




 Spark SQL 是Spark用于结构化数据处理的模块,提供SparkSession接口与多种数据源交互,支持SQL查询和DataFrame/Dataset API。内容涵盖SparkSession、算子、DataFrame/Dataset操作、SQL查询、数据加载与保存,以及Spark Catalyst优化过程。
Spark SQL 是Spark用于结构化数据处理的模块,提供SparkSession接口与多种数据源交互,支持SQL查询和DataFrame/Dataset API。内容涵盖SparkSession、算子、DataFrame/Dataset操作、SQL查询、数据加载与保存,以及Spark Catalyst优化过程。
Spark SQL
Spark SQL是用于结构化数据处理的一个模块。同Spark RDD 不同地方在于Spark SQL的API可以给Spark计算引擎提供更多地信息,例如:数据结构、计算算子等。在内部Spark可以通过这些信息有针对对任务做优化和调整。这里有几种方式和Spark SQL进行交互,例如Dataset API和SQL等,这两种API可以混合使用。Spark SQL的一个用途是执行SQL查询。 Spark SQL还可用于从现有Hive安装中读取数据。从其他编程语言中运行SQL时,结果将作为Dataset/DataFrame返回,使用命令行或JDBC / ODBC与SQL接口进行交互。
Dataset是一个分布式数据集合在Spark 1.6提供一个新的接口,Dataset提供RDD的优势(强类型,使用强大的lambda函数)以及具备了Spark SQL执行引擎的优点。Dataset可以通过JVM对象构建,然后可以使用转换函数等(例如:map、flatMap、filter等),目前Dataset API支持Scala和Java 目前Python对Dataset支持还不算完备。
Data Frame是命名列的数据集,他在概念是等价于关系型数据库。DataFrames可以从很多地方构建,比如说结构化数据文件、hive中的表或者外部数据库,使用Dataset[row]的数据集,可以理解DataFrame就是一个Dataset[row].
原文链接:https://blog.youkuaiyun.com/weixin_38231448/article/details/89920804
一、SparkSession
Spark中所有功能的入口点是SparkSession类。
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--scala编译插件-->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.0.1</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<!--创建fatjar插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
<!--编译插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
①.算子:
//普通的
package com.baizhi.qickdemo
import com.baizhi.User
import org.apache.spark.sql.SparkSession
case class User(id:Int,name:String,deptno:Int,salary:Double) {}
object SparkSQLHelloWold01 {
def main(args: Array[String]): Unit = {
//1.构建SparkSession
val spark = SparkSession.builder()
.appName("hello world")
.master("local[*]")
.getOrCreate()
//可以将一个集合、RDD转换为Dataset或者是Dataframe
import spark.implicits._
spark.sparkContext.setLogLevel("FATAL") //设置日志级别
//2.创建Dataset或者是Dataframe
var users:List[User]=List(new User(2,"lisi",2,1000),
new User(1,"zhangsan",1,1000),new User(3,"wangwu",1,1500))
val userDateframe = users.toDF()
//3.SparkSQL提供的算子或者SQL脚本
val resultDataFrame = userDateframe.select("id", "name", "salary", "deptNo")
//4.将SQL结果写出带外围系统
resultDataFrame.show()//打印最终结果
//5.关闭session
spark.close()
}
}
日志文件:
#自定义日志
log4j.rootLogger = FATAL,stdout
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = %p %d{yyyy-MM-dd HH:mm:ss} %c %m%n
②.SQL脚本:
package com.baizhi
import com.baizhi.User
import org.apache.spark.sql.SparkSession
case class User(id:Int,name:String,deptno:Int,salary:Double) {}
object SparkSQLHelloWold01 {
def main(args: Array[String]): Unit = {
//1.构建SparkSession
val spark = SparkSession.builder()
.appName("hello world")
.master("local[*]")
.getOrCreate()
//可以将一个集合、RDD转换为Dataset或者是Dataframe
import spark.implicits._
spark.sparkContext.setLogLevel("FATAL")
//2.创建Dataset或者是Dataframe
var users:List[User]=List(new User(2,"lisi",2,1000),
new User(1,"zhangsan",1,1000),new User(3,"wangwu",1,1500))
val userDateframe = users.toDF()
//注册表
userDateframe.createOrReplaceTempView("t_user")
//3.SparkSQL提供的算子或者SQL脚本
val resultDataFrame = spark.sql("select id,name,deptNo,salary,salary * 12 as annual_salary from t_user")
//4.将SQL结果写出带外围系统
resultDataFrame.show()//打印最终结果
//5.关闭session
spark.close()
}
}
DataSet
Dataset与RDD类似,但是,它们不使用Java序列化或Kryo,而是使用专用的Encoder来序列化对象以便通过网络进行处理或传输。虽然Encoder和标准序列化都负责将对象转换为字节,但Encoder是动态生成的代码,并使用一种格式,允许Spark执行许多操作,如过滤,排序和散列,而无需将字节反序列化为对象。
①.json数据
json文件:
{"name":"zly","age":20}
{"name":"zly","age":21}
{"name":"zly3","age":22}
package com.baizhi
import org.apache.spark.sql.{Dataset, SparkSession}
case class Person2(name:String,age:Long){}
object DataSet3 {
def main(args: Array[String]): Unit = {
//1.创建一个SparkSession对象
val sparkSession = SparkSession.builder().master("local[*]").appName("dataset1").getOrCreate()
//.2.设置日志等级
//引入隐式转换
//可以将一个集合、RDD转换为Dataset或者是Dataframe
import sparkSession.implicits._
sparkSession.sparkContext.setLogLevel("FATAL")
//创建dataset
val dataset = sparkSession.read.json("E:\\文档\\大数据\\feiq\\Recv Files\\08-Spark\\代码\\SparkSql\\src\\main\\resources\\word.json").as[Person2]
dataset.show()
//5.关闭sparkSession
sparkSession.stop()
}
}
②.RDD数据
