




选题背景意义
当代社会已经全面进入信息化和网络化时代,互联网已经渗透到政治、经济、军事、文化、社会生活的各个领域,成为支撑现代社会正常运转不可或缺的基础设施。然而随着网络应用的广泛普及和网络技术的快速发展,网络安全威胁也呈现出愈演愈烈的趋势,各类网络攻击事件频发,给国家安全、社会稳定和人民财产安全带来了严重威胁。从近年来发生的一系列重大网络安全事件可以看出,网络攻击已经呈现出规模化、组织化、专业化的特征,攻击者的技术水平不断提高,攻击手段不断翻新,攻击目标从个人用户逐步扩展到政府机构、关键基础设施、大型企业等重要目标。
针对网络入侵检测中的类不平衡处理和高维特征提取两大核心技术问题展开深入研究,提出基于混合采样的类不平衡处理方法和基于粒子群优化长短期记忆单元自动编码器的特征提取方法,并在此基础上构建完整的网络入侵检测系统。从理论层面来看,本研究将聚类分析、生成对抗网络、深度学习、优化算法等多种先进技术有机结合,探索其在网络安全领域的创新应用,为网络入侵检测技术的理论研究提供新的思路和方法。从实践层面来看,本研究提出的技术方案能够有效提升入侵检测系统对各类攻击的检测能力,降低漏检率和误报率,为网络空间安全防护提供有力的技术支撑。
混合采样策略通过将欠采样和过采样两种方法相结合,既解决了单一欠采样方法可能丢失重要样本信息的问题,又避免了单一过采样方法可能引起的过拟合问题,实现了类不平衡处理的科学化和合理化。基于粒子群优化的长短期记忆单元自动编码器特征提取方法,通过引入智能优化算法对模型参数进行自动化搜索,克服了传统深度学习模型参数调优困难的问题,提升了特征提取的效率和效果。本研究的成果对于提升我国网络空间安全防护能力具有积极的推动作用,对于保障关键信息基础设施安全、维护国家网络安全具有重要意义。
数据集
数据采集
网络入侵检测模型的训练和评估离不开高质量的数据集支持,数据集的采集是整个研究工作的基础环节。数据采集阶段需要综合考虑数据的代表性、真实性、完整性和可用性等因素,选择合适的数据来源和采集方法。在实际研究中,常用的数据采集方式主要包括真实网络环境采集、公开数据集利用和仿真环境生成三种途径。每种采集方式各有优缺点,研究者需要根据具体研究目的和条件约束进行选择和组合。
真实网络环境采集是最能反映实际网络状况的数据获取方式。通过在真实网络链路中部署流量采集设备,可以获取到最接近实际应用场景的网络流量数据。常用的流量采集工具包括Tcpdump、Wireshark、NetFlow等,它们能够在不影响网络正常运行的前提下,捕获经过采集点的所有网络数据包,并将其保存为标准格式的文件供后续分析使用。真实网络流量数据具有最高的真实性和代表性,包含了各种真实存在的正常流量模式和攻击流量模式,但同时也存在数据量大、隐私保护要求高、采集成本高等问题。在进行真实网络数据采集时,需要严格遵守相关法律法规和伦理规范,对涉及个人隐私和敏感信息的数据进行脱敏处理。
| 流量类别 | 攻击类型 | 样本数量 | 占比 |
|---|---|---|---|
| 正常流量 | 无 | 45000 | 45% |
| 拒绝服务攻击 | DoS | 20000 | 20% |
| 扫描攻击 | Probe | 15000 | 15% |
| 未授权访问 | R2L | 10000 | 10% |
| 权限提升 | U2R | 5000 | 5% |
| 其他攻击 | Other | 5000 | 5% |
仿真环境生成是获取特定类型攻击数据的有效方法。由于真实网络环境中某些高级持续性威胁攻击很少见,或者出于安全考虑无法在实际生产环境中进行攻击测试,研究者通常采用仿真环境来生成特定类型的攻击流量。仿真环境可以是完全虚拟化的网络空间,也可以是基于真实设备的实验网络。通过在仿真环境中部署各种攻击工具和靶标系统,可以按照预设的实验方案生成包含特定攻击类型的网络流量数据。这种方法的优势在于可以精确控制攻击的类型、强度、频率等参数,生成满足特定研究需求的定制化数据集,但同时也存在仿真环境与真实环境之间存在差异的问题。
