






目录
一、AWK简介
AWK工作原理
sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个"字段"然后再进行处理,且默认情况下字段的分隔符为空格或tab键。awk 执行结果可以通过print的功能将字段数据打印显示。
在使用awk命令的过程中,可以使用逻辑操作符"&&“表示"与”、"“表示"或”、"!“表示"非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方
awk后面接两个单引号并加上大括号{ }来设置想要对数据进行的处理操作,awk可以处理后续接的文件,也可以读取来自前个命令的标准输
awk的适用场景
- 超大文件处理;
- 输出格式化的文本报表;
- 执行算数运算;
- 执行字符串操作等。
AWK命令的基本格式
awk [选项] ‘模式条件{操作}’ 文件1 文件2...
awk -f 脚本文件 文件1 文件.....
常见的内建变量(可直接用)
| FS | 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同 |
| NF | 当前处理的行的字段个数。 |
| NR | 当前处理的行的行号(序数)。 |
| $0 | 当前处理的行的整行内容 |
| $n | 当前处理行的第n个字段(第n列) |
| FILNAME | 被处理的文件名 |
| RS | 行分隔符。awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录,以进行处理。预设值是’\n’ |
awk常识
- $0在she11主代码中代表的是脚本名
- 在函数体中代码的是函数名
- 在awk的命令的代表的是当前整行内容
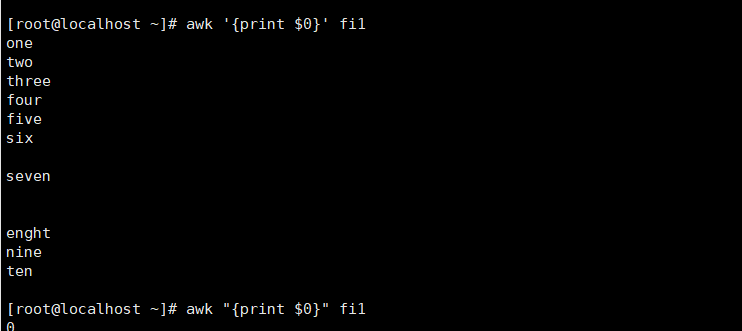
- '{print $0}'
print是打印命令,$0代表当前行
二、操作例子
my(){
awk '{print $1}' $1 #第一个$1属于awk的变量,,第二个$1传的是下面$1传过来的值
}
my $1 这里是位置变量
awk的将文件分成字段
print $0把标准输入
this is a test,重新打印了一遍AWK会根据空格和制表符,将每一行分成若干字段,依次用
$1、$2、$3代表第一个字段、第二个字段、第三个字段等等。$1代表第一个字段 this

双引号会对$0有影响
打印行
打印1-3行


打印1和3行

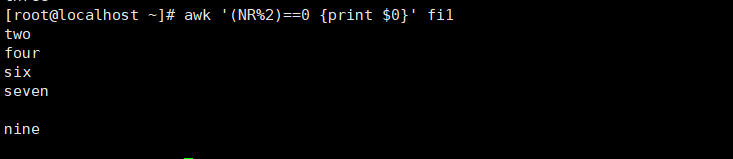
输出偶数行
打印某行某列
与正则的使用
打印bash结尾

-F指定分割符
指定某个分割符,进行后续操作
例如:即去掉后缀 .tar.Z
源字符串:AIX.PI6002.090316.tar.Z
结果字符串:AIX PI6002 090316
以“.”为分隔符,把最后1个字段 和倒数第2个字段 赋值为空, 再输出整个字段
echo AIX.PI6002.090316.tar.Z | awk -F "." '{$NF="";$(NF-1)=""}{print $0}'
#以“.”为分隔符,把最后1个字段 和倒数第2个字段 赋值为空, 再输出整个字段
echo AIX.PI6002.090316.tar.Z | awk -F "." '{$NF="";$(NF-1)=""}{print $0}'
#以“.”为分隔符,输出前三个字段
echo "xxx.xxxx.xxxx.tar.bz" | awk -F. '{print $1"."$2"."$3}'
#以“.”为分隔符,把NF的值减去2,即5-2=3
echo AIX.PI6002.090316.tar.Z | awk -F . 'NF-=2'
#以“.”为分隔符,把NF赋值为NF-2
echo AIX.PI6002.090316.tar.Z | awk 'NF=NF-2' FS=.
