




选题背景意义
随着信息技术的快速发展和互联网的广泛普及,数字图像作为一种重要的信息载体,在人们的日常生活和工作中扮演着越来越重要的角色。然而,在图像的传输和存储过程中,信息安全问题日益凸显,如何在不引起注意的情况下隐藏和传输秘密信息成为信息安全领域的重要研究方向之一。图像隐写技术作为信息隐藏的重要分支,通过将秘密信息嵌入到载体图像中,实现秘密信息的隐蔽传输,具有广泛的应用前景。
传统的图像隐写方法主要基于空域和频率域的修改,如最低有效位替换、离散余弦变换系数修改等。这些方法虽然实现简单,但存在隐写容量小、鲁棒性差、抗隐写分析能力弱等问题。随着深度学习技术的兴起,基于深度学习的图像隐写方法逐渐成为研究热点。深度学习方法通过构建端到端的神经网络模型,实现了更高的隐写容量、更好的图像质量和更强的抗隐写分析能力。然而,现有的基于深度学习的图像隐写方法在面对常见的图像修改操作时,如裁剪、旋转、压缩等,仍然存在鲁棒性不足的问题,限制了其实际应用。
本研究针对基于深度学习的图像隐写技术展开深入探讨,重点研究如何提高隐写方法的鲁棒性和抗隐写分析能力。首先,分析传统图像隐写方法和基于深度学习的图像隐写方法的研究现状和存在的问题;其次,提出基于生成对抗网络的抗裁剪图像隐写方法,通过添加噪声层和密集连接机制,提高模型在面对裁剪攻击时的鲁棒性;然后,提出基于自注意力机制的图像隐写方法,通过注意力掩码给隐藏信息赋予权重,增强模型对多种噪声攻击的抵抗力;最后,对两种方法进行详细的实验分析和对比,验证其有效性和优越性。本研究对于提高图像隐写技术的安全性和实用性具有重要的理论意义和应用价值。
数据集构建
数据获取
本研究中使用的数据集主要包括COCO数据集和Hollywood2数据集。COCO数据集是一个大规模的目标检测、分割和字幕数据集,包含超过33万张图像,涵盖91个物体类别。该数据集具有丰富的图像内容和多样的场景,适合作为图像隐写方法的载体图像源。Hollywood2数据集包含超过2500个从电影中提取的短视频片段,总计超过20小时的视频内容,适合用于训练和测试视频隐写模型。

为了获取这些数据集,研究人员需要访问相应的官方网站并按照规定的流程进行下载。COCO数据集可从其官方网站获取,提供了多种格式的图像和标注数据。Hollywood2数据集同样可从其官方网站下载,包含视频片段和相应的动作标注。在下载过程中,需要注意数据集的版权问题,确保合法使用。
除了使用公开数据集外,研究人员还可以根据实际需求构建自定义数据集。自定义数据集的构建需要考虑图像的多样性、质量和数量等因素。通常,自定义数据集可以通过网络爬虫从互联网上收集图像,或者使用相机拍摄真实场景的图像。收集到的图像需要进行筛选,去除低质量、重复或不适合作为载体的图像,确保数据集的质量和有效性。对于图像隐写任务,载体图像的选择需要考虑图像的复杂度、纹理和色彩等因素。通常,纹理丰富、色彩多样的图像更适合作为载体图像,因为这样的图像可以隐藏更多的信息而不易被察觉。在实验中,研究人员会从数据集中随机选择图像作为载体,并对其进行预处理,如调整尺寸、裁剪等,以适应模型的输入要求。
数据标注
在图像隐写研究中,数据标注主要涉及到隐藏信息的生成和嵌入位置的标记。隐藏信息通常采用随机生成的二进制数据或文本数据,如数字、英文字母等。在实验中,研究人员会生成固定长度的随机信息,并将其嵌入到载体图像中,形成载密图像。除了隐藏信息的生成外,数据标注还包括对载密图像的质量评估和隐写分析标记。质量评估主要通过计算载密图像与原始图像之间的峰值信噪比和结构相似性等指标来实现,用于衡量隐写方法对图像质量的影响。隐写分析标记则用于训练隐写分析模型,区分原始图像和载密图像。
在实际应用中,数据标注的质量直接影响到模型的训练效果和性能评估。因此,需要确保标注数据的准确性和一致性。对于隐藏信息的生成,需要采用随机化的方法,确保信息的多样性和不可预测性。对于质量评估和隐写分析标记,需要使用标准化的指标和方法,确保评估结果的客观性和可比性。
数据处理
在图像隐写研究中,数据处理是一个重要的环节,直接影响到模型的训练效果和性能。数据处理主要包括图像预处理、数据增强和噪声添加等步骤。将原始图像转换为适合模型输入的格式。通常,需要对图像进行调整尺寸、裁剪、归一化等操作。例如,在本研究中,将图像调整为统一的尺寸(如160×160),并将像素值归一化到0-1之间,以适应模型的输入要求。增加数据集的多样性,提高模型的泛化能力。常用的数据增强方法包括随机翻转、随机裁剪、随机旋转等。在训练过程中,通过对图像进行随机变换,可以生成更多的训练样本,减少过拟合的风险。例如,在本研究中,使用随机水平翻转和随机裁剪等数据增强方法,提高模型的鲁棒性。
噪声添加模拟现实场景中图像可能遭受的攻击,如裁剪、水印、压缩等。在训练过程中,通过向载密图像添加各种噪声,可以提高模型在面对真实攻击时的鲁棒性。例如,在本研究中,添加了裁剪、文字水印、图片水印、压缩、旋转、缩放等多种噪声,训练模型对这些攻击的抵抗力。
功能模块介绍
