData = []
for job_type in job_types:
row = [0] * len(salary_ranges)
if job_type in salary_counts:
for idx, category in enumerate(salary_ranges):
if category in salary_counts[job_type]:
row[idx] = salary_counts[job_type][category]
rawData.append(row)
return job_types, salary_ranges, rawData
job_types, salary_ranges, rawData = get_job_data()
# 不同的工作的不同学历的占比
# 从数据库中获取所有 JobInfo 对象,按 job_type 和 salary 分组,并计算数量
job_infos = JobInfo.objects.values('job_type', 'education').annotate(count=Count('id'))
# 获取所有不同的 salary(假设 salary 是数值类型,如果是字符串类型则需要相应处理)
educations = list(JobInfo.objects.values_list('education', flat=True).distinct())
# 创建一个字典来存储每种 job_type 下各个 salary 的数量
job_type_education_count = {}
for job_info in job_infos:
job_type = job_info['job_type']
education = job_info['education']
count = job_info['count']
if job_type not in job_type_education_count:
job_type_education_count[job_type] = {}
job_type_education_count[job_type][education] = count
# 生成第三个数据:一个大列表,里面放了几个小列表,每个小列表是每种 job_type 所对应的各个 salary 的数量
rawData1 = []
for job_type in job_types:
row = [0] * len(educations) # 创建一个与 salaries 长度相同的列表,并用 0 填充
for idx, education in enumerate(educations):
if education in job_type_education_count.get(job_type, {}):
row[idx] = job_type_education_count[job_type][education]
rawData1.append(row)
print(job_types, educations, rawData1)
print(job_types, salary_ranges, rawData)
context = {'userInfo': userInfo, 'username': username, 'job_types': job_types, 'salary_ranges': salary_ranges, 'rawData': rawData,'educations': educations, 'rawData1': rawData1}
return render(request,'jobTypeAffect.html',context)