#以“.”为分隔符,把NF的值减去2,输出的分隔符为" "
echo AIX.PI6002.090316.tar.Z | awk 'NF-=2' FS=. OFS=" "
#下面输出结果为:AIX.PI6002.090316
#以“.”为分隔符,把NF的值减去2,同时把分隔符通过sed替换 空格 " " 为 "."
echo "AIX.PI6002.090316.tar.bz" | awk -F . 'NF-=2' | sed 's/ /./g'
#以“.”为分隔符,通过for循环输出NF-2之前的字段,利用 printf 的结果输出没有换行符,通过print输出第NF-2个字段,print输出结果有换行符,如此拼出结果。
echo AIX.PI6002.090316.tar.Z | awk -F "." '{for (i=1;i<NF-2;i++) printf $i".";print $(NF-2)}'
#一整个字段为字符串,然后从第一个字符开始,到第三个字段的最后个字符。(match会返回一个数值)
echo AIX.PI6002.090316.tar.Z | awk '{print substr($0,1,match($0,/\.[^\.]+\.[^\.]+$/)-1)}'寻找大于小于
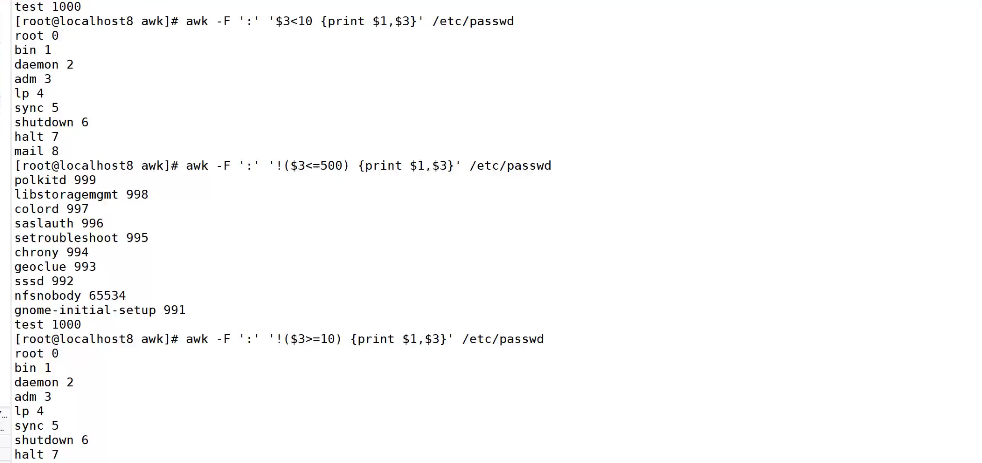
三元运算符
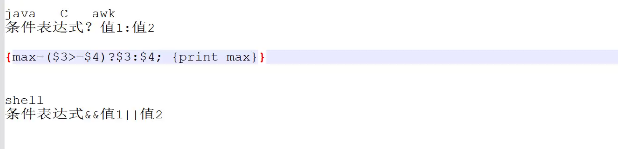
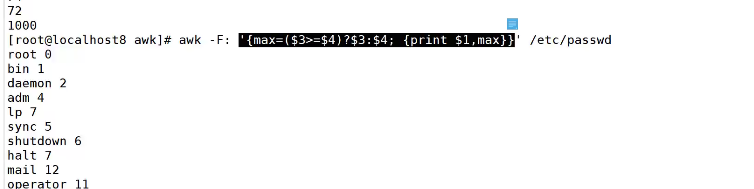
NR
指定行,输出1~3行内容
awk 'NR==1,NR==3 {print}' numfile
awk '(NR>=1)&&(NR<=3) {print}' numfile
指定的几行,输出第1、3行
awk 'NR==1||NR==3 {print}' numfile
输出奇偶行
awk '(NR%2)==0 {print}' numfile
awk '(NR%2)==1 {print}' numfile
指定第1行包含o的行。输出行号和内容
awk '$1~"o" {print NR,$0}' file1
指定输出包含指定字符串的行
awk '/root/ {print}' /etc/passwd
输出行号和行内容
~的运用
$n~""


top -b -n1 | awk '%Cpu/{print $8}'
-o仅匹配
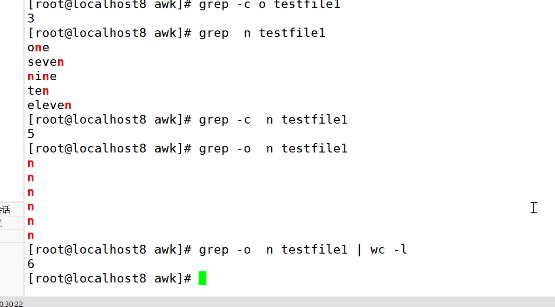
使用BEGIN和END指定操作
awk [选项] 'BEGIN {表达式}; [条件] {操作表达式}; END {表达式}' 文件名...