//创建dataset
val Rdd = sparkSession.sparkContext.makeRDD(List((2,"zyl",20)))
val dataset = Rdd.toDS()
DataFrame
Data Frame是命名列的数据集,他在概念是等价于关系型数据库。DataFrames可以从很多地方构建,比如说结构化数据文件、hive中的表或者外部数据库,使用Dataset[row]的数据集,可以理解DataFrame就是一个Dataset[row]。
①.json文件
//创建dataframe
val dataframe = sparkSession.read.json("E:\\文档\\大数据\\feiq\\Recv Files\\08-Spark\\代码\\SparkSql\\src\\main\\resources\\word.json")
dataframe.show()
②.元祖
//创建dataframe
val frame = sparkSession.sparkContext.parallelize(List("zyl1 23", "zyl2 24"))
.map(x => (x.split(" ")(0) ,x.split(" ")(1).toInt))
.toDF("theName","theAge")//可以自定义列名
frame.show()
③.自定义schema
package dataframe
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{BooleanType, DoubleType, IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
object TestCreateDataFrame04 {
def main(args: Array[String]): Unit = {
//1.构建SparkSession
val spark = SparkSession.builder()
.appName("hello world")
.master("local[*]")
.getOrCreate()
import spark.implicits._
//可以将一个集合、RDD转换为Dataset或者是Dataframe
spark.sparkContext.setLogLevel("FATAL")
val userRDD:RDD[Row] = spark.sparkContext.makeRDD(List((1,"张三",true,18,15000.0)))
.map(t=>Row(t._1,t._2,t._3,t._4,t._5))
val fields = Array(new StructField("id", IntegerType),
new StructField("name", StringType),
new StructField("sex", BooleanType),
new StructField("age", IntegerType),
new StructField("salary", DoubleType))
val schema = new StructType(fields)
val userDataframe = spark.createDataFrame(userRDD, schema)
userDataframe.show()
//5.关闭session
spark.close()
}
}
④.java类型
定义一个java类型
package dataframe;
import java.io.Serializable;
public class JavaUser implements Serializable {
private Integer id;
private String name;
public JavaUser(Integer id,String name){
this.id=id;
this.name=name;
}
public JavaUser(){
}
public Integer getId() {
return id;
}
public String getName() {
return name;
}
public void setId(Integer id) {
this.id=id;
}
public void setName(String name) {
this.name = name;
}
}
使用:
//创建一个集合
val userList = List(new JavaUser(1, "zhangsan"), new JavaUser(2, "lisi"))
//创建RDD
val javaUserRDD:RDD[JavaUser] = spark.sparkContext.makeRDD(userList)
//创建DF
val userDataFrame = spark.createDataFrame(javaUserRDD, classOf[JavaUser])
//展示
userDataFrame.show()
二、API操作
准备数据
1,Michael,false,29,2000
5,Lisa,false,19,1000
3,Justin,true,19,1000
2,Andy,true,30,5000
4,Kaine,false,20,5000
代码框架:
package com.baizhi.api
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
case class Userx(id:Int,name:String,sex:Boolean,age:Int,salary:Double)
object MyApi {
def main(args: Array[String]): Unit = {
//创建sparkSession
val session = SparkSession.builder().appName("api").master("local[*]").getOrCreate()
//设置日志级别
session.sparkContext.setLogLevel("FATAL")
//引入改隐试转换 主要是 将 集合、RDD 转换为 DataFrame/Dataset
import session.implicits._
val users = List(
"1,Michael,false,29,2000",
"5,Lisa,false,19,1000",
"3,Justin,true,19,1000",
"2,Andy,true,30,5000",
"4,Kaine,false,20,5000")
//获取rdd
val userlines = session.sparkContext.parallelize(users)
var userRDD:RDD[Userx]=userlines.map(line=>line.split(","))
.map(ts=>Userx(ts(0).toInt,ts(1),ts(2).toBoolean,ts(3).toInt,ts(4).toDouble))
//获取df
val userDataFrame = userRDD.toDF()
//依次填入以下测试的API
//**********************************
//**********************************
//关闭ss
session.close()
}
}
①.printSchema
打印表结构信息
userDataFrame.printSchema()
②.show
默认打印前20行在控制台
userDataFrame.show() //可以指定参数,指定查询几行
③.select
用于过滤,投影出需要的字段信息。直接给列名,不支持计算。
userDataFrame.select("id","name","sex","age","salary").show()
//与$联用,可以计算,
userDataFrame.select($"id",$"name",$"sex",$"age",$"salary",$"salary" * 12 as "annal_salary").show()
④.selectExpr
允许直接给字段名,并指定一些字符串的运算
userDataFrame.selectExpr("id","name || '姓名'","salary * 12 as annal_salary").show()
/*
+---+------------------+------------+
| id|concat(name, 姓名)|annal_salary|
+---+------------------+------------+
| 1| Michael姓名| 24000.0|
| 5| Lisa姓名| 12000.0|
| 3| Justin姓名| 12000.0|
| 2| Andy姓名| 60000.0|
| 4| Kaine姓名| 60000.0|
+---+------------------+------------+
*/
⑤.where
过滤查询结果
userDataFrame.select($"id",$"name",$"sex",$"age",$"salary",$"salary" * 12 as "annal_salary")