# 工作字段相关词云图
def jobCloud(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
def wordCloud():
business_counts = JobInfo.objects.values('company_business').annotate(count=Count('company_business'))
wordcloud_data = {}
for business_count in business_counts:
wordcloud_data[business_count['company_business']] = business_count['count']
# 设置 margin 参数为较小的值
wordcloud = WordCloud(font_path='msyh.ttc', width=550, height=550, background_color='white',
margin=2).generate_from_frequencies(wordcloud_data)
plt.figure(figsize=(7, 7))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.savefig('static/wordcloud/business.jpg')
title_counts = JobInfo.objects.values('title').annotate(count=Count('title'))
wordcloud_data = {}
for title_count in title_counts:
wordcloud_data[title_count['title']] = title_count['count']
# 设置 margin 参数为较小的值
wordcloud = WordCloud(font_path='msyh.ttc', width=550, height=550, background_color='white',
margin=2).generate_from_frequencies(wordcloud_data)
plt.figure(figsize=(7, 7))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.savefig('static/wordcloud/title.jpg')
plt.show()
# wordCloud()
context = {'userInfo': userInfo, 'username':username}
return render(request,'jobCloud.html',context)
# 学历影响可视化页面
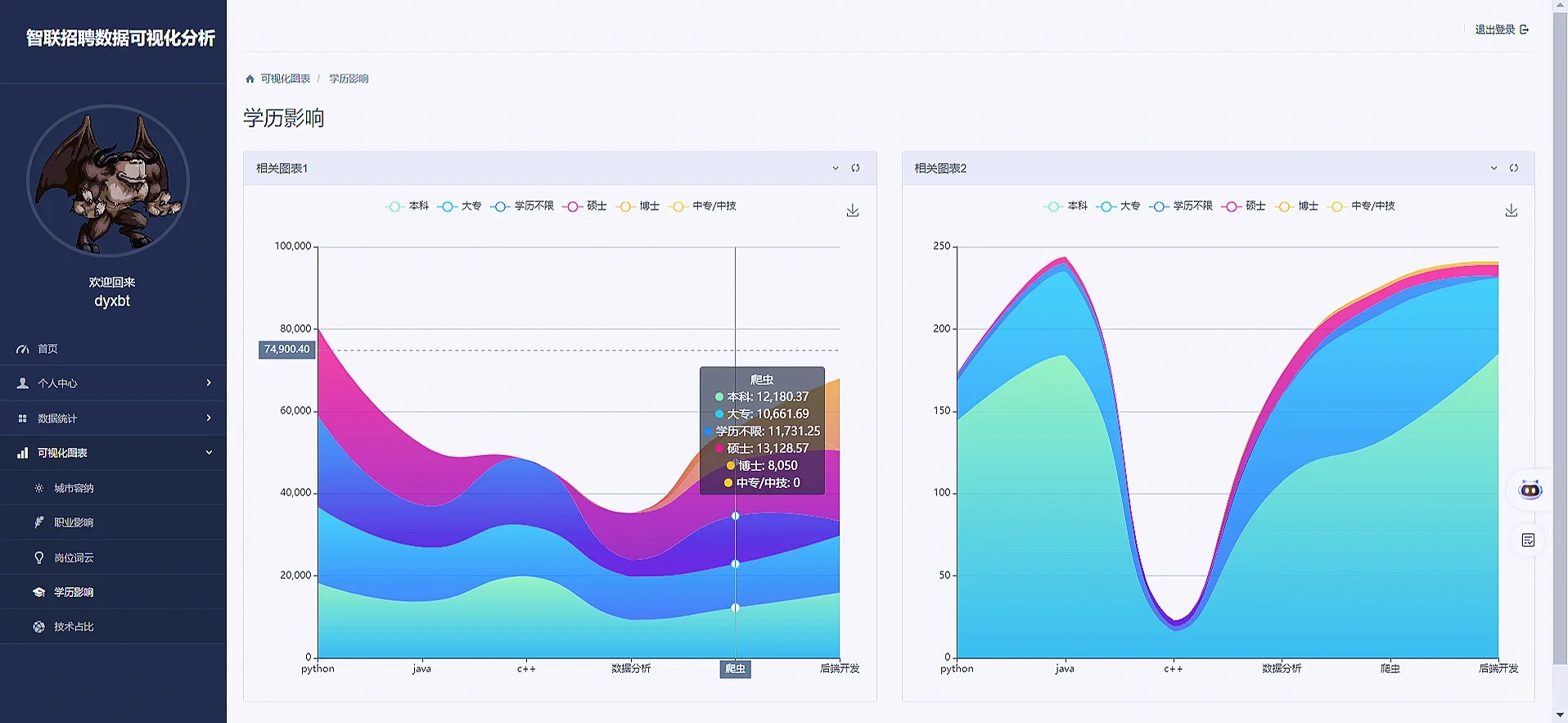
def educationAffect(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
# 获取唯一的学历列表
education_list = JobInfo.objects.values_list('education', flat=True).distinct()
# 获取唯一的工作类型列表
job_type_list = JobInfo.objects.values_list('job_type', flat=True).distinct()
# 初始化学历下的平均工资列表
average_salaries = []
# 新增变量,用于保存每个学历下不同 job_type 的数量
job_type_counts = []
for education in education_list:
# 初始化当前学历下的平均工资列表
salary_list = []
count_list = [] # 新增列表用于保存当前学历下每个 job_type 的数量
for job_type in job_type_list:
# 过滤出当前学历和工作类型的职位
jobs = JobInfo.objects.filter(education=education, job_type=job_type)
total_salary = 0
count = 0
for job in jobs:
# 处理薪资数据
salary_range = job.salary
if '千' in salary_range or '万' in salary_range:
# 提取薪资范围
if '千' in salary_range:
salary_range = salary_range.replace('千', '').replace('万', '')
lower, upper = map(float, salary_range.split('-')) # 使用 float 处理小数
total_salary += (lower * 1000 + upper * 1000) / 2
elif '万' in salary_range:
salary_range = salary_range.replace('万', '')
lower, upper = map(float, salary_range.split('-')) # 使用 float 处理小数
total_salary += (lower * 10000 + upper * 10000) / 2
count += 1
# 计算当前学历和工作类型的平均工资
if count > 0:
average_salary = total_salary / count
salary_list.append(round(average_salary, 2))
else:
salary_list.append(0) # 如果没有对应的岗位工资数据,添加0
# 记录当前学历下该 job_type 的数量
count_list.append(jobs.count()) # 记录当前学历和工作类型的职位数量
# 将当前学历的平均工资列表添加到总列表中
average_salaries.append(salary_list)
job_type_counts.append(count_list) # 将当前学历下的数量列表添加到 job_type_counts
context = {'userInfo': userInfo,
'username': username,
'education_list': list(education_list),
'job_type_list': list(job_type_list),
'average_salaries': average_salaries,
'job_type_counts': job_type_counts, # 将新变量添加到上下文中
}
return render(request, 'educationAffect.html', context)
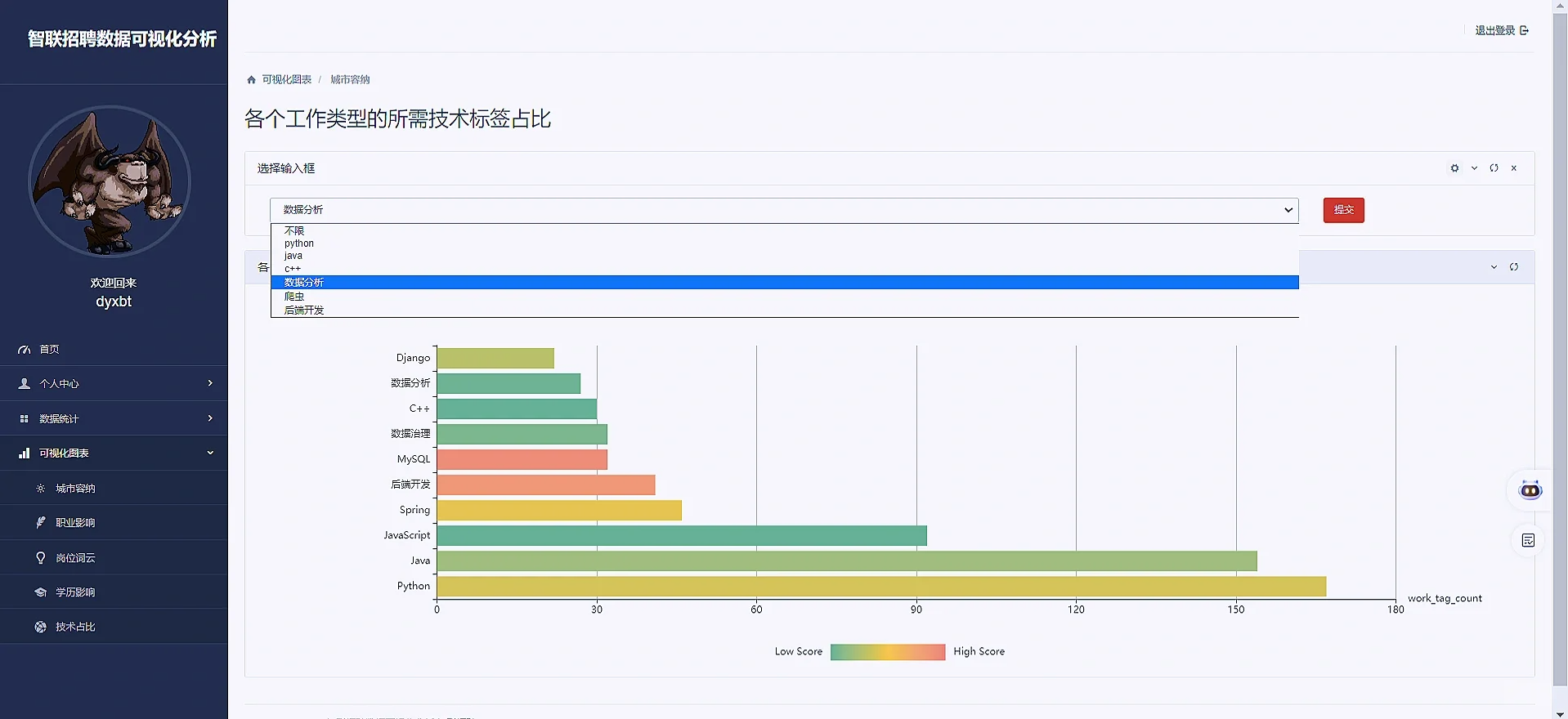
# 技术占比可视化页面
def itDistribute(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
defaultType = '不限'
job_type_list = JobInfo.objects.values_list('job_type', flat=True).distinct()
job_type_selected = request.GET.get('job_type_name')