- BEGIN {操作1} awk在读取文件之前执行的操作
- [条件] {操作2} awk 逐行读取文件时执行的操作
- END {操作3} awk在处理完文件所有行之后执行的操作
输出结尾为nologin的行,并为每行计数显示行号,最后输出总行数
awk 'BEGIN {a=0}; /nologin$/ {a++; print a,$0}; END {print " 共有"a"行"}' /\etc/passwd
begin处理之前的操作,and处理之后的操作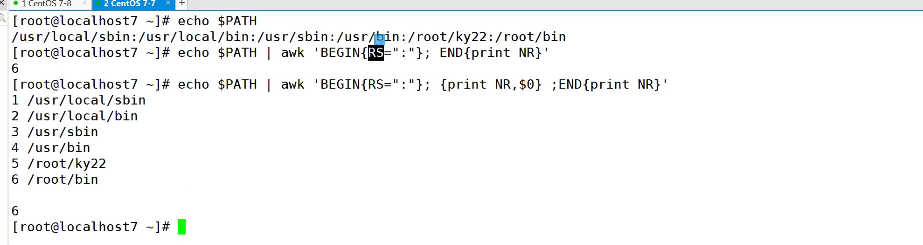
使用管道符号,双引号调用shell命令
输出以:分割的第1和3个字段
echo $PATH |awk 'BEGIN {FS=":"}; {print $1,$3}'
输出$PATH的每个文件
echo $PATH |awk 'BEGIN {RS=":"}; {print NR,$0} END {print "共有"NR"行"}'
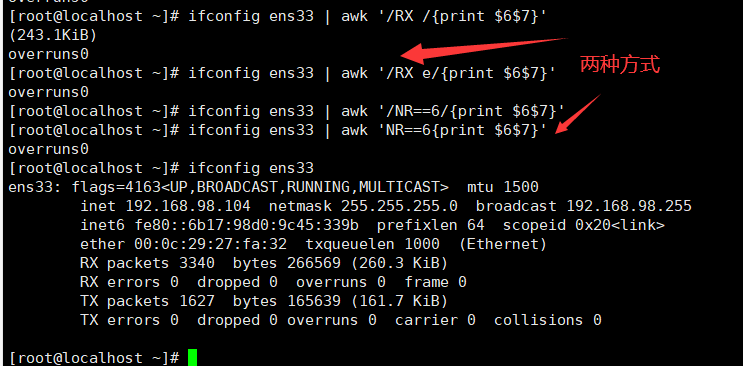
输出ens33网卡的ip和mac地址
ifconfig ens33 |awk 'NR==2 {print $2}'
ifconfig ens33 |awk '/ether/ {print $2}'
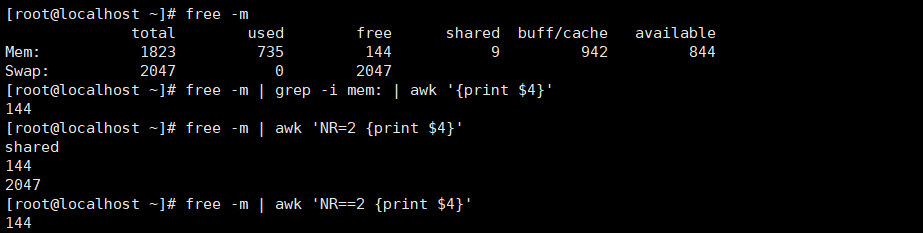
内存占用多少MB
free -m | awk 'NR==2 {print $3}'
free -m | awk '/Mem/ {print $3}'
内存占用率
free -m | awk '/Mem/ {print ($4/$2*100)"%"}'
free -m | awk '/Mem/ {print int($4/$2*100)"%"}'
CPU空闲率
top -b -n1 |awk -F "," '/Cpu/ {print $4}' |awk '{print $1"%"}'
开机时间
date -d "$(awk '{print $1}' /proc/uptime) second ago" +"%Y%m%d %H:%M:%S"
date -d "-$(awk '{print $1}' /proc/uptime) second" +"%Y%m%d %H:%M:%S"
系统上一次重启时间
date -d "$(awk '{print $1}' /proc/uptime') second ago" +"%Y%m%d %H:%M:%S" 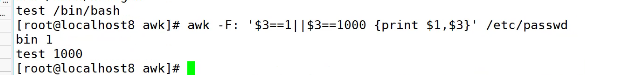


延伸学习
getline
