




 本文深入解析MongoDB的聚合框架,包括基本的聚合运算如count、distinct等,重点介绍了聚合管道的使用,涵盖$project、$match、$limit等操作符的功能与应用,以及$group、$sort、$lookup等高级操作,帮助读者掌握复杂数据处理技巧。
本文深入解析MongoDB的聚合框架,包括基本的聚合运算如count、distinct等,重点介绍了聚合管道的使用,涵盖$project、$match、$limit等操作符的功能与应用,以及$group、$sort、$lookup等高级操作,帮助读者掌握复杂数据处理技巧。
聚合运算是对数据库中的数据做一些基本操作的运算。
MongoDB中的原生聚合运算有:count、distinct、group和mapreduce
聚合管道是比聚合运算更综合的工具,能够在分片集群中很好地运用
文章目录
聚合运算
数量查询count()
count()用于统计文档的数量,例如:
db.collection_name.count({age: {$gte: 18}})
但是count原理比较简单,只是去统计满足条件的文档的数量,没有考虑分片的情况。在分片集群中,迁移块时同一个文档可能存在于多个不同的分片中,所以在分片集群上使用count()得到的结果可能会比真实值大。
官方推荐使用aggregate来进行shard环境下的count
字段取值范围distinct()
db.runCommand({"distinct": collection_name, "key": field_name})
可以查询在collection_name这个集合中,field_name字段下所有的数据的取值都有哪些
分组group()
group()命令在MongoDB3.4版本中已经不推荐使用
实现group最好使用aggregate聚合管道中的group或者mapreduce来实现group
聚合管道aggregate()
聚合管道的表达式如下:
db.collection_name.aggregate(
[{}, {}, ...]
)
aggregate()里面是参数数组,每个花括号对应称为一个管道阶段。每个花括号里面使用不同的管道操作器。aggregate()就通过不同的管道操作器来实现处理数据的目的,同时aggregate()按顺序处理管道阶段操作器。
$project
功能:修改输入文档的结构。可以删除字段,增加字段,拎出子文件的字段数据作为新的根字段。
db.collection_name.aggregate(
[{
$project: {_id: 0
age:1,
phone: "123456789",
lastName: "$name.last"
}
}]
)
上述命令将原集合中的_id字段删除,age字段保留,添加phone字段,设置固定值为"123456789",将一级字段name下的二级字段last子字段设为新的一级字段lastName。
(自己的一些想法:因为_id一般是默认保留的,所以这里使用_id: 0可以强制删除_id字段,同时由于只有age这个字段设值为1,所以原始字段只保留了age这个字段)
$match
功能:找到符合条件的documents
db.collection_name.aggregate(
[{
$match: {"name.last": "Joe"}
}]
)
找到name字段下last字段为Joe的documents
$limit
功能:限制MongoDB聚合管道返回的document数量
db.collection_name.aggregate(
[{limit: 1}]
)
$skip
功能:跳过指定数量的文档,返回剩下的文档
db.collection_name.aggregate(
[{$skip: 2}]
)
$unwind
功能:拆分数组类型字段
对于如下数据:
{"_id":1, "item": "item data", "sizes":["S", "M", "L"]}
使用聚合语句:
db.collection_name.aggregate(
[{
$unwind: {"$sizes"}
}]
)
可以得到以下结果:
{"_id":1, "item": "item data", "sizes":"S"}
{"_id":1, "item": "item data", "sizes":"M"}
{"_id":1, "item": "item data", "sizes":"L"}
注意,拆分出来的结果主键是一样的,不管是使用默认的Objectid还是自己设Id
$group
功能:将集合中的数据分组,用于统计结果
db.shop.aggregate([{$group:{_id:"$type"}}])
group会整理原始的数据来达到理想的效果,但是它不会自动生成"_id"字段,所以一定要自己先定义整理的规则,然后用"_id"这个字段来指定这个规则
$sort
功能:排序
db.collection_name.aggregate([{$sort: {age:-1}}])
$lookup
功能:左连接
内连接:两个集合能匹配的公共部分
左连接:两个集合能匹配的公共部分+第一个集合没匹配上的部分
右连接:两个集合能匹配的公共部分+第二个集合没匹配上的部分
假设现在有两个集合order和product,数据分别如下:
order:
db.order.insert({"_id":1, "pid":1, "name":"order1"})
db.order.insert({"_id":2, "pid":2, "name":"order2"})
db.order.insert({"_id":3, "pid":2, "name":"order3"})
db.order.insert({"_id":4, "pid":1, "name":"order4"})
db.order.insert({"_id":5, "name":"order5"})
db.order.insert({"_id":6, "name":"order6"})
product:
db.product.insert({"_id":1, "name":"product1", "price":99})
db.product.insert({"_id":2, "name":"product2", "price":98})
实现order和product的左连接:
db.order.aggregate([
{
$lookup:
{
from: "product",
localField:"pid",
foreignField: "_id",
as: "orderDetail"
}
}
])
from:左连接中的第二个集合
localField:第一个集合希望匹配的字段
foreignField:第二个集合希望匹配的字段
as:匹配的内容会被创建到"orderDetail"字段中
查询的结果为:
{"_id":1, "pid":1, "name":"order1", "orderDetail":[{"_id":1, "name":"product1", "price":99}]}
{"_id":2, "pid":2, "name":"order2", "orderDetail":[{"_id":2, "name":"product2", "price":98}]}
{"_id":3, "pid":2, "name":"order3", "orderDetail":[{"_id":2, "name":"product2", "price":98}]}
{"_id":4, "pid":1, "name":"order4", "orderDetail":[{"_id":1, "name":"product1", "price":99}]}
{"_id":5, "name":"order5", "orderDetail":[]}
{"_id":6, "name":"order6", "orderDetail":[]}
管道表达式
管道表达式配合管道$aggregate使用的,对集合中的一条条数据进行处理,处理之后输出的结果也是一条条的数据
管道表达式-配合$group使用
假设集合shop中的数据如下:
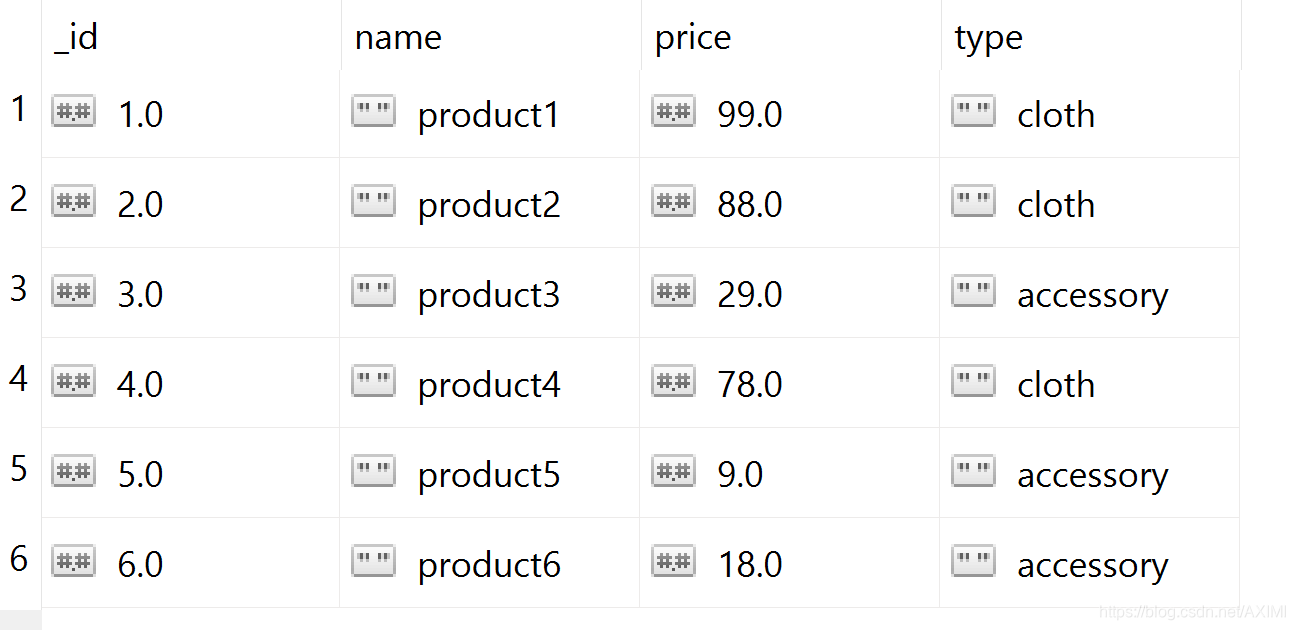
字段分类
db.shop.aggregate([{$group:{_id:"$type"}}])
查询结果:

上面的查询语句将数据的所有type字段分类,输出结果为两条数据,每条数据只有一个字段"_id",字段对应的值为查询出来的type的值。
此处需要注意:
db.shop.aggregate([{$group:{_id:"$type"}}])
和
db.shop.aggregate([{$group:{_id:"type"}}])
的区别,前者是统计原始数据集中type字段的值的集合;
后者只是将"_id"设为了字符串"type",和原始数据集中的数据没有什么关系
求和$sum
db.shop.aggregate([{$group:{_id:"$type", price:{$sum:"$price"}}}])
上面的查询语句创建了两字段
第一个字段为"_id",内容为原数据中的type值
第二个字段为"price",内容为分组文档中的price值的累加,查询结果为:

db.shop.aggregate([{$group:{_id:"$type", prices:{$sum:1}}}])
上面的查询语句创建了两字段
第一个字段为"_id",内容为原数据中的type值
第二个字段为"price",内容为分组文档的个数
查询结果:

上面的查询语句不能写为:
db.shop.aggregate([{$group:{_id:"$type", price:"$price"}}])
因为原数据集按照type有两个分组文档,而按照price会分为6个分组文档,无法整合查询结果。
上面的命令是会报错的
和$sum类似的表达式及对应的意义如下,用法和上面的求和表达式是一样的:
| 管道表达式 | 含义 |
|---|---|
$sum | 求和 |
avg | 平均数 |
max | 最大值 |
min | 最小值 |
添加数组字段$push $addToSet
之前提过下面这种查询命令是非法的:
db.shop.aggregate([{$group:{_id:"$type", price:"$price"}}])
但是可以将price用数组或者集合的形式表示出来:
db.shop.aggregate([{$group:{_id:"$type", prices:{$push:"price"}}}])
查询结果有两个字段,"_id"和"prices",结果如下:

其中addToSet的数据结果中不会重复值,$push的返回结果有重复值
获取分组文档中的收尾元素$first $last
db.shop.aggregate([{$group:{_id:"$type", info:{$first:"$price"}}}])
上面的查询语句将info字段设置为分组文档的第一条数据的price字段的值

















 1229
1229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