基于生成对抗网络的抗裁剪图像隐写模块
基于生成对抗网络的抗裁剪图像隐写模块主要用于生成具有抗裁剪能力的载密图像。该模块采用生成对抗网络的架构,包含编码器、噪声层、解码器和评价器四个主要组成部分。编码器负责将秘密信息嵌入到载体图像中,生成载密图像;噪声层用于模拟各种噪声攻击,提高模型的鲁棒性;解码器负责从载密图像中提取隐藏信息;评价器用于评估载密图像的真实性,确保其与原始图像的视觉相似性。
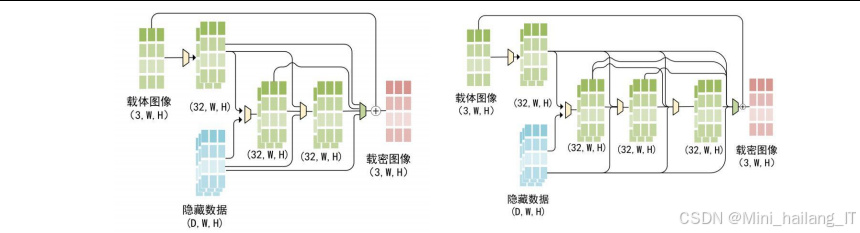
该模块的核心设计思想是通过添加噪声层和密集连接机制,提高模型在面对裁剪攻击时的鲁棒性。噪声层在训练过程中随机向载密图像添加各种噪声,如裁剪、缩放、压缩等,使模型能够学习到在噪声环境下的信息隐藏和提取能力。密集连接机制则通过建立网络层之间的密集连接,缓解梯度消失问题,提高模型的训练效果和性能。
在实现过程中,该模块使用PyTorch深度学习框架进行开发,采用Adam优化器进行模型训练。训练过程中,通过最小化数据重构损失、图像重构损失和真实性损失三个损失函数,实现信息隐藏、图像质量和抗检测能力的平衡。该模块可以处理各种尺寸的图像,并支持不同长度的隐藏信息嵌入,具有较强的灵活性和适用性。
基于自注意力机制的图像隐写模块
基于自注意力机制的图像隐写模块主要用于生成对多种噪声攻击具有鲁棒性的载密图像。该模块同样采用生成对抗网络的架构,但引入了自注意力机制,通过注意力掩码给隐藏信息赋予权重,增强模型对复杂噪声攻击的抵抗力。
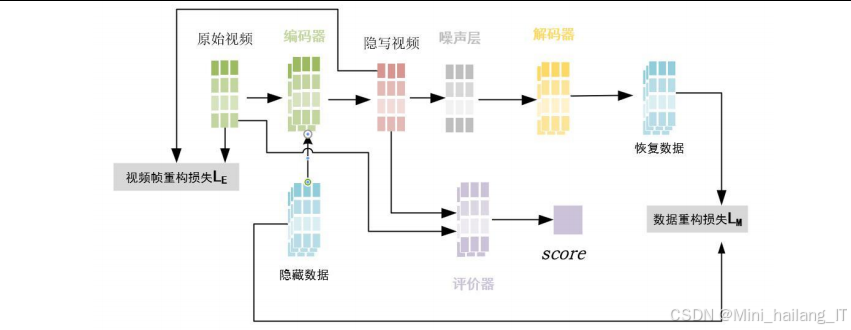
该模块的核心设计思想是利用自注意力机制使模型倾向于将数据隐藏在受转换影响较小的纹理和对象中。注意力模块生成注意力掩码,指示模型应该关注的图像区域,使隐藏信息能够更好地留存。通过这种方式,模型可以学习到在各种噪声攻击下的信息隐藏和提取策略,提高鲁棒性。
在实现过程中,该模块同样使用PyTorch框架进行开发,采用Adam优化器和梯度裁剪等技术进行模型训练。训练过程中,通过添加多种噪声攻击,如裁剪、水印、压缩、旋转、缩放等,提高模型的泛化能力。该模块可以应用于图像和视频隐写任务,通过模型转换实现跨媒体的隐写应用。
隐写分析模块
隐写分析模块主要用于评估隐写方法的抗隐写分析能力,检测载体图像中是否存在隐藏信息。该模块采用多种隐写分析方法,如样本对分析、RS分析、卡方攻击和主集分析等,对载密图像进行综合检测。
该模块的核心设计思想是通过统计分析载密图像的特征差异,区分原始图像和载密图像。隐写分析方法通常基于图像的统计特性,如像素值分布、相邻像素关系等,检测隐写操作引入的微小变化。通过综合多种隐写分析方法的检测结果,可以提高隐写分析的准确性和可靠性。
在实现过程中,该模块使用开源工具StegExpose进行隐写分析测试,该工具集成了多种隐写分析方法,并提供了ROC曲线等评估指标。通过对大量载密图像的分析,可以评估隐写方法的抗检测能力,为方法改进提供依据。该模块可以用于各种隐写方法的性能评估,具有较强的通用性和实用性。
算法理论
生成对抗网络
生成对抗网络是一种深度学习模型,由生成器和判别器两部分组成,通过对抗训练的方式提高模型性能。生成器的目标是生成与真实数据相似的假数据,判别器的目标是区分真实数据和假数据。在训练过程中,生成器和判别器相互竞争,不断提高各自的能力,最终达到纳什均衡状态。
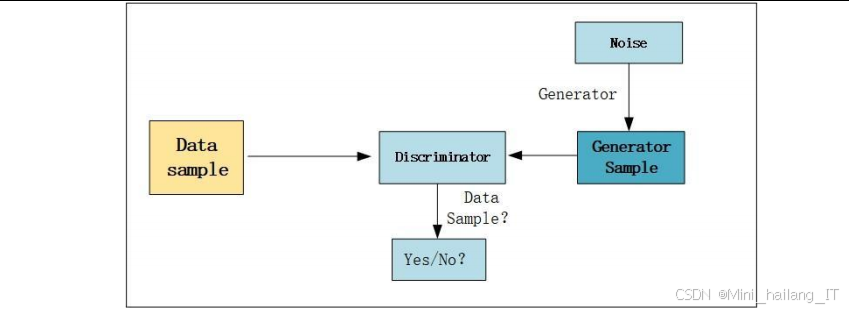
在图像隐写领域,生成对抗网络被广泛应用于生成高隐蔽性的载密图像。生成器负责将秘密信息嵌入到载体图像中,生成载密图像;判别器负责评估载密图像的真实性,确保其与原始图像的视觉相似性。通过对抗训练,生成器可以学习到如何在不引起注意的情况下隐藏信息,提高隐写方法的隐蔽性和抗检测能力。
生成对抗网络的优势在于能够自动学习数据的分布特征,生成高质量的假数据。在图像隐写中,这意味着生成的载密图像具有更好的视觉质量和更高的隐蔽性。然而,生成对抗网络也存在训练不稳定、模式崩溃等问题,需要通过合理的网络设计和训练策略来解决。在本研究中,通过引入密集连接机制和自注意力机制,提高了生成对抗网络的稳定性和性能。
自注意力机制
自注意力机制是一种能够对输入数据中的不同位置之间的依赖关系进行建模的技术。在图像处理中,自注意力机制可以学习到图像中不同区域之间的关联,使模型能够关注重要的图像特征。在图像隐写中,自注意力机制可以帮助模型确定最佳的信息隐藏位置,提高隐写方法的鲁棒性。
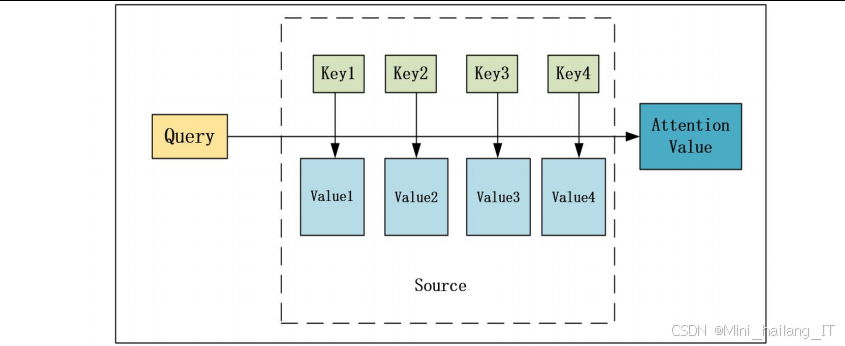
自注意力机制的核心是计算输入数据中每个位置与其他位置之间的注意力权重,然后根据这些权重对输入数据进行加权求和。在图像隐写中,注意力权重指示了每个图像区域对隐藏信息的重要性,模型会优先将信息隐藏在注意力权重高的区域。这些区域通常是图像中纹理丰富、结构稳定的部分,在面对图像修改操作时,隐藏的信息更容易被保留。