- 当getline左右无重定向符“<”或“|”时,awk首先读取到了第一行,就是1,然后getline,就得到了1下面的第二行,就是2,因为getline之后,awk会改变对应的NF,NR,FNR和$0等内部变量,所以此时的$0的值就不再是1,而是2了,然后将它打印出来。
- 当getline左右有重定向符“<”或“|”时,getline则作用于定向输入文件,由于该文件是刚打开,并没有被awk读入一行,只是getline读入,那么getline返回的是该文件的第一行,而不是隔行。
打印偶数行相当于(n:p)效果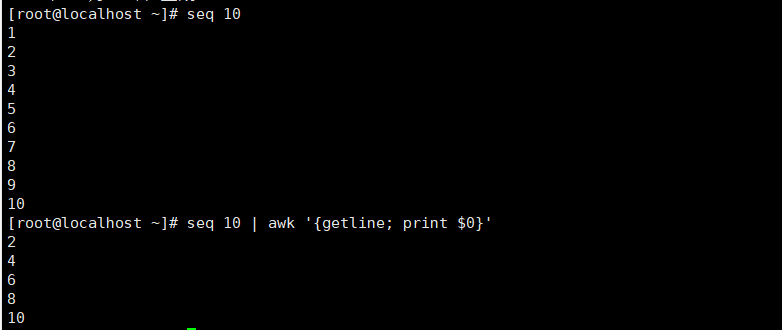
利用getline输出主机名
awk 'BEGIN {"hostname" |getline ;{print $0} }'
利用getline读取w命令显示的行数,统计出在线用户数(减去前2个无关行)
w |awk 'NR>2 {print $0 | "wc -l"}'
OFS
利用OFS输出第1和3个字段,并用:作为输出的分隔符
echo "A B C D" |awk '{OFS=":";print $1,$3}'
利用OFS指定分割符输出整行内容时,需要使用$1=$1刷新整行内容
echo "A B C D" |awk '{OFS=":";$1=$1;print $0}'
配合数组使用
输出指定数组值
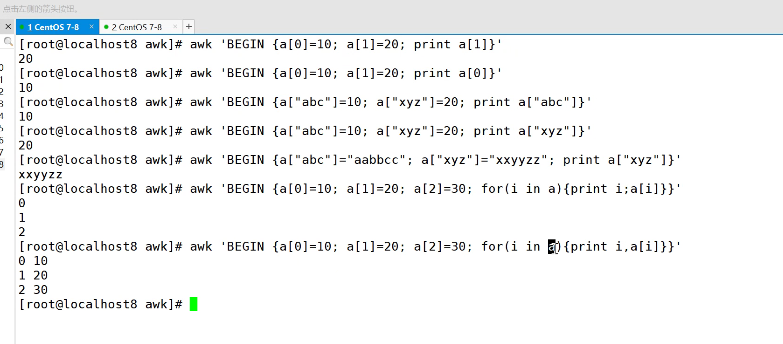
awk 'BEGIN {a[0]=10;a[1]=20;print a[1]}'
使用字符串作为数组索引,输出指定数组值
awk 'BEGIN {a["abc"]=10;a["xyz"]=20;print a["abc"]}'
数组值也可以为字符串
awk 'BEGIN {a["abc"]="aa";a["xyz"]="xx";print a["abc"]}'
遍历数组
awk 'BEGIN {a[0]=10;a[1]=20;a[2]=30; for(i in a) {print i,a[i]}}' 0 10
利用数组做统计
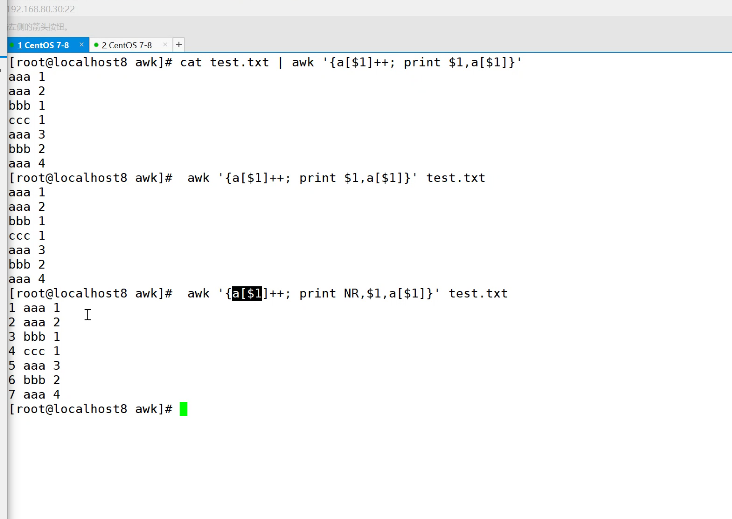
awk 根据指定字段读取每行的字段内容,使用字段内容作为数组的索引,如果出现相同内容的行,则用这个行内容做的数组的值自增1;END{ for(i in arr) {print arr[i],i} awk 读取完所有行内容后,使用for循环遍历这个数组的下标,打印每个下标出现的次数和下标的值。
awk '{arr{$n}++}; END{ for(i in arr) {print arr[i],i}' 文件名..