.where("name like '%a%'") //<===> .where("name" as "%a%")
.show()
//对于中文的处理
userDataFrame.select($"id",$"name",$"sex",$"age",$"salary",$"salary" * 12 as "年薪")
.where("name like '%a%'" and $"年薪">12000)
.show()
⑥.withColumn
可以给dataframe添加一个字段信息
userDataFrame.select($"id",$"name",$"sex",$"age",$"salary")
.withColumn("年薪",$"salary"*12) //参数1:列名 参数2:列值
.show()
⑦.withColumnRenamed
修改现有的字段名
userDataFrame.select($"id",$"name",$"sex",$"age",$"salary")
.withColumn("年薪",$"salary"*12) //参数1:列名 参数2:列值
.withColumnRenamed("年薪","annal_salary")//参数1:已存在的列名 参数2:新列名
.show()
⑧.groupBy
通常和聚合函数一起使用
userDataFrame.select($"id",$"name",$"sex",$"age",$"salary")
.groupBy("sex")
.mean("salary") //计算平均值
.show()
⑨.agg
必须跟在groupBy后面,调用多个聚合函数
//先导入此函数包
import org.apache.spark.sql.functions._
userDataFrame.select($"id",$"name",$"sex",$"age",$"salary")
.groupBy("sex")
.agg(sum("salary") as "sum",avg("salary") as "avg")//<===> .agg("salary"->"sum","salary"->"avg")
.show()
⑩.开窗函数 over
排名
/先导入此函数包
import org.apache.spark.sql.functions._
//创建WindowSpac类型
val w = Window.partitionBy("sex")
.orderBy($"salary" desc) //排序规则
.rowsBetween(Window.unboundedPreceding,Window.currentRow) //从第一行到当前行
userDataFrame.select($"id",$"name",$"sex",$"age",$"salary")
.withColumn("salary_rank",dense_rank() over(w))//需要windowspec类型
.show()
val sql="select * , ROW_NUMBER() over(partition by deptno order by salary DESC) rank from t_emp"
spark.sql(sql).show()
⑪.cube
实现多维度分析计算
//先导入此函数包
import org.apache.spark.sql.functions._
//创建WindowSpac类型
userDataFrame.select($"id",$"name",$"sex",$"age",$"salary")
.cube($"age",$"sex")//从这两个字段构建的多个维度计算
.avg("salary") //计算平均值
.show()
⑫.pivot
用于行转列
case class UserCost(id:Int,category:String,cost:Double) //创建此类
import org.apache.spark.sql.functions._
var userCostRDD=session.sparkContext.parallelize(List(
UserCost(1,"电子类",100),
UserCost(1,"电子类",20),
UserCost(1,"母婴类",100),
UserCost(1,"生活用品",100),
UserCost(2,"美食",79),
UserCost(2,"电子类",80),
UserCost(2,"生活用品",100)
))
var categories=userCostRDD.map(uc=>uc.category).distinct.collect() //去重获取一个set集合 3个元素
userCostRDD.toDF("id","category","cost")
.groupBy("id") //根据哪个属性分组
.pivot($"category",categories) //根据那个属性进行转换
.sum("cost") //合并一个分组下的此字段
.show()
⑬.na
提供了对null值字段数据的自动填充
na.fill() 表示填充,参数表示填充类型
drop算子,删除一些符合条件的行
import org.apache.spark.sql.functions._
var userCostRDD=session.sparkContext.parallelize(List(
UserCost(1,"电子类",100),
UserCost(1,"电子类",20),
UserCost(1,"母婴类",100),
UserCost(1,"生活用品",100),
UserCost(2,"美食",79),
UserCost(2,"电子类",80),
UserCost(2,"生活用品",100)
))
var categories=userCostRDD.map(uc=>uc.category).distinct.collect() //去重获取一个set集合 3个元素
userCostRDD.toDF("id","category","cost")
.groupBy("id") //根据哪个属性分组
.pivot($"category",categories) //根据那个属性进行转换
.sum("cost")
//.na.drop(4)//如果少于四个非空,删除
// .na.drop("any")//只要有一个为null,就删除,`all`都为null才删除
// .na.drop(List("美食","母婴类"))//如果指定列出null、删除
.na.fill(Map("美食"-> -1,"母婴类"-> 1000))//指定替换类型
.show()
⑭.join
var userCostRDD=session.sparkContext.parallelize(List(
UserCost(1,"电脑配件",100),
UserCost(1,"母婴用品",100),
UserCost(1,"生活用品",100),
UserCost(2,"居家美食",79),
UserCost(2,"消费电子",80),
UserCost(2,"生活用品",100)
))
var theRDD=session.sparkContext.parallelize(List(
User01(1,"张晓三",true,18,15000),
User01(2,"李晓四",true,18,18000),
User01(3,"王晓五",false,18,10000)
))
//获取一个set集合
val categories = userCostRDD.map(_.category).distinct().collect()
userCostRDD.toDF("id","category","cost")
.as("c") //指定表别名
.groupBy("id") //分组条件
.pivot($"category",categories) //将按照哪个属性进行转换
.sum("cost") //将一个分组下的同属性下的数据求和
//进行连接
.join(theRDD.toDF("id","name","sex","age","salary").as("u"),$"c.id"===$"u.id","LEFT_OUTER")
.na.fill(0.0)
.show()
/*
+---+--------+--------+--------+--------+--------+---+------+----+---+-------+
| id|母婴用品|消费电子|电脑配件|生活用品|居家美食| id| name| sex|age| salary|
+---+--------+--------+--------+--------+--------+---+------+----+---+-------+
| 1| 100.0| 0.0| 100.0| 100.0| 0.0| 1|张晓三|true| 18|15000.0|
| 2| 0.0| 80.0| 0.0| 100.0| 79.0| 2|李晓四|true| 18|18000.0|
+---+--------+--------+--------+--------+--------+---+------+----+---+-------+
*/
⑮.dropDuplicates
删除记录中的重复记录,类似于去重。
import org.apache.spark.sql.functions._