采集到的原始网络流量数据往往存在各种质量问题,直接使用这些原始数据进行模型训练会影响检测模型的性能和可靠性。数据清洗是数据预处理的重要环节,其目的是识别和处理数据中的各种异常情况,消除数据质量问题对后续分析的干扰。数据清洗的主要工作包括重复数据处理、缺失值处理、异常值处理和数据格式标准化等内容。网络流量数据可能来自不同的采集源和使用不同的存储格式,需要将其统一转换为标准格式以便后续处理。格式标准化的内容包括数据类型转换、特征编码、单位统一和格式转换等。数据类型转换主要是将字符串类型的数值转换为数值类型,将分类特征转换为数值编码。特征编码主要针对分类特征进行数值化处理,常用的编码方式包括标签编码、独热编码和目标编码。单位统一是将不同采集源可能使用不同单位表示的同一特征转换为统一单位。格式转换是将各种原始格式转换为模型可以直接使用的标准数据格式。
数据格式化
数据格式化是将清洗和标注后的数据转换为模型可以直接使用的格式的过程。不同类型的模型对输入数据的格式要求不同,因此需要根据后续模型的特点选择合适的格式化方案。网络流量数据的格式化主要包括数据编码、特征归一化和数据分割等内容。
数据分割是将数据集划分为训练集、验证集和测试集的过程。合理的数据分割策略对于模型评估至关重要,通常要求各子集在样本分布上保持一致性,同时各子集之间相互独立。常用的分割方法包括随机分割、分层分割和时间序列分割。随机分割按照一定比例随机划分数据集,简单易实现但可能破坏样本分布。分层分割保证各子集中不同类别样本的比例与原始数据集一致,适用于分类问题的评估。时间序列分割按照时间顺序划分数据集,适用于具有时序特性的网络流量数据,能够更好地模拟实际应用场景中的模型使用方式。
| 数据集 | 样本数量 | 占比 | 用途 |
|---|---|---|---|
| 训练集 | 60000 | 60% | 模型训练 |
| 验证集 | 20000 | 20% | 超参数调优 |
| 测试集 | 20000 | 20% | 最终性能评估 |
功能模块
本系统是一个完整的网络入侵检测系统,包含数据预处理模块、类不平衡处理模块、特征提取模块、模型训练模块和入侵检测模块五个核心功能模块。数据预处理模块负责对原始网络流量数据进行清洗、格式转换和归一化处理,为后续模块提供高质量的输入数据。类不平衡处理模块采用混合采样策略,通过DBSCAN聚类欠采样和WGAN过采样相结合的方式,处理网络流量数据中的类不平衡问题。特征提取模块使用PSO优化的LSTM自动编码器,从处理后的数据中提取有效的特征表示。模型训练模块基于全连接神经网络,使用提取的特征训练入侵检测分类模型。入侵检测模块将训练好的模型部署到实际网络环境中,对实时网络流量进行检测和告警。
类不平衡处理模块
类不平衡处理模块针对网络流量数据中的类不平衡问题,采用混合采样策略进行处理。该模块的设计充分考虑了网络流量数据的特点和类不平衡处理的实际需求,将欠采样和过采样两种策略有机结合,在保留多数类核心信息的同时增强少数类的样本数量,从而构建更加平衡的训练数据集。模块的主要技术特点包括聚类分析驱动的欠采样、自适应计算的过采样和采样结果的质量评估三个方面的创新。
基于DBSCAN的欠采样子模块是类不平衡处理模块的重要组成部分。该子模块采用密度聚类方法对多数类样本进行聚类分析,通过识别样本空间的密集区域和稀疏区域,保留核心样本的同时去除边界异常点和噪声样本。相比随机欠采样方法,基于DBSCAN的欠采样能够更好地保持样本空间的几何结构和分布特征,避免重要样本信息的丢失。该子模块的关键技术参数包括邻域半径和最小样本数两个参数,它们共同决定了聚类的粒度和结果。邻域半径决定了判断两个样本是否属于同一邻域的距离阈值,最小样本数决定了核心点的最小邻域样本数量要求。
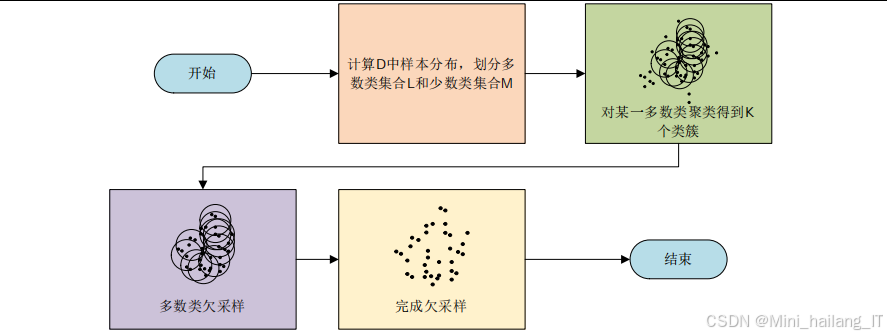
