




 本文介绍了Hadoop的序列化机制,包括Writeable接口、Java基本数据类型的封装、Text、BytesWritable、NullWritable以及ObjectWritable和GenericWritable。还讨论了在Hadoop中如何选择定长和变长格式,并对比了String和Text的区别。
本文介绍了Hadoop的序列化机制,包括Writeable接口、Java基本数据类型的封装、Text、BytesWritable、NullWritable以及ObjectWritable和GenericWritable。还讨论了在Hadoop中如何选择定长和变长格式,并对比了String和Text的区别。
序列化是指将结构化对象转化为字节流以便在网络上传输或者写到磁盘上进行永久存储的过程,反序列化是指将字节流转回结构化对象的逆过程
序列化用于分布式处理的两大领域,进程间通信和永久存储。
在Hadoop中,系统中多个节点上进程间的通信是通过“远程过程调用”(remote procedure call, RPC)实现的。RPC将消息序列化成二进制流后发送到远程节点,远程节点接着将二进制流饭序列化为原始消息。通常情况下,RPC序列化格式许紧凑、快速、可扩展、和支持互操作。
能实现序列化的技术有很多,比如JDK自带的的序列化机制,只要需要序列化的类实现serializable接口,缺点是只支持JAVA语言;Hadoop使用的序列化机制,使用Writeable接口来进行序列化;除此之外,还有其他序列化框架也能够和Hadoop配合使用,如Hadoop Avro、Apache Thrift和Google Protocol Buffer。
Hadoop序列化框架Writeable接口
序列化抓住两个关键:序列化和反序列化,所有的都是围绕这这两个展开的。无非就是把结构化数据转化为字节流或是把字节流转化为结构化对象。
Writeable接口定义了两个方法,一个将状态写入DataOutput二进制流,另一个从DataInput二进制流读取状态
@InterfaceAudience.Public
@InterfaceStability.Stable
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}
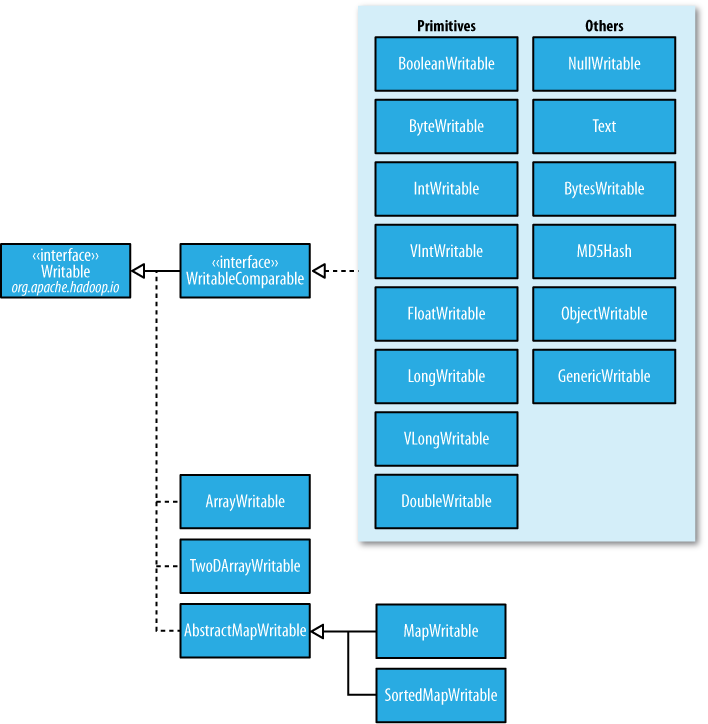
Writeable类家族介绍
使用Writeable进行序列化的话,那么我们平时使用的JAVA基本数据类型以及String这些都不能直接使用,需要使用对应Writeable下面的相应的类。
Java基本数据类型
Writable类对Java基本类型提供封装,short 和 char除外(可以存储在IntWritable中)。所有的封装包包含get() 和 set() 方法用于读取或者设置封装的值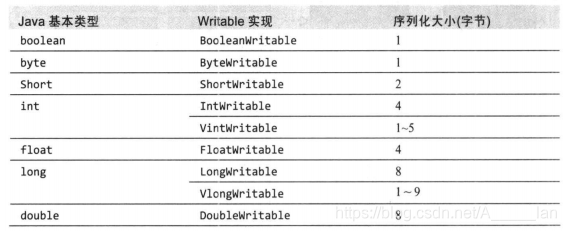
对整数进行编码时,有两种选择,即定长格式(IntWritable和LongWritable)和变长格式(VintWritable和VlongWritable),变长格式只用一个字节进行编码,否则使用一个字节表示数值的正负和后跟多少字节。
如何在定长定长格式和变长格式之间选择?
定长格式很适合数值在整个值域空间分布非常均匀的情况,例如精心设计的哈希函数,然而大多数数值分布是不均匀的,一般来说变长格式会更节省空间,变长格式的另一个优点是可以在VintWritable和VlongWritable之间转换,因为他们的编码实际上是一致的
Text类型
Text是针对UTF-8序列的Writable类,一般可以认为它和java.lang.String等价,Text的最大值是2GB
那么String和Text有什么区别呢?
首先在JAVA中,String是用final修饰,不可变的,但是Text是可变的,除此之外,对Text进行迭代要比对String进行迭代负责的多,在JAVA中,String类提供了很多API对String进行排序,但是如果要对Text进行排序,需要先把Text转化成String对象
BytesWritable
BytesWritable是对二进制字节数组的封装,其值是可以变的,可以通过set()方法进行修改,和Text类似,通过getBytes()方法无法体现BytesWritable所存储实际数据的大小,可以通过getLength()方法来确定BytesWritable的大小
NullWritable
NullWritable是Writable的特殊类型,它的序列化长度为0,他从不从数据流中读取数据也不写入数据,它充当占位符。
ObjectWritable和GenericWritable
ObjectWritable是对JAVA基本数据类型(String,enum,writable,null火他们的数组)的一个通用封装,在Hadoop的RPC机制中用于对于方法的参数和返回类型进行封装和解封装,当一个字段包含多个类型时,ObjectWritable将非常有用。
Objectwritable 作为一个通用机制,这是相当浪费空间的,因为每次它被序列化肘,都要写入被封装类型的类名。GenericWritable 对此做出了改进,如果类型的数量不多并且事先可知,那么可以使用一个静态类型数组来提高效率,使用数组的索引来作为类型的序列化引用.这是GenericWritable 使用的方法,我们必须继承它以指定支持的类型。
Writable集合类
org.apache.hadoop.io共有6个Writable集合类
rrayWritable和TwoDArrayWritable
它们是对Writable的数组和二维数组的实现。常用函数包括toArray()、get()、set()
ArrayPrimitiveWritable
对Java基本数组类型的一个封装。
MapWritable,SortedMapWritable,EnumMapWritable
MapWritable:对集合和列表,枚举集合中的元素
SortedMapWritable:针对排序集合,枚举集合中的元素
EnumMapWritable:对集合的枚举类型采用EnumMapWritable

















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