var userCostRDD=session.sparkContext.parallelize(List(
UserCost(1,"电子类",100),
UserCost(1,"电子类",20),
UserCost(1,"母婴类",100),
UserCost(1,"生活用品",100),
UserCost(2,"美食",79),
UserCost(2,"电子类",80),
UserCost(2,"生活用品",100)
))
userCostRDD.toDF().dropDuplicates("category").show() //不给参数,需要所有字段都重复才生效
/*
+---+--------+-----+
| id|category| cost|
+---+--------+-----+
| 1| 电子类|100.0|
| 2| 美食| 79.0|
| 1|生活用品|100.0|
| 1| 母婴类|100.0|
+---+--------+-----+
*/
⑯.drop
删除指定列的信息
import org.apache.spark.sql.functions._
var userCostRDD=session.sparkContext.parallelize(List(
UserCost(1,"电子类",100),
UserCost(1,"电子类",20),
UserCost(1,"母婴类",100),
UserCost(1,"生活用品",100),
UserCost(2,"美食",79),
UserCost(2,"电子类",80),
UserCost(2,"生活用品",100)
))
userCostRDD.toDF().drop("cost").show()
⑰.orderBy
按照指定字段排序
import org.apache.spark.sql.functions._
var userCostRDD=session.sparkContext.parallelize(List(
UserCost(1,"电子类",100),
UserCost(1,"电子类",20),
UserCost(1,"母婴类",100),
UserCost(1,"生活用品",100),
UserCost(2,"美食",79),
UserCost(2,"电子类",80),
UserCost(2,"生活用品",100)
))
userCostRDD.toDF().orderBy($"cost" asc).show()
/*
+---+--------+-----+
| id|category| cost|
+---+--------+-----+
| 1| 电子类| 20.0|
| 2| 美食| 79.0|
| 2| 电子类| 80.0|
| 1|生活用品|100.0|
| 2|生活用品|100.0|
| 1| 电子类|100.0|
| 1| 母婴类|100.0|
+---+--------+-----+*/
⑱.limit
只能限定条数,类似RDD中的 take(n)
userCostRDD.toDF().orderBy($"cost" asc).limit(2).show()
⑲filter
过滤一些不符合要求的数据集
//三种写法等价
userCostRDD.toDF().orderBy($"cost" asc).limit(2).filter("category != '美食' ").show() //过滤条件
userCostRDD.toDF().orderBy($"cost" asc).limit(2).filter($"category" =!= "美食").show() //表达式
userCostRDD.toDF().orderBy($"cost" asc).limit(2).filter(i=> !(i.getAs[String]("category").equals("美食"))).show() //函数
/*
+---+--------+----+
| id|category|cost|
+---+--------+----+
| 1| 电子类|20.0|
+---+--------+----+
*/
⑳.map
类似RDD中的map,处理DataFrame中的Row类型
//获取DF类型
var dataFrame = userCostRDD.toDF()
//使用map操作Row类型
val dataSet:Dataset[(Int,String,Double)] = dataFrame.map(row=>(row.getAs[Int]("id"),row.getAs[String]("category"),row.getAs[Double]("cost")))
dataSet.show()
/*
+---+--------+-----+
| _1| _2| _3|
+---+--------+-----+
| 1| 电子类|100.0|
| 1| 电子类| 20.0|
| 1| 母婴类|100.0|
| 1|生活用品|100.0|
| 2| 美食| 79.0|
| 2| 电子类| 80.0|
| 2|生活用品|100.0|
+---+--------+-----+
*/
**.rdd
可以将Dataset[T] 或者DataFrame类型转变成RDD[T]或者是RDD[Row]
//获取DF类型
var dataFrame = userCostRDD.toDF()
//使用map操作Row类型
val dataSet:Dataset[(Int,String,Double)] = dataFrame.map(row=>(row.getAs[Int]("id"),row.getAs[String]("category"),row.getAs[Double]("cost")))
dataSet.rdd.foreach(s=>println(s._1+"\t"+s._2+"\t"+s._3))
/*
1 电子类 100.0
1 生活用品 100.0
1 电子类 20.0
1 母婴类 100.0
2 电子类 80.0
2 生活用品 100.0
*/
三、DataF/S SQL
数据准备:
t_user 文件
chael,29,20000,true,MANAGER,1
Andy,30,15000,true,SALESMAN,1
Justin,19,8000,true,CLERK,1
Kaine,20,20000,true,MANAGER,2
Lisa,19,18000,false,SALESMAN,2
t_dept 文件
1,研发
2,设计
3,产品
上传至hdfs文件系统
package com.baizhi.sql
import org.apache.spark.sql.SparkSession
object TestSql {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder().appName("sql").master("local[*]").getOrCreate()
//设置日志级别
spark.sparkContext.setLogLevel("FATAL")
//引入隐式转换
import org.apache.spark.sql.functions._
import spark.implicits._
//创建用户的DF
var userDF = spark.sparkContext.textFile("hdfs://hbase:9000/t_user")
.map(line=>line.split(",")).map(ts=>User(ts(0),ts(1).toInt,ts(2).toDouble,ts(3).toBoolean,ts(4),ts(5).toInt))
.toDF()
//创建部门的DF
val deptDF = spark.sparkContext.textFile("hdfs://hbase:9000/t_dept")
.map(line=>line.split(","))
.map(ts=>Dept(ts(0).toInt,ts(1)))
.toDF()
//注册表的视图
userDF.createOrReplaceTempView("t_user")
deptDF.createOrReplaceTempView("t_dept")
val sql =
//在以下填写sql
//*************************************************
"""
select * ,salary * 12 as annal_salary from t_user
"""
//**************************************************
//执行sql
spark.sql(sql).show()
//关闭ss
spark.close()
}
}
①. like模糊
select * ,salary * 12 as annal_salary from t_user where name like '%a%'
②.排序查询
order by
select * from t_user order by deptNo asc,salary desc #部门的升序,薪资的降序
③.limit查询
select * from t_user order by deptNo asc,salary desc limit 3
④.分组查询
select deptNo,avg(salary) avg from t_user group by deptNo