自适应WGAN过采样子模块是类平衡处理模块的另一核心组件。该子模块使用Wasserstein生成对抗网络生成少数类样本,以弥补欠采样后少数类样本数量的不足。传统的固定比例过采样方法难以确定最优的采样比例,可能导致过采样不足或过采样过度的问题。本模块提出自适应过采样数量计算方法,综合考虑数据集的原始类分布、欠采样后各类别的样本数量以及目标平衡比例,科学合理地确定各类别需要生成的样本数量。WGAN网络采用特定的网络结构设计,生成器和判别器均为多层全连接网络,通过对抗训练学习少数类样本的数据分布特征。
采样结果评估子模块负责对采样处理的效果进行量化评估。该子模块实现了多种评估指标,包括采样前后类别分布变化、样本空间分布变化和最近邻样本分析等。类别分布变化指标直观展示采样前后各类别样本数量的变化情况。样本空间分布变化指标通过计算采样前后样本分布的统计特性(如均值、方差、协方差矩阵等)变化,评估采样处理对数据分布的影响。最近邻样本分析通过观察少数类样本与其最近邻样本的关系,评估生成样本的质量和真实性。
特征提取模块
特征提取模块负责从采样处理后的网络流量数据中提取有效的特征表示,是连接数据处理和模型训练的关键环节。该模块采用基于粒子群优化的LSTM自动编码器作为核心特征提取方法,利用LSTM网络的时序建模能力和自动编码器的特征抽象能力,实现对网络流量数据的高效特征提取。粒子群优化算法的引入解决了传统自动编码器参数调优困难的问题,实现了参数设置的自动化和最优化。
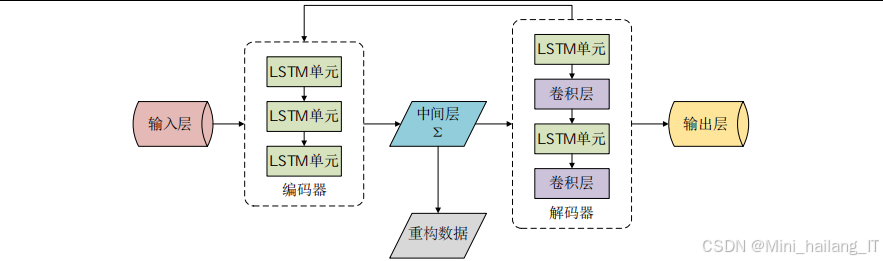
LSTM自动编码器子模块是特征提取模块的核心组件。自动编码器是一种无监督学习模型,通过训练使得输出尽可能复现输入,从而学习到输入数据的压缩表示。本模块采用的LSTM自动编码器使用长短期记忆单元作为基本构建块,相比传统全连接自动编码器,能够更好地捕捉网络流量数据中的时序依赖关系。LSTM单元的内部结构包含输入门、遗忘门和输出门三个控制门,通过精心设计的门控机制实现对历史信息的选择性记忆和遗忘,有效解决了传统循环神经网络中的梯度消失问题。自动编码器的编码器部分将高维输入映射到低维潜在空间,解码器部分则从低维表示重建原始输入,编码器的输出即为提取的特征表示。
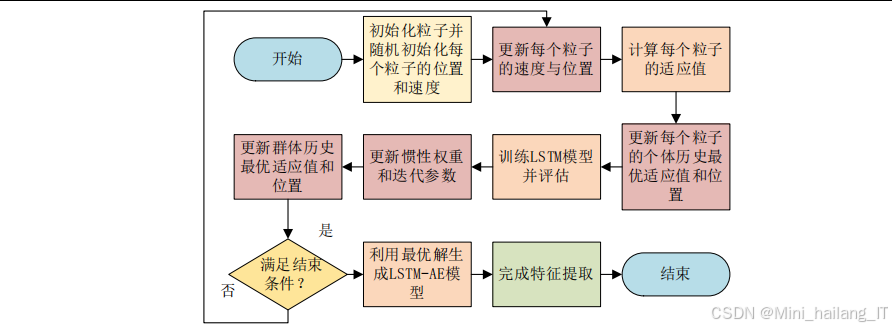
粒子群优化子模块负责对LSTM自动编码器的参数进行优化。粒子群优化算法是一种基于群体智能的优化算法,通过模拟鸟群觅食行为实现对最优解的搜索。该子模块将LSTM自动编码器的网络结构参数(如隐藏层节点数、学习率、训练轮数等)编码为粒子的位置向量,通过迭代更新粒子的位置和速度来搜索最优参数组合。粒子的适应度函数使用特征提取后数据的重构误差或下游分类任务的性能指标,以引导搜索过程朝向最优参数方向进行。PSO算法的全局搜索能力和LSTM自动编码器的特征学习能力相结合,实现了特征提取过程的自动化和最优化。
特征质量评估子模块负责对提取的特征质量进行评估。特征质量直接影响后续分类模型的性能,因此需要建立科学的评估机制。该子模块实现了多种评估方法,包括特征可分离性分析、重构误差分析和分类性能分析等。特征可分离性分析通过计算不同类别样本在特征空间中的类间距离和类内距离,评估特征的区分能力。重构误差分析通过计算自动编码器对输入数据的重建误差,评估特征表示对原始信息的保留程度。分类性能分析将提取的特征输入到简单的分类器中,根据分类准确率间接评估特征质量。
入侵检测模块
入侵检测模块负责将训练好的检测模型部署到实际网络环境中,对实时网络流量进行检测和告警。该模块是整个系统面向实际应用的接口,需要具备实时处理能力、准确检测能力和友好交互能力。模块的设计采用流水线架构,将网络流量获取、预处理、特征提取和入侵检测串联成一个高效的处理流程。