自注意力机制的优势在于能够捕捉长距离的依赖关系,提高模型对复杂数据的处理能力。在图像隐写中,这意味着模型可以更好地适应不同的图像内容和噪声攻击,提高隐写方法的鲁棒性和适应性。在本研究中,通过将自注意力机制引入图像隐写模型,显著提高了模型对多种噪声攻击的抵抗力。
密集连接机制
密集连接机制是一种网络连接方式,通过建立网络层之间的密集连接,缓解梯度消失问题,提高模型的训练效果和性能。在密集连接网络中,每个层都与前面所有层直接连接,接收前面所有层的输出作为输入,同时将自己的输出传递给后面所有层。
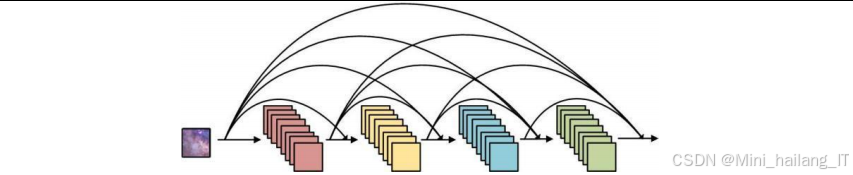
在图像隐写中,密集连接机制可以帮助模型更好地保留和传递图像特征,提高信息隐藏和提取的准确性。当载密图像遭受噪声攻击时,图像特征会受到损失,密集连接机制可以通过多层特征的融合,减少信息丢失,提高解码器的提取能力。
密集连接机制的优势在于能够充分利用网络中的特征信息,提高模型的参数效率和训练稳定性。在图像隐写中,这意味着模型可以在有限的参数下实现更好的性能,减少过拟合的风险。在本研究中,通过将密集连接机制引入抗裁剪图像隐写模型,提高了模型在面对裁剪攻击时的鲁棒性。
核心代码介绍
抗裁剪图像隐写
本部分展示了基于生成对抗网络的抗裁剪图像隐写模型的核心代码,包括编码器、解码器、评价器和噪声层的实现。该模型采用密集连接机制和噪声层设计,提高了在面对裁剪攻击时的鲁棒性。
import torch
import torch.nn as nn
import torch.nn.functional as F
class DenseBlock(nn.Module):
def __init__(self, in_channels, growth_rate):
super(DenseBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, growth_rate, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(in_channels + growth_rate, growth_rate, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(in_channels + 2 * growth_rate, growth_rate, kernel_size=3, padding=1)
self.bn = nn.BatchNorm2d(in_channels + 3 * growth_rate)
def forward(self, x):
out1 = F.relu(self.conv1(x))
out2 = F.relu(self.conv2(torch.cat([x, out1], 1)))
out3 = F.relu(self.conv3(torch.cat([x, out1, out2], 1)))
out = F.relu(self.bn(torch.cat([x, out1, out2, out3], 1)))
return out
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.dense1 = DenseBlock(64, 32)
self.conv2 = nn.Conv2d(192, 128, kernel_size=3, padding=1)
self.dense2 = DenseBlock(128, 32)
self.conv3 = nn.Conv2d(256, 3, kernel_size=3, padding=1)
def forward(self, x, data):
x = F.relu(self.conv1(x))
x = self.dense1(x)
x = F.relu(self.conv2(x))
x = self.dense2(x)
x = torch.tanh(self.conv3(x))
x = x + data
return x
class Decoder(nn.Module):
def __init__(self, data_length):
super(Decoder, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.dense1 = DenseBlock(64, 32)
self.conv2 = nn.Conv2d(192, 128, kernel_size=3, padding=1)
self.dense2 = DenseBlock(128, 32)
self.conv3 = nn.Conv2d(256, data_length, kernel_size=3, padding=1)
self.pool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.dense1(x)