⑤.Having过滤
select deptNo,avg(salary) avg from t_user group by deptNo having avg > 15000
⑥.case-when 匹配
select deptNo,name,salary,sex,
(case sex when true then '男' else '女' end) as user_sex,
(case when salary >=20000 then '高薪' when salary >= 15000 then '中等' else
'低薪' end) as level from t_user
+------+------+-------+-----+--------+-----+
|deptNo| name| salary| sex|user_sex|level|
+------+------+-------+-----+--------+-----+
| 1| chael|20000.0| true| 男| 高薪|
| 1| Andy|15000.0| true| 男| 中等|
| 1|Justin| 8000.0| true| 男| 低薪|
| 2| Kaine|20000.0| true| 男| 高薪|
| 2| Lisa|18000.0|false| 女| 中等|
+------+------+-------+-----+--------+-----+
⑦.行转列
package com.baizhi.sql
import org.apache.spark.sql.SparkSession
object TestSql2 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder().appName("sql").master("local[*]").getOrCreate()
//设置日志级别
spark.sparkContext.setLogLevel("FATAL")
//引入隐式转换
import spark.implicits._
val coursedf = spark.sparkContext.parallelize(List(
(1, "语文", 100),
(1, "数学", 100),
(1, "英语", 100),
(2, "数学", 79),
(2, "语文", 80),
(2, "英语", 100)
)).toDF("id","course","score")
coursedf.createOrReplaceTempView("t_course")
//注册表的视图
val sql =
//在以下填写sql
//*************************************************
"""
select id,
sum(case course when '语文' then score else 0 end) as chinese,
sum(case course when '数学' then score else 0 end) as math,
sum(case course when '英语' then score else 0 end) as english
from t_course group by id
"""
//**************************************************
//执行sql
spark.sql(sql).show()
//关闭ss
spark.close()
}
}
/*
+---+-------+----+-------+
| id|chinese|math|english|
+---+-------+----+-------+
| 1| 100| 100| 100|
| 2| 80| 79| 100|
+---+-------+----+-------+
*/
povit 实现
select * from t_course pivot(max(score) for course in ('语文','数学','英语'))
⑧.表连接
select u.*,d.dname from t_user u left join t_dept d on u.deptNo = d.deptNo
⑨.子查询
select *,
(select sum(t1.salary) from t_user t1 where (t1.deptNo = t2.deptNo) group by t1.deptNo) as total
from t_user t2 left join t_dept d on t2.deptNo=d.deptNo order by t2.deptNo asc,t2.salary desc
+------+---+-------+-----+--------+------+------+-----+-------+
| name|age| salary| sex| job|deptNo|deptNo|dname| total|
+------+---+-------+-----+--------+------+------+-----+-------+
| chael| 29|20000.0| true| MANAGER| 1| 1| 研发|43000.0|
| Andy| 30|15000.0| true|SALESMAN| 1| 1| 研发|43000.0|
|Justin| 19| 8000.0| true| CLERK| 1| 1| 研发|43000.0|
| Kaine| 20|20000.0| true| MANAGER| 2| 2| 设计|38000.0|
| Lisa| 19|18000.0|false|SALESMAN| 2| 2| 设计|38000.0|
+------+---+-------+-----+--------+------+------+-----+-------+
⑩.开窗函数
select *,rank()
over(partition by t2.deptNo order by t2.salary desc) as rank
from t_user t2 left join t_dept d on t2.deptNo=d.deptNo
order by t2.deptNo asc,t2.salary desc
+------+---+-------+-----+--------+------+------+-----+----+
| name|age| salary| sex| job|deptNo|deptNo|dname|rank|
+------+---+-------+-----+--------+------+------+-----+----+
| chael| 29|20000.0| true| MANAGER| 1| 1| 研发| 1|
| Andy| 30|15000.0| true|SALESMAN| 1| 1| 研发| 2|
|Justin| 19| 8000.0| true| CLERK| 1| 1| 研发| 3|
| Kaine| 20|20000.0| true| MANAGER| 2| 2| 设计| 1|
| Lisa| 19|18000.0|false|SALESMAN| 2| 2| 设计| 2|
+------+---+-------+-----+--------+------+------+-----+----+
⑪.cube
多维度分析
select deptNo,job,max(salary),avg(salary) from t_user group by cube(deptNo,job)
等价于
select deptNo,job,max(salary),avg(salary) from t_user group by deptNo,job with cube
+------+--------+-----------+------------------+
|deptNo| job|max(salary)| avg(salary)|
+------+--------+-----------+------------------+
| 1|SALESMAN| 15000.0| 15000.0|
| 1| null| 20000.0|14333.333333333334|
| null| null| 20000.0| 16200.0|
| null|SALESMAN| 18000.0| 16500.0|
| 1| CLERK| 8000.0| 8000.0|
| 2| MANAGER| 20000.0| 20000.0|
| 2| null| 20000.0| 19000.0|
| null| MANAGER| 20000.0| 20000.0|
| null| CLERK| 8000.0| 8000.0|
| 2|SALESMAN| 18000.0| 18000.0|
| 1| MANAGER| 20000.0| 20000.0|
+------+--------+-----------+------------------+
☆ 自定义函数
①.单行函数
UDF
package com.baizhi.sql
import org.apache.spark.sql.SparkSession