实时流量处理子模块负责从网络接口获取实时流量数据并进行预处理。该子模块集成了网络流量捕获库,能够从指定网络接口实时捕获经过的数据包。捕获到的数据包按照预定义的特征提取规则转换为结构化的特征向量,然后依次经过数据预处理、类平衡处理和特征提取流程,最终得到标准化的特征表示。为满足实时处理的需求,该子模块采用了多线程和流水线技术,将数据捕获、特征计算和模型推理分配到不同线程并行执行,最大化系统吞吐量。
检测结果处理子模块负责对模型的检测结果进行处理和输出。模型输出的是各类别的概率分布或分类标签,需要根据应用场景设置合适的判断阈值。对于概率输出,可以采用固定阈值或自适应阈值策略;对于多分类问题,需要根据具体需求选择一对一或一对多的决策策略。检测结果包括流量标识、检测时间、预测类别和置信度等信息,这些信息被格式化为标准日志格式保存到文件或数据库中,同时通过消息队列或网络接口推送到安全运营中心进行集中展示和响应。
算法理论
本系统涉及的算法理论主要包括DBSCAN密度聚类算法、Wasserstein生成对抗网络、LSTM长短期记忆网络和粒子群优化算法四种核心算法。DBSCAN算法用于对多数类样本进行聚类分析,为欠采样处理提供科学依据。WGAN算法用于学习少数类样本的分布特征并生成合成样本,解决过采样问题。LSTM网络用于构建自动编码器,实现对网络流量数据的特征提取。PSO算法用于优化LSTM自动编码器的参数,提升特征提取效果。这些算法各有特点,相互配合,共同构成了系统的技术基础。
DBSCAN密度聚类算法
DBSCAN算法是一种经典的基于密度的空间聚类算法,由Martin Ester、Hans-Peter Kriegel、Jörg Sander和Xiaowei Xu于1996年提出。该算法的主要思想是将密度相连的样本点划分为同一簇,密度较低区域中的样本点被视为噪声。这种基于密度的聚类方式能够发现任意形状的簇,不需要预先指定簇的数量,对噪声数据具有较强的鲁棒性,非常适合用于网络流量数据的聚类分析。
DBSCAN算法的核心概念包括邻域、核心点、边界点和噪声点等。给定邻域半径ε和最小样本数MinPts,任意一个样本点的ε邻域是指以该点为中心、ε为半径的多维球形区域内的所有样本点集合。核心点是指其ε邻域内包含至少MinPts个样本点的点,这些点是密集区域的核心。边界点是指非核心点但落在某个核心点ε邻域内的点,它们属于某个簇但不是簇的核心。噪声点是指既非核心点也非边界点的样本点,这些点被视为离群点或噪声。
Nϵ(p)={q∈D∣dist(p,q)≤ϵ} N_{\epsilon}(p) = \{q \in D | dist(p, q) \leq \epsilon\} Nϵ(p)={q∈D∣dist(p,q)≤ϵ}
其中,Nϵ(p)N_{\epsilon}(p)Nϵ(p)表示样本点ppp的ε邻域,DDD表示数据集,dist(p,q)dist(p, q)dist(p,q)表示样本点ppp和qqq之间的距离。核心点的判定条件为:
∣Nϵ(p)∣≥MinPts |N_{\epsilon}(p)| \geq MinPts ∣Nϵ(p)∣≥MinPts
其中,∣Nϵ(p)∣|N_{\epsilon}(p)|∣Nϵ(p)∣表示ppp的ε邻域中包含的样本点数量。
DBSCAN算法的执行过程可以概括为以下步骤:首先随机选择一个未访问的样本点,检查其是否为核心点。如果不是核心点,则将其标记为噪声或分配给某个已有簇。如果是核心点,则创建一个新簇,将该核心点及其密度可达的所有样本点加入该簇。密度可达是指存在一条样本点序列,其中每个点都是前一个点的核心点且在ε邻域内。重复上述过程直到所有样本点都被访问,最终得到若干个簇和噪声点集合。
DBSCAN算法的优点包括能够发现任意形状的簇、不需要预先指定簇的数量、对噪声数据具有鲁棒性、聚类结果不受样本输入顺序影响等。这些优点使其非常适合用于网络流量数据的聚类分析,因为网络流量数据中的正常流量和各类攻击流量可能呈现出复杂的分布形态,簇的数量和形状事先难以预知。在欠采样应用中,DBSCAN算法通过识别密集区域(核心样本)和稀疏区域(边界和噪声),能够在保留多数类核心信息的同时去除冗余和异常样本,实现科学合理的欠采样处理。