x = F.relu(self.conv2(x))
x = self.dense2(x)
x = self.conv3(x)
x = self.pool(x)
x = x.view(x.size(0), -1)
x = torch.sigmoid(x)
return x
class Critic(nn.Module):
def __init__(self):
super(Critic, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(64, 1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = self.pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
class NoiseLayer(nn.Module):
def __init__(self):
super(NoiseLayer, self).__init__()
def forward(self, x):
# 随机选择噪声类型
noise_type = torch.randint(0, 7, (1,))
# 裁剪
if noise_type == 0:
crop_size = int(x.size(2) * 0.9)
start_x = torch.randint(0, x.size(2) - crop_size, (1,))
start_y = torch.randint(0, x.size(3) - crop_size, (1,))
x = x[:, :, start_x:start_x+crop_size, start_y:start_y+crop_size]
x = F.interpolate(x, size=(x.size(2), x.size(3)))
# 缩放
elif noise_type == 1:
scale_factor = torch.rand(1) * 0.4 + 0.8
x = F.interpolate(x, scale_factor=scale_factor.item())
x = F.interpolate(x, size=(x.size(2), x.size(3)))
# 压缩
elif noise_type == 2:
# 模拟JPEG压缩
x = torch.round(x * 255) / 255
# 高斯噪声
elif noise_type == 3:
noise = torch.randn_like(x) * 0.05
x = x + noise
x = torch.clamp(x, 0, 1)
# 裁剪并填充
elif noise_type == 4:
crop_size = int(x.size(2) * 0.8)
start_x = torch.randint(0, x.size(2) - crop_size, (1,))
start_y = torch.randint(0, x.size(3) - crop_size, (1,))
mask = torch.ones_like(x)
mask[:, :, start_x:start_x+crop_size, start_y:start_y+crop_size] = 0
x = x * mask
# 随机丢弃像素
elif noise_type == 5:
mask = torch.rand_like(x) > 0.9
x = x * mask
# 水印
elif noise_type == 6:
watermark = torch.randn_like(x) * 0.1
x = x + watermark
x = torch.clamp(x, 0, 1)
return x
上述代码实现了基于生成对抗网络的抗裁剪图像隐写模型的核心组件。DenseBlock类实现了密集连接块,通过多层卷积和特征融合提高模型性能;Encoder类实现了编码器,负责将数据嵌入到图像中;Decoder类实现了解码器,负责从图像中提取数据;Critic类实现了评价器,负责评估图像的真实性;NoiseLayer类实现了噪声层,负责添加各种噪声攻击。
该模型的主要特点是采用了密集连接机制和多种噪声攻击模拟,提高了模型在面对裁剪攻击时的鲁棒性。通过将密集连接引入编码器和解码器,可以更好地保留图像特征,减少信息丢失;通过添加多种噪声攻击,可以提高模型的泛化能力,使其能够适应复杂的现实环境。
图像隐写模型
本部分展示了基于自注意力机制的图像隐写模型的核心代码,包括注意力模块、编码器、解码器和评价器的实现。该模型通过引入自注意力机制,提高了对多种噪声攻击的抵抗力。
import torch
import torch.nn as nn
import torch.nn.functional as F
class AttentionModule(nn.Module):