# 获取所有工作标签及其计数
work_tag_counts = {}
if job_type_selected and job_type_selected != '不限':
defaultType = job_type_selected
for job in JobInfo.objects.all().filter(job_type=job_type_selected):
if job.work_tag in work_tag_counts:
work_tag_counts[job.work_tag] += 1
else:
work_tag_counts[job.work_tag] = 1
else:
for job in JobInfo.objects.all():
if job.work_tag in work_tag_counts:
work_tag_counts[job.work_tag] += 1
else:
work_tag_counts[job.work_tag] = 1
# 对标签按数量排序并获取前30个
sorted_tags = dict(sorted(work_tag_counts.items(),
key=lambda item: item[1],
reverse=True)[:10])
import random
# 创建数据结构
scatter_data = [['score', 'work_tag_count', 'work_tag_name']]
for tag_name, count in sorted_tags.items():
# 生成1-100的随机数
random_score = random.randint(1, 100)
scatter_data.append([random_score, count, tag_name])
context = {
'userInfo': userInfo,
'defaultType': defaultType,
'job_type_list': list(job_type_list),
'username': username,
'scatter_data': scatter_data
}
return render(request, 'itDistrubute.html', context)3 项目效果图如下:
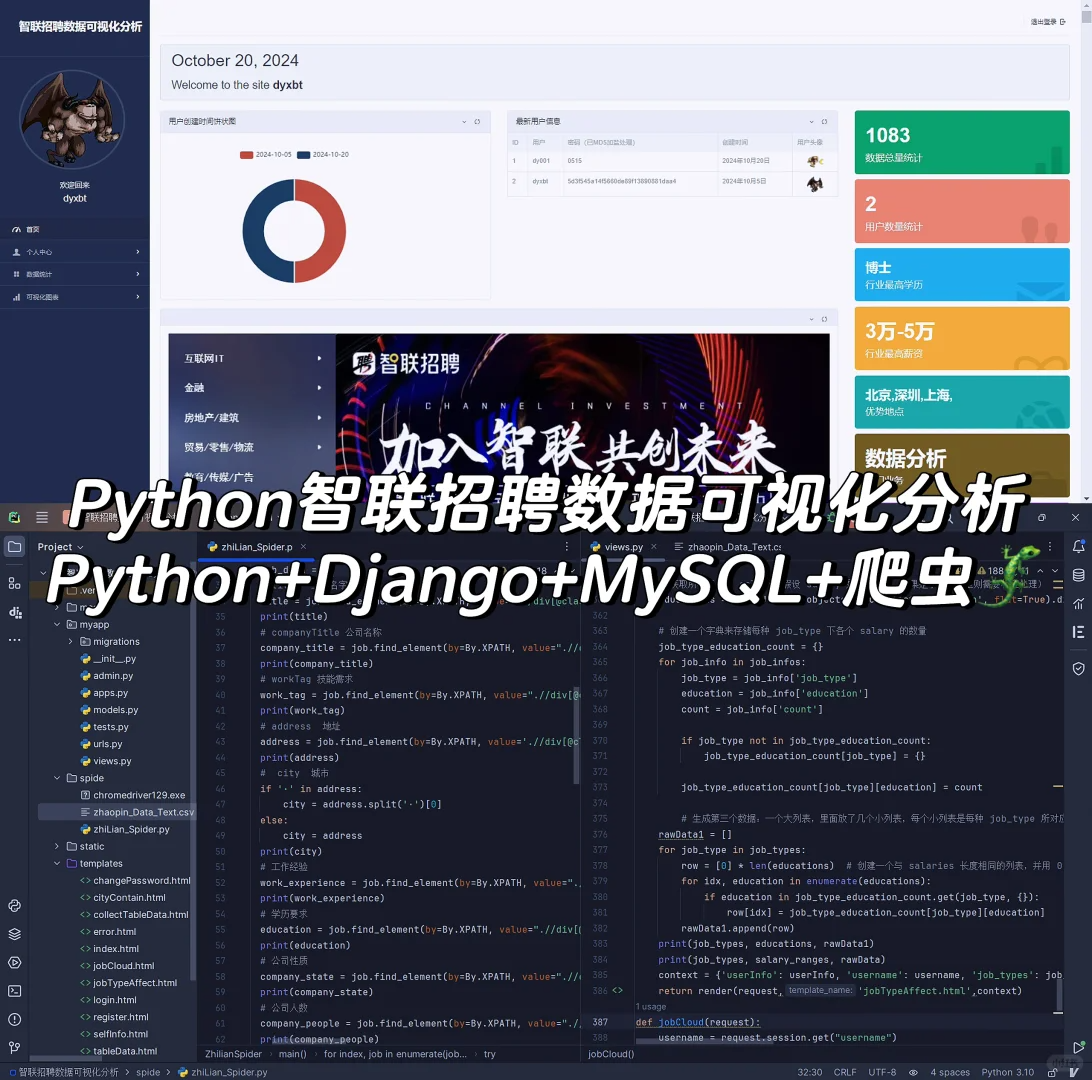
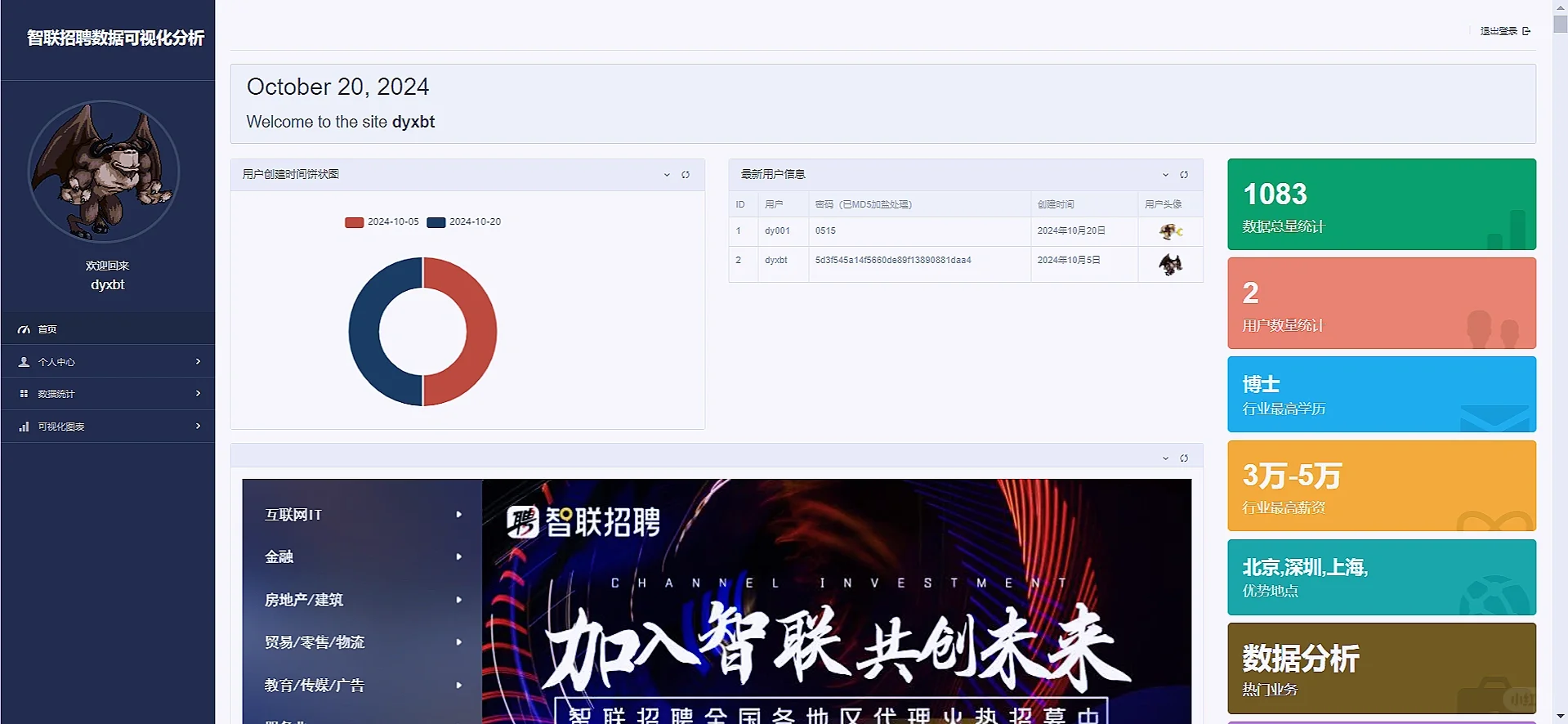
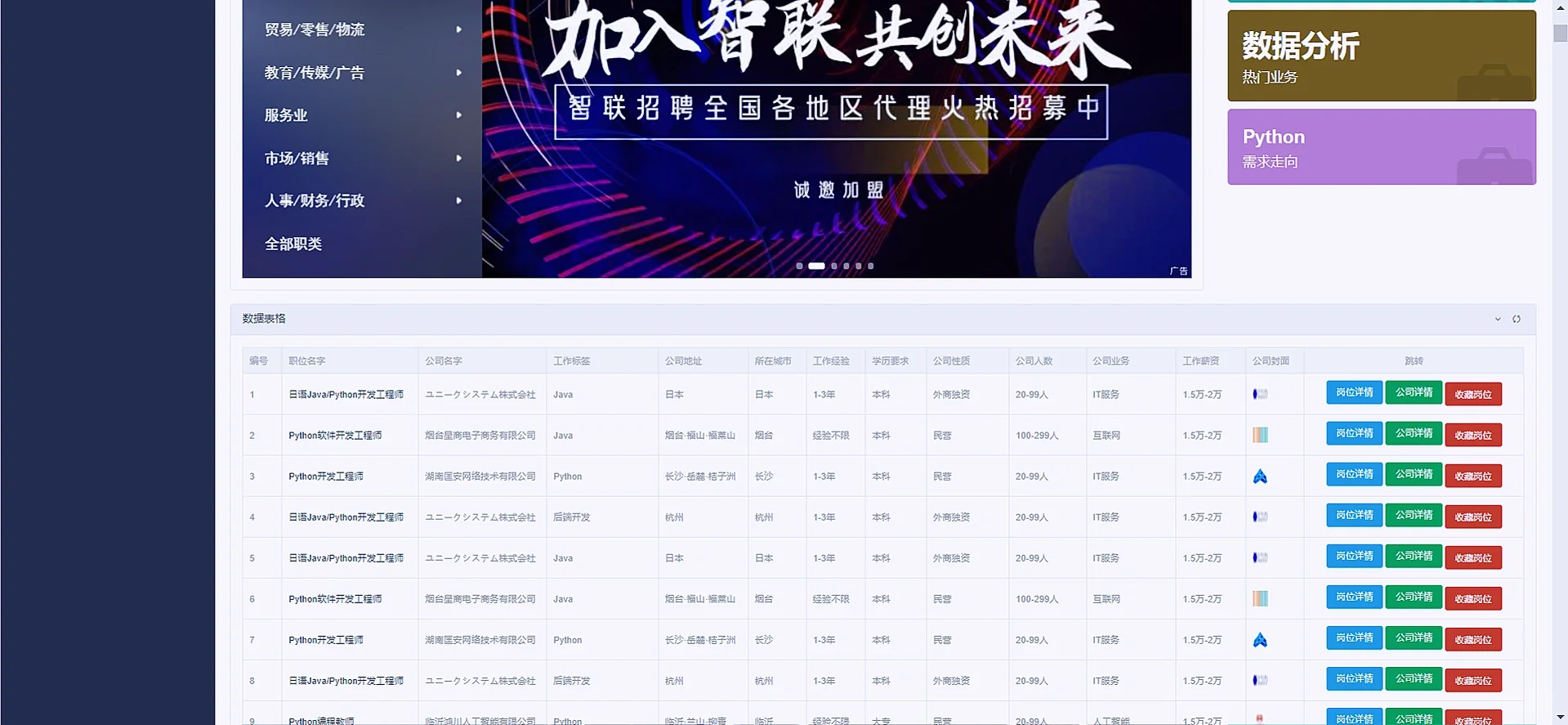
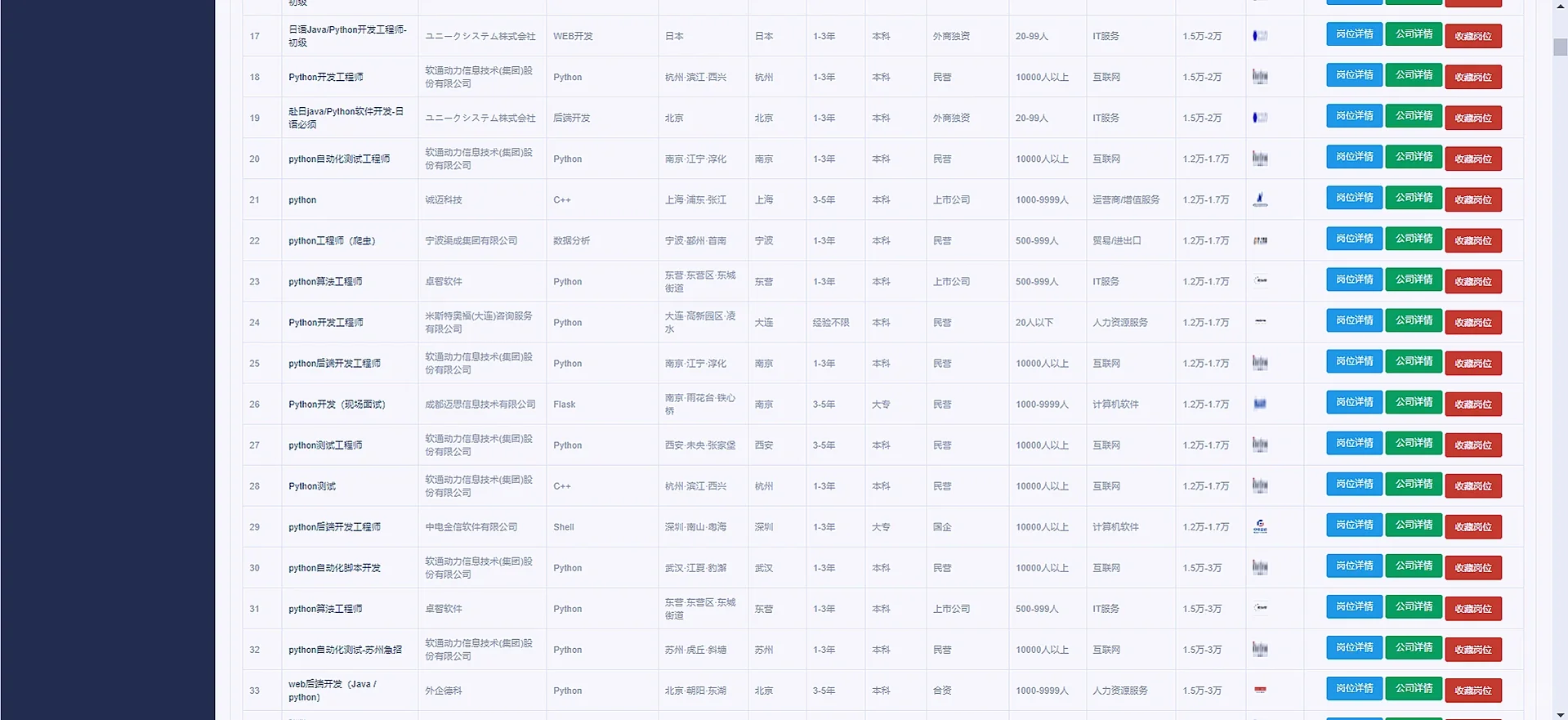
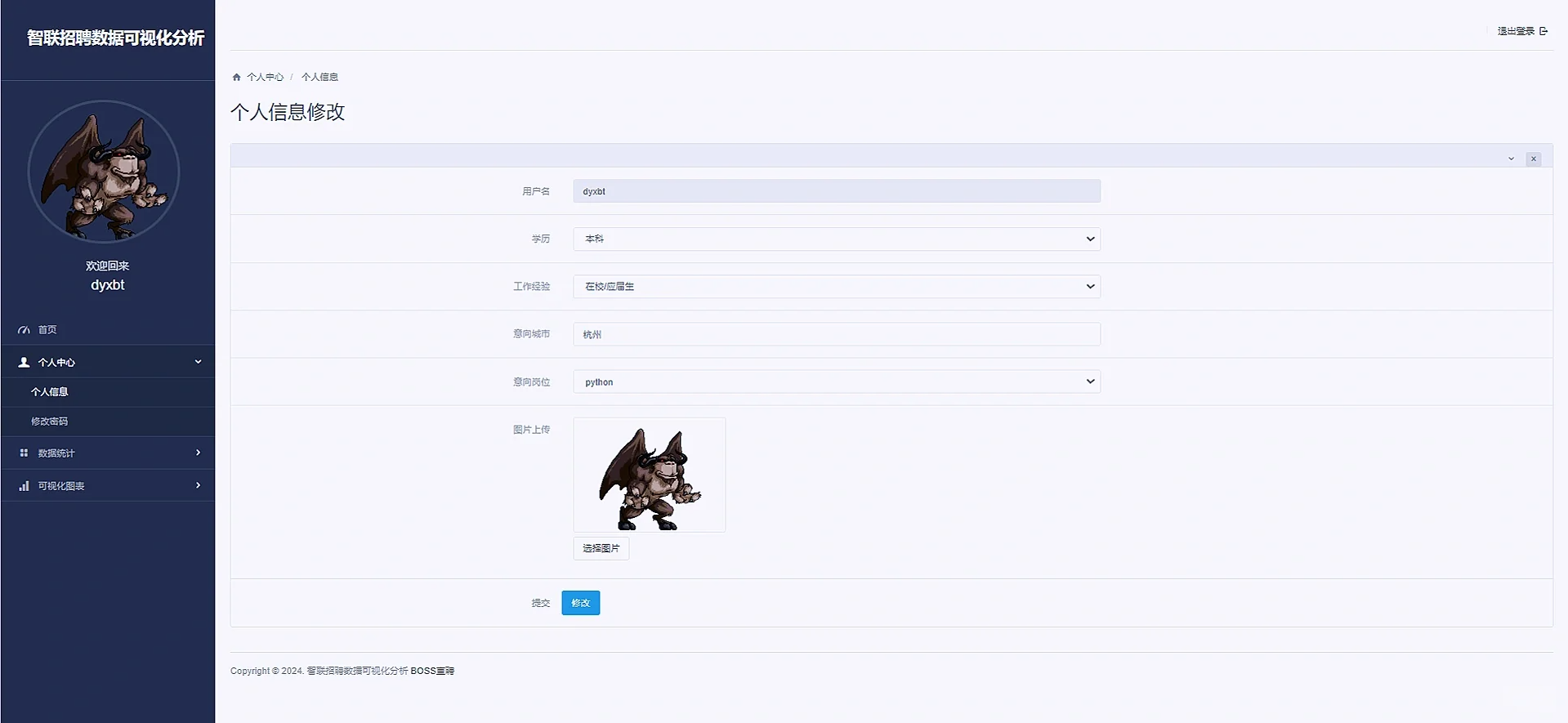
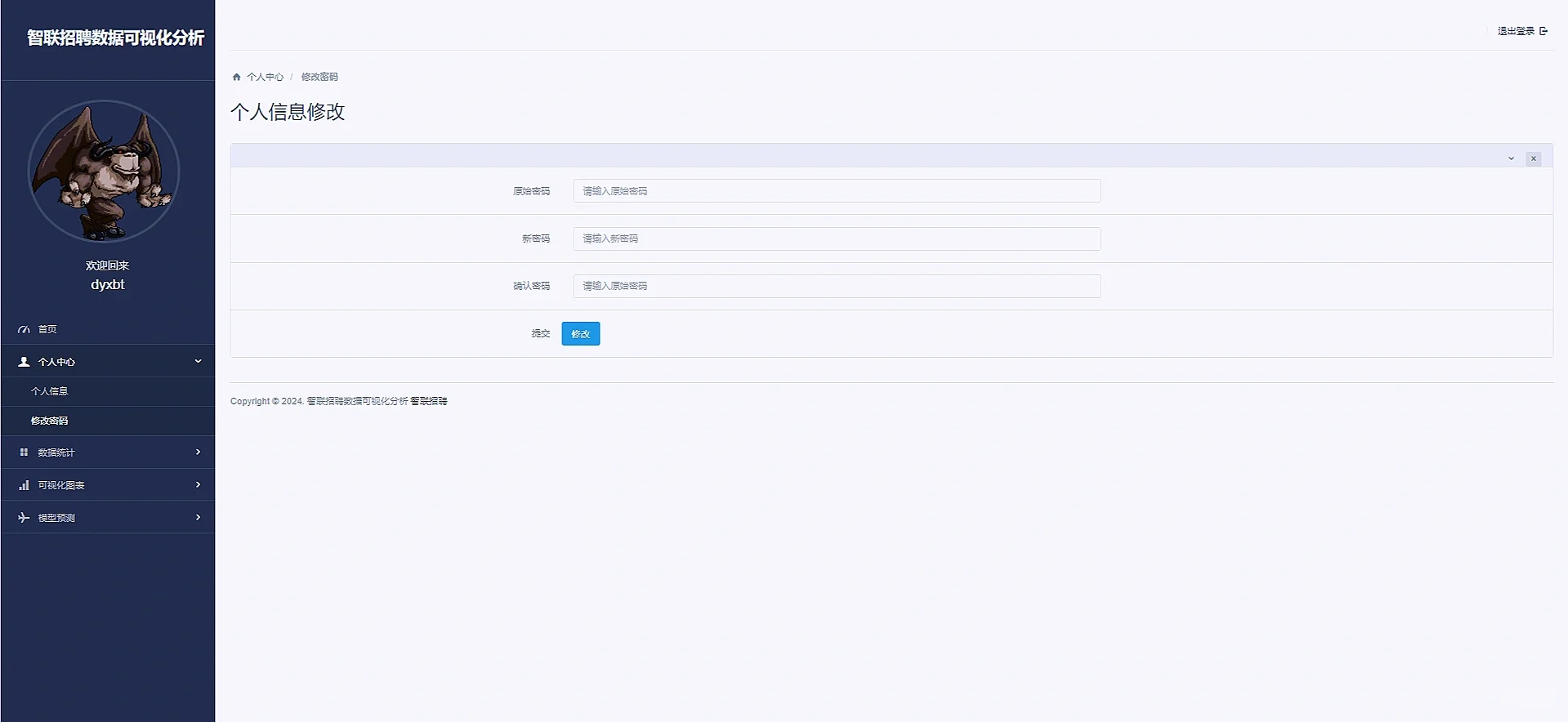

代码较多,流程比较简单,具体可以参考我前面写过的boss直聘数据可视化分析的项目,流程基本上一模一样,都是爬虫存储数据库然后使用django的orm对数据库的字段数据做分析,然后结合echarts进行可视化的呈现,爬虫的原理基本上和我boss的文章的爬虫原理一模一样,我就不再详细叙述啦,登陆注册以及筛选交互的内容都是在前端form表单提前,后端获取再处理,需要项目的同学可以私信我,也可以参考我boss的文章,由于原理一样,所以本篇文章没有很详细叙述啦:Python数据可视化分析项目(boss直聘数据可视化分析)_python可视化项目-优快云博客



















 2949
2949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











