




去重
select distinct fieldname from tablename;
拼接字符串
select concat(fieldA, fieldB) as field from tablename;
显示表结构
desc tablename;
去除null值的影响
select ifnull(fieldname, 0) from tablename;
如果fieldname的值是null,就显示为0
where中的条件运算符
> < = != <> >= <= && || ! and or not
模糊查询
like
选择字段中含有某个指定字符/字符串的数据
select fieldname from table_name
where fieldname like "%a%";
查询字段中第3个字符为3第5个字符为a的数据
select * from table_name
where fieldname like "__e_a%";
escape
模糊查询中的转义字符
select * from table_name
where fieldname like "_$_%" escape '$';
表示$符号是转义标志。上面sql语句的功能是匹配第二字符是下划线的数据。
因为下划线在模糊查询中表示任意的单个字符,所有如果是本来就要匹配下划线需要添加转义标志。
between and
查询字段的值处于某个区间的数据内容
select * from table_name
where fieldname between 10 and 100;
between and是包含临界值的,不要调换上下边界的位置
in
fieldname这个字段值为’Usage’或者’Credit’的数据
select * from table_name
where fieldname in ('Usage', 'Credit');
in方法不支持通配符和模糊查询。比如
select * from table_name
where fieldname in ('%a%');
就只能查询该字段内容为"%a%"的数据,而不是查询该字段包含a的数据。
is null
用于查询某个字段值为null的数据
select * from table_name
where fieldname is null;
# where fieldname is not null
安全等于<=>
select * from table_name
where fieldname <=> 300;
筛选fieldname这个字段值为300的数据(可以应对null值的情况)
排序
select * from table
where field1 > 0
order by field2 asc|desc, field3 asc|desc;
order by是默认升序的
大小写
select lower('FEFE');
select upper('fwef');
截取字符串
截取从第2个字节开始的子字符串(索引从1开始)
select substr('this is a text', 2) as out_put_text;
截取从第2个字节开始,总长度为5的子字符串(索引从1开始)
select substr('this is a text', 2,5) as out_put_text;
日期
select now(); # 返回当前日期+时间
select curdate(); # 返回当前日期
select curtime(); # 返回当前时间
select year(now());
select year('2020-03-01') 年; # 显示为2020
select month(now());
select monthname(now()); # 显示英文的月名称
将字符串转换为日期
select str_to_date('2020-04-06', '%Y-%m-%d') as today;

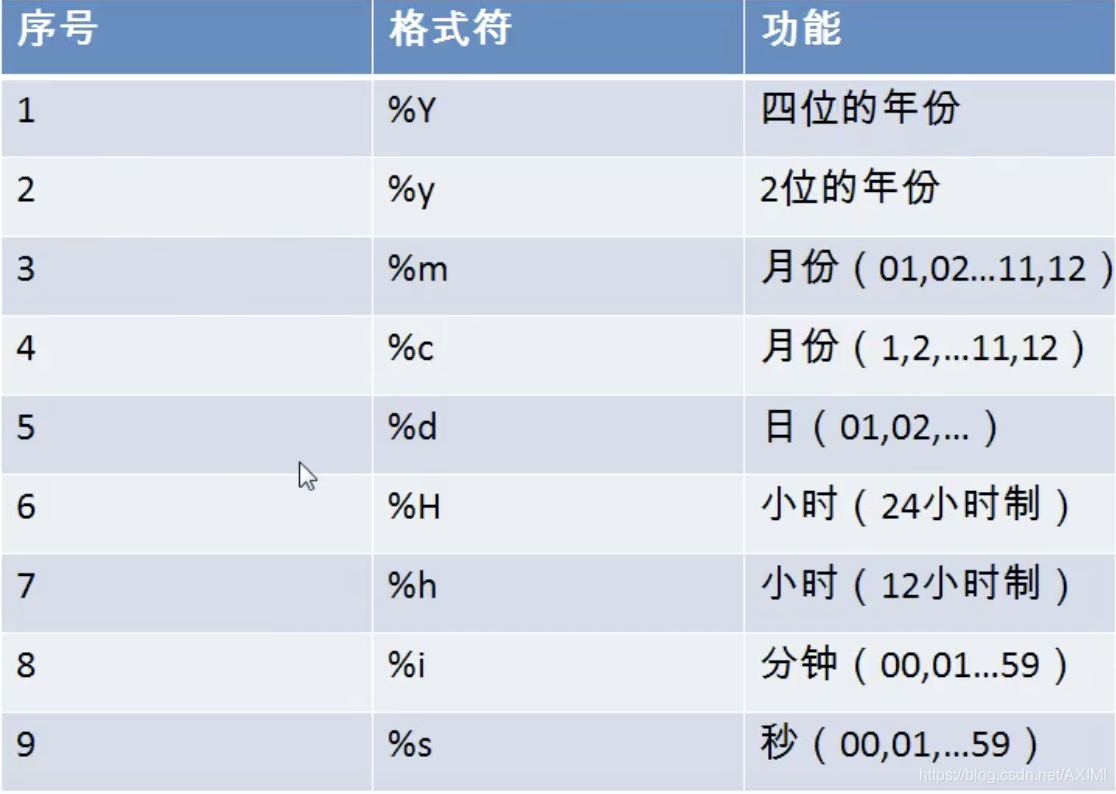
将日期转换为字符串
select date_format(now(), '%Y-%m-%d') as today;
获得日期的差值
select datediff('2020-05-1', '2020-05-03'); # 返回2
其他函数
select version();
select database();
select user();
流程控制函数
if函数:
select if(3<10, 'true', 'false');
select fieldA, fieldB if(fieldC is null, 'true', 'false') from table_name;
case函数:
select child,
case child
when 'girl' then 'pink'
when 'boy' then 'blue'
else 'white'
end as candy_color
from table_name;
分组函数
sum avg max min count
count是计算某个字段不为空的数量
这些分组函数都会自动忽略null值
select count(*) from table_name;
select count(1) from table_name;
第一句是数不全为null的数据有多少行(差不多就相当于数整个表有多少行)
第二句相当于在原表中加了一个字段,这个字段的值全为1,然后统计这个字段有多少行,这个就相当于真正地计算数据表有多少行。

和分组函数一起查询的字段一般是group by的字段
group by
group by可以和having一起使用。where的筛选条件是在group by之前,having的筛选条件在group by之后,例如筛选每种颜色糖果数量大于5的有哪些:
select count(*), candy_color
from table_name
where count(*) > 5
group by candy_color;
上面这种筛选方法是错误的,因为where的筛选条件在group by之前,而group by之前是没有count(*)的字段的。下面这种查询方式是正确的:
select count(*), candy_color
from table_name
group by candy_color;
having count(*) > 5
上面这种查询方式先执行group by然后对分组之后的count(*)进行筛选。

















 1431
1431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