DBSCAN算法在应用时需要合理选择两个关键参数:邻域半径ε和最小样本数MinPts。ε的选择决定了样本点的邻域范围,过小会导致每个点都成为噪声点,过大则会导致所有点都被聚合成一个簇。MinPts的选择决定了核心点的判定阈值,通常根据数据集特点和领域知识进行设置。在网络入侵检测应用中,可以先通过领域知识设定MinPts的初始值(如取特征维数的2到4倍),然后通过K距离图等方法确定ε的合理取值。
Wasserstein生成对抗网络
Wasserstein生成对抗网络是Martin Arjovsky等人于2017年提出的一种改进的生成对抗网络架构,旨在解决传统GAN训练中常见的模式崩塌和梯度消失问题。WGAN的核心创新是引入Wasserstein距离(也称为Earth Mover距离)作为生成器和判别器之间的优化目标,相比传统GAN使用的JS散度,Wasserstein距离具有更好的数学性质,能够提供更有意义的梯度信息指导生成器的学习。

传统GAN的训练稳定性问题源于其使用的JS散度存在局限性。当生成数据分布与真实数据分布不重叠或重叠较少时,JS散度会退化为常数,导致判别器的梯度消失或不稳定。而Wasserstein距离是一种连续且可微的距离度量,即使在两个分布不重叠的情况下也能提供有意义的梯度信息。Wasserstein距离的直观理解是将一个分布"搬运"成另一个分布所需的最小"工作量",它衡量的是分布之间的最优传输成本。
W(Pr,Pg)=infγ∈Π(Pr,Pg)E(x,y)∼γ[∥x−y∥] W(P_r, P_g) = \inf_{\gamma \in \Pi(P_r, P_g)} \mathbb{E}_{(x,y) \sim \gamma} [\|x - y\|] W(Pr,Pg)=γ∈Π(Pr,Pg)infE(x,y)∼γ[∥x−y∥]
其中,PrP_rPr表示真实数据分布,PgP_gPg表示生成数据分布,Π(Pr,Pg)\Pi(P_r, P_g)Π(Pr,Pg)表示所有以PrP_rPr和PgP_gPg为边际分布的联合分布的集合,γ\gammaγ表示一个特定的联合分布,E(x,y)∼γ[∥x−y∥]\mathbb{E}_{(x,y) \sim \gamma}[\|x-y\|]E(x,y)∼γ[∥x−y∥]表示从联合分布γ\gammaγ中采样得到的样本对之间的期望距离。WGAN通过 Kantorovich-Rubinstein 对偶定理将上述Wasserstein距离转化为以下优化问题:
maxf∈Lip1Ex∼Pr[f(x)]−Ez∼Pz[f(G(z))] \max_{f \in Lip_1} \mathbb{E}_{x \sim P_r}[f(x)] - \mathbb{E}_{z \sim P_z}[f(G(z))] f∈Lip1maxEx∼Pr[f(x)]−Ez∼Pz[f(G(z))]
其中,fff是一个满足1-Lipschitz约束的函数(即评论家网络),PzP_zPz表示噪声分布,GGG表示生成器网络。
WGAN算法的实现采用 Kantorovich-Rubinstein 对偶形式,将Wasserstein距离转化为判别器的最大化问题。判别器在WGAN中被称为评论家,其输出不再是0到1之间的概率值,而是实数域上的评分函数。评论家需要满足1-Lipschitz连续性约束,这在实现上通过权重裁剪或梯度惩罚等方法来实现。权重裁剪方法简单地将评论家网络的权重限制在一个固定范围内,但可能导致网络表达能力受限。梯度惩罚方法则通过在损失函数中添加梯度惩罚项来间接实现Lipschitz约束,效果更好但计算开销较大。