object TestSql {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder().appName("sql").master("local[*]").getOrCreate()
//设置日志级别
spark.sparkContext.setLogLevel("FATAL")
//引入隐式转换
import org.apache.spark.sql.functions._
import spark.implicits._
//创建用户的DF
var userDF = spark.sparkContext.textFile("hdfs://hbase:9000/t_user")
.map(line=>line.split(",")).map(ts=>User(ts(0),ts(1).toInt,ts(2).toDouble,ts(3).toBoolean,ts(4),ts(5).toInt))
.toDF()
//创建部门的DF
val deptDF = spark.sparkContext.textFile("hdfs://hbase:9000/t_dept")
.map(line=>line.split(","))
.map(ts=>Dept(ts(0).toInt,ts(1)))
.toDF()
//定义函数
val sexFunction=(sex:Boolean)=>sex match {
case true => "男"
case false => "女"
case default => "性别"
}
val commFunction = (age:Int,salary:Double)=>{
if(age>=30) {
salary + 500
}else{
salary
}
}
//注册用户自定义的函数
spark.udf.register("sexFun",sexFunction)
spark.udf.register("commFun",commFunction)
//注册表的视图
userDF.createOrReplaceTempView("t_user")
deptDF.createOrReplaceTempView("t_dept")
val sql =
//在以下填写sql
//*************************************************
"""
select name,sexFun(sex),age,salary,job,commFun(age,salary) as comm from t_user
"""
//**************************************************
//执行sql
spark.sql(sql).show()
//关闭ss
spark.close()
}
}
+------+---------------+---+-------+--------+-------+
| name|UDF:sexFun(sex)|age| salary| job| comm|
+------+---------------+---+-------+--------+-------+
| chael| 男| 29|20000.0| MANAGER|20000.0|
| Andy| 男| 30|15000.0|SALESMAN|15500.0|
|Justin| 男| 19| 8000.0| CLERK| 8000.0|
| Kaine| 男| 20|20000.0| MANAGER|20000.0|
| Lisa| 女| 19|18000.0|SALESMAN|18000.0|
+------+---------------+---+-------+--------+-------+
②.聚合函数
1.Untyped
1.定义聚合函数
package com.baizhi.sql
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, IntegerType, StructField, StructType}
object AggregateFunction1 extends UserDefinedAggregateFunction{
//接收数据类似
override def inputSchema: StructType = {
StructType(StructField("input",DoubleType):: Nil)
}
//用于作为缓冲中间结果类型
override def bufferSchema: StructType = {
StructType(StructField("count",IntegerType)::StructField("total",DoubleType)::Nil)
}
//最终返回值类型
override def dataType: DataType = {
DoubleType
}
//表示函数输出结果类型是否一致
override def deterministic: Boolean = {
true
}
//设置聚合初始化状态
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0)=0 //总计数
buffer(1)=0.0 //总和
}
//将row中的结果累加到buffer中
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
var historyCount = buffer.getInt(0) //获取迭代之前的数量
var historyTotal = buffer.getDouble(1) //获取迭代之前的总薪资
//如果 input 里面不为空
if(!input.isNullAt(0)){
historyTotal += input.getDouble(0) //累加总薪资
historyCount += 1//累加数量
buffer(0) = historyCount //将再次累加的数量赋值给buffer
buffer(1) = historyTotal
}
}
//做最终汇总操作
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getInt(0) + buffer2.getInt(0) //汇总总人数
buffer1(1) = buffer1.getDouble(1) + buffer2.getDouble(1) //汇总总分数
}
//计算最终结果
override def evaluate(buffer: Row): Any = {
buffer.getDouble(1)/buffer.getInt(0)
}
}
2.测试
package com.baizhi.sql
import org.apache.spark.sql.SparkSession
object TestSql {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder().appName("sql").master("local[*]").getOrCreate()
//设置日志级别
spark.sparkContext.setLogLevel("FATAL")
//引入隐式转换
import org.apache.spark.sql.functions._
import spark.implicits._
//创建用户的DF
var userDF = spark.sparkContext.textFile("hdfs://hbase:9000/t_user")
.map(line=>line.split(",")).map(ts=>User(ts(0),ts(1).toInt,ts(2).toDouble,ts(3).toBoolean,ts(4),ts(5).toInt))
.toDF()
//创建部门的DF
val deptDF = spark.sparkContext.textFile("hdfs://hbase:9000/t_dept")
.map(line=>line.split(","))
.map(ts=>Dept(ts(0).toInt,ts(1)))
.toDF()
//定义函数
val sexFunction=(sex:Boolean)=>sex match {
case true => "男"
case false => "女"
case default => "性别"
}
val commFunction = (age:Int,salary:Double)=>{
if(age>=30) {
salary + 500
}else{
salary
}
}
//注册用户自定义的函数
spark.udf.register("sexFun",sexFunction)
spark.udf.register("commFun",commFunction)
spark.udf.register("salary_avg",AggregateFunction1)
//注册表的视图
userDF.createOrReplaceTempView("t_user")
deptDF.createOrReplaceTempView("t_dept")
val sql =
//在以下填写sql
//*************************************************
"""