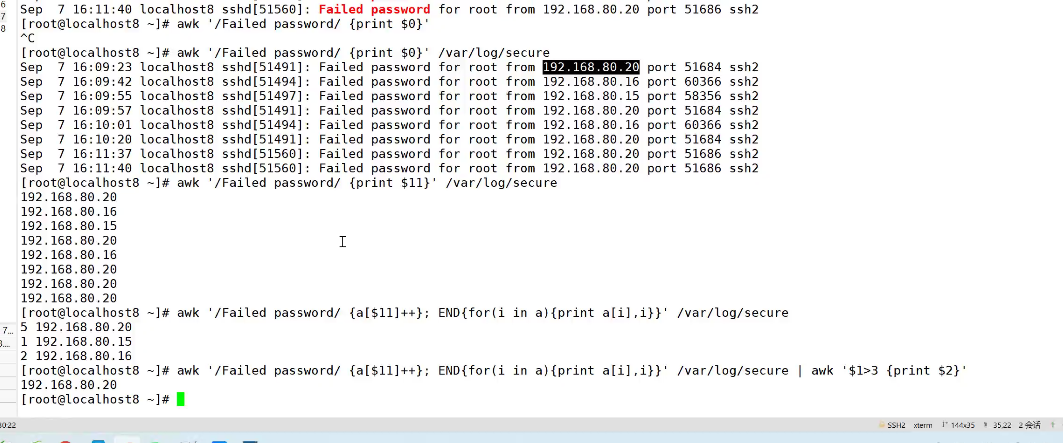
实例:利用数组统计,过滤输入密码超过3次的主机ip
awk '/Failed password/ {a[$13]++};END{for(i in arr) {print arr[i],i}}' /var/log/secure |awk '$1>3 {print $2}'
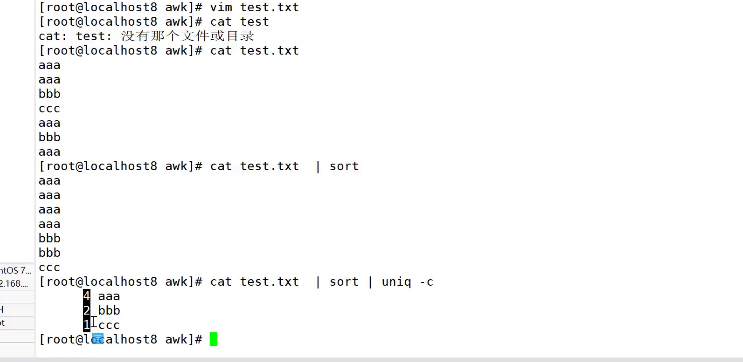
实例:利用数组统计,输出文件中各行出现的次数并排序
cat test.txt | awk '{arr[$1]++}; END{for(i in arr) {print arr[i],i}}' test.txt |sort -rn
利用数组去重
- awk '1' 就是 awk '1{print}' ,允许打印读入的行内容,例:echo 123 | awk '1'
- awk '0' 就是 awk '0{print}' ,不允许打印读入的行内容,例:echo 123 | awk '0'
- var++ 的形式:先读取 var 变量值,再对 var 值 +1
- awk 处理第一行时:先读取 a[$1] 值再自增,a[$1] 即 a[1] 值为空(即0),即为 awk '!0',即为 awk '1',即为 awk'1{print}'
- awk 处理第二行时:先读取 a[$1] 值再自增,a[$1] 即 a[1] 值为 1,即为 awk '!1',即为 awk '0',即为 awk '0{print}'

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