WGAN的训练过程包括交替训练评论家和生成器。评论家的目标是最大化真实样本和生成样本之间的Wasserstein距离,即给真实样本打高分、给生成样本打低分。生成器的目标是最小化真实样本和生成样本之间的Wasserstein距离,即生成让评论家给出高分的样本。通过对抗训练,生成器逐渐学习到真实数据分布的特征,能够生成越来越逼真的样本。在网络入侵检测的过采样应用中,WGAN学习少数类攻击样本的数据分布特征,并据此生成新的攻击样本,有效增强少数类的样本数量。
WGAN的网络结构设计需要考虑生成器和评论家的具体需求。生成器通常采用转置卷积或全连接层构建,将随机噪声向量逐步上采样为目标数据维度的输出。评论家则采用全连接层或卷积层构建,将输入数据映射为一个标量评分。网络层数、节点数、激活函数等超参数需要根据具体任务和数据特点进行调整。训练过程中需要监控Wasserstein距离的变化趋势,正常情况下真实样本与生成样本之间的Wasserstein距离应逐渐收敛。
LSTM长短期记忆网络
LSTM是一种特殊的循环神经网络架构,由Sepp Hochreiter和Jürgen Schmidhuber于1997年提出,旨在解决传统循环神经网络在处理长序列数据时面临的梯度消失和梯度爆炸问题。LSTM通过在网络结构中引入精心设计的门控机制,实现了对历史信息的选择性记忆和遗忘,能够有效捕捉序列数据中的长程依赖关系。这一特性使LSTM非常适合处理网络流量这类具有时序关联性的数据。

LSTM单元的内部结构包含三个控制门和一个记忆细胞,三个控制门分别是输入门、遗忘门和输出门。输入门决定当前时刻的输入信息有多少比例应该被写入记忆细胞,其计算涉及对输入和上一时刻隐层状态的线性变换以及Sigmoid激活。遗忘门决定上一时刻记忆细胞中的信息有多少比例应该被保留,通过对上一时刻隐层状态和当前输入的线性组合应用Sigmoid激活来实现。输出门决定当前时刻记忆细胞中的信息有多少比例应该输出到隐层状态,同样通过Sigmoid激活的线性变换实现。记忆细胞是LSTM单元的核心组件,负责长期保存历史信息,通过三个门的协调控制实现信息的写入、保持和读取。
LSTM的数学表达可以通过以下方程组形式化描述:
ft=σ(Wf⋅[ht−1,xt]+bf)it=σ(Wi⋅[ht−1,xt]+bi)C~t=tanh(WC⋅[ht−1,xt]+bC)Ct=ft⊙Ct−1+it⊙C~tot=σ(Wo⋅[ht−1,xt]+bo)ht=ot⊙tanh(Ct) \begin{aligned} f_t &= \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) \\ i_t &= \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) \\ \tilde{C}_t &= \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) \\ C_t &= f_t \odot C_{t-1} + i_t \odot \tilde{C}_t \\ o_t &= \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) \\ h_t &= o_t \odot \tanh(C_t) \end{aligned} ftitC~tCtotht=σ(Wf⋅[ht−1,xt]+bf)=σ(Wi⋅[ht−1,xt]+bi)=tanh(WC⋅[ht−1,xt]+bC)=ft⊙Ct−1+it⊙C~t=σ(Wo⋅[ht−1,xt]+bo)=ot⊙tanh(Ct)
其中,ftf_tft表示遗忘门的输出,iti_tit表示输入门的输出,C~t\tilde{C}_tC~t表示候选记忆细胞,CtC_tCt表示当前时刻的记忆细胞状态,oto_tot表示输出门的输出,hth_tht表示当前时刻的隐层状态。Wf,Wi,WC,WoW_f, W_i, W_C, W_oWf,Wi,WC,Wo分别表示四个门的权重矩阵,bf,bi,bC,bob_f, b_i, b_C, b_obf,bi,bC,bo分别表示四个门的偏置向量。σ\sigmaσ表示Sigmoid激活函数,⊙\odot⊙表示逐元素乘法运算,[ht−1,xt][h_{t-1}, x_t][ht−1,xt]表示隐层状态和输入的拼接操作。