select deptNo,salary_avg(salary) as avg,avg(salary) from t_user group by deptNo
"""
//**************************************************
//执行sql
spark.sql(sql).show()
//关闭ss
spark.close()
}
}
3.结果
+------+------------------+------------------+
|deptNo| avg| avg(salary)|
+------+------------------+------------------+
| 1|14333.333333333334|14333.333333333334|
| 2| 19000.0| 19000.0|
+------+------------------+------------------+
2.Type-Safe
1.定义样例类
package com.baizhi.sql
case class Average(total:Double,count:Int){}
2.定义聚合函数
package com.baizhi.sql
import org.apache.spark.sql.{Encoder, Encoders}
import org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema
import org.apache.spark.sql.expressions.Aggregator
object AggregateFunction2 extends Aggregator[GenericRowWithSchema,Average,Double]{
//初始化值
override def zero: Average = Average(0.0,0)
//就算局部结果
override def reduce(b: Average, a: GenericRowWithSchema): Average ={
Average(b.total+a.getAs[Double]("salary"),b.count+1)
}
//将局部结果合并
override def merge(b1: Average, b2: Average): Average = {
Average(b1.total+b2.total,b1.count+b2.count)
}
//计算总结果
override def finish(reduction: Average): Double = {
reduction.total/reduction.count
}
//指定中间结果类型的Encoders
override def bufferEncoder: Encoder[Average] = {
Encoders.product[Average]
}
//最终结果的类型
override def outputEncoder: Encoder[Double] = {
Encoders.scalaDouble
}
}
3.测试
package com.baizhi.sql
import org.apache.spark.sql.SparkSession
object TestSql {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder().appName("sql").master("local[*]").getOrCreate()
//设置日志级别
spark.sparkContext.setLogLevel("FATAL")
//引入隐式转换
import org.apache.spark.sql.functions._
import spark.implicits._
//创建用户的DF
var userDF = spark.sparkContext.textFile("hdfs://hbase:9000/t_user")
.map(line=>line.split(",")).map(ts=>User(ts(0),ts(1).toInt,ts(2).toDouble,ts(3).toBoolean,ts(4),ts(5).toInt))
.toDF()
//注册聚合函数
val myavg = AggregateFunction2.toColumn.name("salary_avg2")
//使用 有类型的聚合函数使用api方式进行测试
userDF.select("deptNo","salary")
.groupBy("deptNo")
.agg(myavg,avg("salary"))
.show()
//关闭ss
spark.close()
}
}
4.结果
+------+------------------+------------------+
|deptNo| salary_avg2| avg(salary)|
+------+------------------+------------------+
| 1|14333.333333333334|14333.333333333334|
| 2| 19000.0| 19000.0|
+------+------------------+------------------+
四、Load & Save
①.parquet文件
parquet仅仅是一种存储格式,它与语言、平台无关,不需要和任何一种数据处理框架绑定
save
write.save
注意:因为是在本地测试,需要修改本地的参数 -DHADOOP_USER_NAME=root
package com.baizhi.save
import com.baizhi.sql.{Dept, User}
import org.apache.spark.sql.{DataFrame, SparkSession}
object TestSql4 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder().appName("sql").master("local[*]").getOrCreate()
//设置日志级别
spark.sparkContext.setLogLevel("FATAL")
//引入隐式转换
import org.apache.spark.sql.functions._
import spark.implicits._
//创建用户的DF
var userDF = spark.sparkContext.textFile("hdfs://hbase:9000/t_user")
.map(line=>line.split(",")).map(ts=>User(ts(0),ts(1).toInt,ts(2).toDouble,ts(3).toBoolean,ts(4),ts(5).toInt))
.toDF()
//创建部门的DF
val deptDF = spark.sparkContext.textFile("hdfs://hbase:9000/t_dept")
.map(line=>line.split(","))
.map(ts=>Dept(ts(0).toInt,ts(1)))
.toDF()
//定义函数
val sexFunction=(sex:Boolean)=>sex match {
case true => "男"
case false => "女"
case default => "性别"
}
val commFunction = (age:Int,salary:Double)=>{
if(age>=30) {
salary + 500
}else{
salary
}
}
//注册用户自定义的函数
spark.udf.register("sexFun",sexFunction)
spark.udf.register("commFun",commFunction)
//注册表的视图
userDF.createOrReplaceTempView("t_user")
deptDF.createOrReplaceTempView("t_dept")
val sql =
//在以下填写sql
//*************************************************
"""
select * from t_user
"""
//**************************************************
//执行sql
val result: DataFrame = spark.sql(sql)
//储存文件 Paquet
result.write
//替换以下内容
//******************************************************
.save("hdfs://hbase:9000/result/paquet")
//******************************************************
//关闭ss
spark.close()
}
}
load
read.load( )
read.parquet( )
package com.baizhi.save
import com.baizhi.sql.{Dept, User}
import org.apache.spark.sql.{DataFrame, SparkSession}
object TestSql5 {