def __init__(self, in_channels, out_channels):
super(AttentionModule, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, out_channels, kernel_size=3, padding=1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.conv2(x)
x = F.softmax(x, dim=1)
return x
class Encoder(nn.Module):
def __init__(self, data_length):
super(Encoder, self).__init__()
self.attention = AttentionModule(3, data_length)
self.conv1 = nn.Conv2d(3 + data_length, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 3, kernel_size=3, padding=1)
def forward(self, x, data):
# 生成注意力掩码
attention_mask = self.attention(x)
# 将数据扩展到图像大小
data = data.view(data.size(0), -1, 1, 1)
data = data.repeat(1, 1, x.size(2), x.size(3))
# 应用注意力掩码
data = data * attention_mask
# 连接图像和数据
x = torch.cat([x, data], 1)
# 编码
x = F.relu(self.conv1(x))
x = torch.tanh(self.conv2(x))
# 残差连接
x = x + data[:, :3, :, :]
return x
class Decoder(nn.Module):
def __init__(self, data_length):
super(Decoder, self).__init__()
self.attention = AttentionModule(3, data_length)
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, data_length, kernel_size=3, padding=1)
self.pool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
# 生成注意力掩码
attention_mask = self.attention(x)
# 解码
x = F.relu(self.conv1(x))
x = self.conv2(x)
# 应用注意力掩码
x = x * attention_mask
# 池化提取数据
x = self.pool(x)
x = x.view(x.size(0), -1)
x = torch.sigmoid(x)
return x
class Critic(nn.Module):
def __init__(self):
super(Critic, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(64, 1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = self.pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
上述代码实现了基于自注意力机制的图像隐写模型的核心组件。AttentionModule类实现了注意力模块,通过卷积层生成注意力掩码;Encoder类实现了编码器,负责将数据嵌入到图像中并应用注意力掩码;Decoder类实现了解码器,负责从图像中提取数据并应用注意力掩码;Critic类实现了评价器,负责评估图像的真实性。
该模型的主要特点是引入了自注意力机制,使模型能够学习到应该关注的图像区域,将隐藏信息嵌入到受转换影响较小的纹理和对象中。通过这种方式,模型可以更好地抵抗各种噪声攻击,提高鲁棒性。注意力机制的引入是该模型的关键创新点,显著提升了模型在复杂噪声环境下的性能。
模型训练与测试
本部分展示了图像隐写模型的训练和测试代码,包括数据加载、模型初始化、损失函数定义、训练循环和测试流程等。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import torchvision.transforms as transforms
from PIL import Image
import os
import random
class ImageDataset(Dataset):