LSTM的数学表达可以形式化描述为:给定当前时刻的输入x_t和上一时刻的隐层状态h_{t-1},首先通过遗忘门决定需要遗忘的历史信息,然后通过输入门决定需要写入的新信息,更新记忆细胞的状态,接着通过输出门决定需要输出的信息,最终得到当前时刻的隐层状态h_t和输出y_t。整个过程可以通过一系列矩阵运算和逐元素非线性变换高效实现。LSTM的参数量主要来自四个全连接层(对应三个门的计算和候选记忆的计算),参数量与输入维度、隐层维度和偏置项有关。
LSTM在自动编码器中的应用将LSTM的序列建模能力与自动编码器的特征抽象能力相结合。LSTM自动编码器的编码器将输入序列逐步压缩为固定维度的向量表示,解码器则从这个向量表示重建原始序列。在网络入侵检测应用中,可以将网络流量数据组织为时间窗口内的序列形式,利用LSTM自动编码器学习流量的时序特征表示。相比全连接自动编码器,LSTM自动编码器能够更好地捕捉流量特征在时间维度上的依赖关系和演化模式,提取到更具判别性的特征表示。
LSTM网络训练通常采用基于时间反向传播算法,通过最小化重构误差或预测误差来更新网络参数。由于LSTM结构较为复杂,参数数量较多,训练过程中需要注意学习率设置、梯度裁剪、过拟合预防等问题。学习率可以采用固定值或自适应调度策略,如学习率衰减或余弦退火。梯度裁剪用于防止训练过程中梯度爆炸,保证训练的稳定性。早停、正则化和Dropout等技术用于防止过拟合,提高模型的泛化能力。
粒子群优化算法
粒子群优化算法是一种基于群体智能的元启发式优化算法,由James Kennedy和Russell Eberhart于1995年提出,其灵感来源于鸟群觅食行为。在PSO中,优化问题的每一个潜在解被表示为搜索空间中的一个"粒子",粒子根据自身经验和群体经验动态调整飞行速度和位置,逐步向最优解区域聚集。PSO算法具有原理简单、参数少、易于实现等优点,在函数优化、神经网络训练、特征选择等领域得到了广泛应用。
PSO算法的基本原理可以描述如下:设在一个D维搜索空间中有m个粒子组成的粒子群,每个粒子i在时刻t的位置向量为X_i(t) = (x_{i1}(t), x_{i2}(t), …, x_{iD}(t)),对应的速度向量为V_i(t) = (v_{i1}(t), v_{i2}(t), …, v_{iD}(t))。每个粒子都有一个根据目标函数计算的适应度值,适应度值反映了当前位置解的优劣程度。每个粒子记住自己曾经到达过的最优位置P_i(t) = (p_{i1}(t), p_{i2}(t), …, p_{iD}(t)),整个粒子群记住当前全局最优位置G(t) = (g_1(t), g_2(t), …, g_D(t))。粒子根据以下公式更新自己的速度和位置:
vij(t+1)=w⋅vij(t)+c1⋅r1⋅(pij(t)−xij(t))+c2⋅r2⋅(gj(t)−xij(t)) v_{ij}(t+1) = w \cdot v_{ij}(t) + c_1 \cdot r_1 \cdot (p_{ij}(t) - x_{ij}(t)) + c_2 \cdot r_2 \cdot (g_j(t) - x_{ij}(t)) vij(t+1)=w⋅vij(t)+c1⋅r1⋅(pij(t)−xij(t))+c2⋅r2⋅(gj(t)−xij(t))
xij(t+1)=xij(t)+vij(t+1) x_{ij}(t+1) = x_{ij}(t) + v_{ij}(t+1) xij(t+1)=xij(t)+vij(t+1)