def main(args: Array[String]): Unit = {
//创建sparksession
val spark = SparkSession.builder().appName("sql").master("local[*]").getOrCreate()
//设置日志级别
spark.sparkContext.setLogLevel("FATAL")
//引入隐式转换
import spark.implicits._
import org.apache.spark.sql.functions._
//读取文件
val dataFrame = spark.read
//替换以下内容
//******************************************************
.load("hdfs://hbase:9000/result/paquet")
//等价与 spark.read.parquet("hdfs://hbase:9000/result/paquet")
//******************************************************
dataFrame.printSchema()
dataFrame.show()
//关闭ss
spark.close()
}
}
②.CSV格式
save
write.format(“csv”)
//储存文件 csv
result.write
.format("csv") //储存格式
.mode(SaveMode.Overwrite) //储存方案
.option("sep",",")//指定分隔符
.option("header","true") //是否产生表头信息
.save("hdfs://hbase:9000/result/csv")//储存路径
load
read.format( )
val dataFrame = spark.read .format("csv") //指定数据类型
.option("sep",",")//指定分隔符
.option("inferSchema","true")//参照表schema信息
.option("header","true")//是否产生表头信息
.load("hdfs://hbase:9000/result/csv")//加载文件路径
③.ORC格式
ORC的全称是Optimized Row Columnar,ORC文件格式是一种Hadoop生态圈中的列存储格式,它的产生早在2013年,最早产生自Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。
save
result.write
.format("orc") //储存格式
.mode(SaveMode.Overwrite) //储存方案
.save("hdfs://hbase:9000/result/orc")//储存路径
load
val dataFrame = spark.read
.format("orc") //指定数据类型
.load("hdfs://hbase:9000/result/orc")//加载文件路径
④.JSON格式
save
result.write
.format("json") //储存格式
.mode(SaveMode.Overwrite) //储存方案
.save("hdfs://hbase:9000/result/json")//储存路径
load
val dataFrame = spark.read
.format("json") //指定数据类型
.load("hdfs://hbase:9000/result/json")//加载文件路径
⑤.使用SQL读取
//读取文件
val parquetDF = spark.sql("select * from parquet.`hdfs://hbase:9000/result/paquet`")
val jsonDF = spark.sql("select * from json.`hdfs://hbase:9000/result/json`")
val orcDF = spark.sql("select * from orc.`hdfs://hbase:9000/result/orc`")
parquetDF.show()
jsonDF.show()
orcDF.show()
⑥.JDBC数据读取
1.引入数据库相关依赖
<!--引入mysql 相关依赖-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.42</version>
</dependency>
2.save
//设置数据库配置参数
val properties = new Properties()
properties.put("user","root") //设置用户名
properties.put("password","0")//设置密码
result.write
.mode(SaveMode.Overwrite) //储存方案
.jdbc("jdbc:mysql://hbase:3306/zyl","02_26",properties)//储存路径,表名,连接参数
3.load
val dataFrame = spark.read
.format("jdbc") //读取格式
.option("url", "jdbc:mysql://hbase:3306/zyl") //配置库名
.option("dbtable", "02_26") //配置表名
.option("user", "root") //用户名
.option("password", "0") //密码
.load()
⑦.Spark - Hive
1.相关依赖
<!--spark-Hive的相关依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.4.5</version>
</dependency>
2.添加hive-site.xml文件配置
<!-- 开启Meta Store 服务,用于Spark读取hive中的元数据 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hbase:9083</value>
</property>
3.启动 metastore 服务
./bin/hive --service metastore >/dev/null 2>&1 &
4.测试
package com.baizhi.save
import org.apache.spark.sql.SparkSession
object SparkHive {
def main(args: Array[String]): Unit = {
//创建 sparkSession
val session = SparkSession.builder()
.appName("spark_hive")
.master("local[*]")
.config("hive.metastore.uris", "thrift://hbase:9083") //配置元数据信息
.enableHiveSupport() //启动hive支持
.getOrCreate()
//设置日志级别
session.sparkContext.setLogLevel("FATAL")
//执行sql语句
session.sql("show databases").show()
session.sql("use zyl")
session.sql("select * from t_user").na.fill(0.0).show()
//关闭ss
session.close()
}
}
五、Spark Catalyst
https://blog.youkuaiyun.com/qq_36421826/article/details/81988157
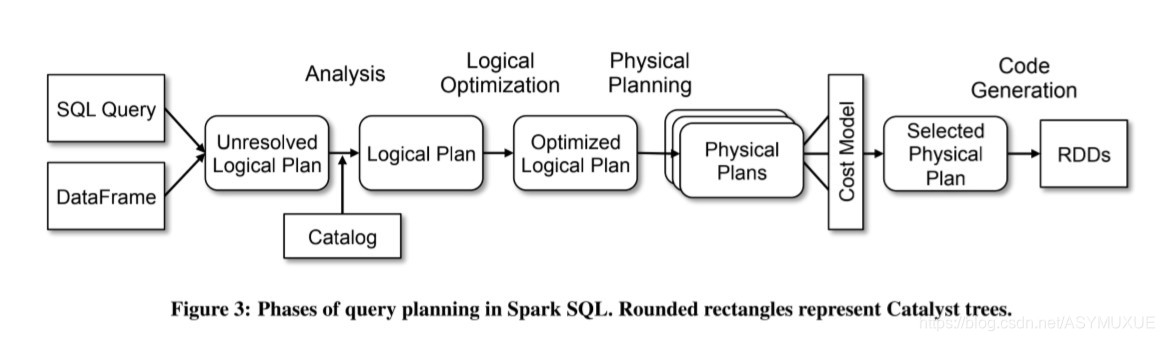
1.SQL语句----------> (parse 解析阶段)
2.未处理的逻辑计划----+分析处理–+表目录内容------> (Analysis 分析阶段)
3.逻辑计划----+逻辑优化处理----> (Optimize 优化阶段)
☆4.优化的逻辑计划-------->
(优化器是整个Catalyst的核心,优化器分为基于规则优化和基于代价优化两种)
谓词下推(Predicate Pushdown) 常量累加(Constant Folding) 列值裁剪(Column Pruning)
5.物理计划-------+代价模型-----> (Physical Planning 物理计划阶段)
6.最优的物理计划
SQL语句首先通过Parser模块被解析为语法树,此棵树称为Unresolved Logical Plan;Unresolved Logical Plan通过Analyzer模块借助于数据元数据解析为Logical Plan;此时再通过各种基于规则的优化策略进行深入优化,得到Optimized Logical Plan;优化后的逻辑执行计划依然是逻辑的,并不能被Spark系统理解,此时需要将此逻辑执行计划转换为Physical Plan

















 3461
3461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