def __init__(self, root_dir, transform=None, data_length=8):
self.root_dir = root_dir
self.transform = transform
self.data_length = data_length
self.image_files = [f for f in os.listdir(root_dir) if f.endswith('.jpg') or f.endswith('.png')]
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir, self.image_files[idx])
image = Image.open(img_name).convert('RGB')
if self.transform:
image = self.transform(image)
# 生成随机数据
data = torch.randint(0, 2, (self.data_length,)).float()
return image, data
# 数据转换
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
])
# 数据加载
dataset = ImageDataset(root_dir='path/to/dataset', transform=transform)
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
# 模型初始化
data_length = 8
encoder = Encoder(data_length)
decoder = Decoder(data_length)
critic = Critic()
noise_layer = NoiseLayer()
# 优化器
optimizer_e = optim.Adam(list(encoder.parameters()) + list(decoder.parameters()), lr=0.001)
optimizer_c = optim.Adam(critic.parameters(), lr=0.0001)
# 损失函数
data_loss_fn = nn.BCELoss()
image_loss_fn = nn.MSELoss()
# 训练循环
epochs = 50
for epoch in range(epochs):
for i, (images, data) in enumerate(dataloader):
# 生成载密图像
stego_images = encoder(images, data)
# 添加噪声
noisy_stego_images = noise_layer(stego_images)
# 判别器训练
optimizer_c.zero_grad()
# 真实图像得分
real_scores = critic(images)
# 载密图像得分
fake_scores = critic(stego_images.detach())
# 判别器损失
critic_loss = -torch.mean(real_scores) + torch.mean(fake_scores)
critic_loss.backward()
optimizer_c.step()
# 梯度裁剪
for p in critic.parameters():
p.data.clamp_(-0.1, 0.1)
# 生成器和解码器训练
optimizer_e.zero_grad()
# 提取数据
extracted_data = decoder(noisy_stego_images)
# 数据重构损失
data_loss = data_loss_fn(extracted_data, data)
# 图像重构损失
image_loss = image_loss_fn(stego_images, images)
# 生成器损失
fake_scores = critic(stego_images)
generator_loss = -torch.mean(fake_scores)
# 总损失
total_loss = data_loss + 10 * image_loss + generator_loss
total_loss.backward()
optimizer_e.step()
# 打印损失
if i % 100 == 0:
print(f'Epoch [{epoch}/{epochs}], Step [{i}/{len(dataloader)}], '
f'Data Loss: {data_loss.item():.4f}, Image Loss: {image_loss.item():.4f}, '
f'Generator Loss: {generator_loss.item():.4f}, Critic Loss: {critic_loss.item():.4f}')
# 测试代码
def test_model(encoder, decoder, test_dataloader, noise_type=None):
encoder.eval()
decoder.eval()
correct = 0
total = 0
with torch.no_grad():
for images, data in test_dataloader:
# 生成载密图像
stego_images = encoder(images, data)
# 添加指定噪声
if noise_type == 'crop':
crop_size = int(images.size(2) * 0.8)
start_x = torch.randint(0, images.size(2) - crop_size, (1,))
start_y = torch.randint(0, images.size(3) - crop_size, (1,))
stego_images = stego_images[:, :, start_x:start_x+crop_size, start_y:start_y+crop_size]
stego_images = F.interpolate(stego_images, size=(images.size(2), images.size(3)))
elif noise_type == 'watermark':
watermark = torch.randn_like(stego_images) * 0.1
stego_images = stego_images + watermark
stego_images = torch.clamp(stego_images, 0, 1)
elif noise_type == 'compress':
stego_images = torch.round(stego_images * 255) / 255
# 提取数据
extracted_data = decoder(stego_images)
# 二值化
extracted_data = (extracted_data > 0.5).float()
# 计算准确率
correct += (extracted_data == data).all(dim=1).sum().item()
total += data.size(0)
accuracy = correct / total
print(f'Test Accuracy: {accuracy:.4f}')
return accuracy
上述代码实现了图像隐写模型的完整训练和测试流程。ImageDataset类用于加载和预处理图像数据;训练循环部分实现了生成器、解码器和判别器的交替训练,通过最小化数据重构损失、图像重构损失和生成器损失来优化模型;测试代码部分实现了模型的测试流程,支持添加各种噪声攻击并计算解码准确率。
该代码的主要特点是采用了模块化设计,将数据加载、模型定义、训练循环和测试流程分离,提高了代码的可读性和可维护性。训练过程中使用了Adam优化器和梯度裁剪等技术,确保模型的稳定训练。测试过程中支持多种噪声攻击,可以全面评估模型的鲁棒性。通过调整参数和超参数,可以适应不同的数据集和隐写任务需求。
重难点和创新点
图像隐写技术的研究面临着多个重难点问题,主要包括隐写容量与图像质量的平衡、鲁棒性与隐蔽性的平衡、以及复杂噪声环境下的信息提取等。本研究针对这些问题展开深入探讨,提出了两种具有创新性的图像隐写方法,取得了显著的研究成果。
本研究的第一个重难点是提高图像隐写方法的鲁棒性,使其能够抵抗常见的图像修改操作。传统的图像隐写方法在面对裁剪、旋转、压缩等操作时,往往会导致隐藏信息的丢失或损坏。为了解决这个问题,本研究提出了基于生成对抗网络的抗裁剪图像隐写方法,通过添加噪声层和密集连接机制,提高模型在面对裁剪攻击时的鲁棒性。噪声层在训练过程中随机添加各种噪声,使模型能够学习到在噪声环境下的信息隐藏和提取策略;密集连接机制则通过多层特征的融合,减少信息丢失,提高解码器的提取能力。
本研究的第二个重难点是提高图像隐写方法对多种噪声攻击的抵抗力。单一的抗裁剪隐写方法无法满足复杂噪声环境下的需求,需要设计能够抵抗多种噪声攻击的隐写方法。为了解决这个问题,本研究提出了基于自注意力机制的图像隐写方法,通过注意力掩码给隐藏信息赋予权重,使模型倾向于将数据隐藏在受转换影响较小的纹理和对象中。这种方法可以有效抵抗裁剪、水印、压缩、旋转、缩放等多种噪声攻击,显著提高了模型的鲁棒性和适应性。
本研究的主要创新点包括三个方面。首先,将生成对抗网络引入图像隐写技术,通过对抗训练提高隐写方法的隐蔽性和抗检测能力。生成对抗网络可以自动学习图像的统计特性,生成高质量的载密图像,不易被隐写分析工具检测。其次,引入自注意力机制,使模型能够学习到应该关注的图像区域,提高对复杂噪声攻击的抵抗力。注意力机制是本研究的关键创新点,显著提升了模型在各种噪声环境下的性能。最后,结合噪声层和密集连接机制,设计了抗裁剪图像隐写模型,解决了传统方法在面对裁剪攻击时鲁棒性不足的问题。
总结
本研究针对基于深度学习的图像隐写技术展开深入探讨,重点研究如何提高隐写方法的鲁棒性和抗隐写分析能力。通过对传统图像隐写方法和基于深度学习的图像隐写方法的研究现状进行分析,指出了现有方法存在的问题和不足,并提出了两种具有创新性的图像隐写方法。
首先,提出了基于生成对抗网络的抗裁剪图像隐写方法,通过添加噪声层和密集连接机制,提高模型在面对裁剪攻击时的鲁棒性。该方法采用端到端的网络结构,包含编码器、噪声层、解码器和评价器四个主要组成部分,通过对抗训练实现信息隐藏、图像质量和抗检测能力的平衡。实验结果表明,该方法在面对裁剪攻击时具有较高的解码准确率,同时保持了良好的图像质量和抗隐写分析能力。
其次,提出了基于自注意力机制的图像隐写方法,通过注意力掩码给隐藏信息赋予权重,增强模型对多种噪声攻击的抵抗力。该方法同样采用生成对抗网络的架构,但引入了自注意力机制,使模型能够学习到应该关注的图像区域,将隐藏信息嵌入到受转换影响较小的纹理和对象中。实验结果表明,该方法对裁剪、水印、压缩、旋转、缩放等多种噪声攻击具有较强的抵抗力,显著提高了模型的鲁棒性。
本研究的成果对于提高图像隐写技术的安全性和实用性具有重要的理论意义和应用价值。基于生成对抗网络的抗裁剪图像隐写方法和基于自注意力机制的图像隐写方法为解决现有隐写方法鲁棒性不足的问题提供了新的思路和方法。未来的研究可以进一步优化模型结构,提高隐写容量和鲁棒性,探索新的注意力机制和生成对抗网络架构,以及将隐写技术应用于更多的媒体类型和实际场景。
参考文献
[1] Rustad S, Andono P N, Shidik G F. Digital image steganography survey and investigation (goal, assessment, method, development, and dataset)[J]. Signal Processing, 2023, 206: 108908.
[2] Zhu Z, Zheng N, Qiao T, et al. Robust steganography by modifying sign of DCT coefficients[J]. IEEE Access, 2019, 7: 168613-168628.
[3] Mandal P C, Mukherjee I, Paul G, et al. Digital image steganography: A literature survey[J]. Information sciences, 2022, 609: 1451-1488.
[4] Kadhim I J, Premaratne P, Vial P J, et al. Comprehensive survey of image steganography: Techniques, Evaluations, and trends in future research[J]. Neurocomputing, 2019, 335: 299-326.
[5] Li L, Zhang W, Chen K, et al. Steganographic security analysis from side channel steganalysis and its complementary attacks[J]. IEEE Transactions on Multimedia, 2019, 22(10): 2526-2536.
[6] Chan C K, Cheng L M. Hiding data in images by simple LSB substitution[J]. Pattern recognition, 2004, 37(3): 469-474.
[7] Chaumont M. Deep learning in steganography and steganalysis[M]//Digital media steganography. Academic Press, 2020: 321-349.
[8] Volkhonskiy D, Nazarov I, Burnaev E. Steganographic generative adversarial networks[C]//Twelfth international conference on machine vision (ICMV 2019). SPIE, 2020, 11433: 991-1005.

















 1861
1861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