其中w是惯性权重,控制粒子对当前速度的继承程度;c_1和c_2是学习因子,分别控制粒子向自身最优位置和全局最优位置移动的倾向;r_1和r_2是[0,1]区间内的随机数,增加搜索的随机性。
PSO算法在LSTM自动编码器参数优化中的应用将PSO的全局搜索能力与深度学习的特征学习能力相结合。在该应用中,LSTM自动编码器的网络结构参数(如隐藏层节点数、学习率、训练轮数等)被编码为粒子的位置向量,特征提取效果(如重构误差或分类准确率)作为适应度函数。通过PSO的迭代搜索,可以自动找到使特征提取效果最优的参数组合,避免了传统人工调参的繁琐过程。
PSO算法在应用中需要合理设置多个参数,包括粒子数量、迭代次数、惯性权重、学习因子等。粒子数量通常取20到50之间,迭代次数根据问题复杂度和计算资源确定。惯性权重w控制全局搜索和局部搜索的平衡,较大的w有利于全局搜索,较小的w有利于局部收敛,常用的线性递减策略是从0.9逐渐减小到0.4。学习因子c_1和c_2通常取2左右,c_1较大时粒子更倾向于向自身最优搜索,c_2较大时粒子更倾向于向全局最优搜索。为提高算法性能,还可以引入自适应参数调整、多种群协同、局部变异等改进策略。
重难点和创新点
重点难点
本研究的核心重点在于解决网络入侵检测中的类不平衡处理和高维特征提取两大技术难题。类不平衡问题的重点在于设计科学合理的采样策略,既能有效平衡类别分布,又能保留样本的关键信息,避免重要样本的丢失和噪声样本的引入。高维特征提取的重点在于构建有效的特征学习模型,自动从复杂的网络流量数据中提取具有判别性的特征表示,降低维度的同时保持信息的完整性。这两个问题的有效解决是提升入侵检测系统性能的关键所在。
类不平衡处理的技术难点主要体现在三个方面。首先是采样比例的确定问题,欠采样删除多少样本、过采样生成多少样本需要科学的定量计算,而不是简单凭经验设定。其次是采样过程的信息保真问题,无论是欠采样还是过采样都可能造成原始数据信息的损失或扭曲,需要采取措施尽可能保留数据的本质特征。再次是采样结果的质量评估问题,采样后的数据是否适合模型训练需要有效的评估指标和方法。这些难点的解决需要深入理解数据分布特性和采样方法的数学原理。
特征提取的技术难点主要体现在参数优化和网络设计两个方面。LSTM自动编码器的性能高度依赖于网络结构参数(如隐藏层节点数、层数)和学习参数(如学习率、训练轮数)的设置,这些参数的传统确定方式依赖大量实验调优,耗时耗力且难以保证最优。网络结构的设计需要平衡表达能力和计算效率,过深的网络可能导致过拟合和梯度问题,过浅的网络可能无法充分学习数据的复杂模式。如何实现参数设置的自动化和结构设计的最优化是特征提取面临的主要挑战。
系统集成与评估也是本研究需要重点关注的技术难点。网络入侵检测系统包含多个功能模块,各模块之间的数据流转和接口匹配需要精心设计。系统的实时性要求与处理复杂度的平衡需要在系统架构层面进行优化。评估指标的选择和测试方案的制定需要充分考虑类不平衡场景的特殊性,建立科学全面的评估体系。这些系统层面的问题解决对于研究成果的实用化具有重要意义。
创新点
本研究的创新点主要体现在方法设计和技术应用两个方面。在方法设计层面,提出了混合采样策略、自适应过采样机制和PSO-LSTM特征提取方法。在技术应用层面,将多种先进技术创造性地应用于网络入侵检测领域,解决了传统方法存在的突出问题。
混合采样策略的创新在于将欠采样和过采样两种策略有机结合,发挥各自优势互补。传统方法要么只做欠采样,要么只做过采样,难以同时解决信息保留和样本增强两个问题。本研究采用基于DBSCAN的智能欠采样,在保留多数类核心样本的同时去除冗余和噪声样本;然后采用基于WGAN的自适应过采样,在保持少数类分布特征的前提下合成新样本。两种策略的组合使用使类平衡处理更加科学合理。
自适应过采样机制的创新在于建立了科学的过采样数量计算方法。传统过采样方法往往采用固定比例,难以适应不同数据集的特点。本研究提出的自适应机制综合考虑原始类别分布、目标平衡比例和样本统计特性,自动计算各类别需要生成的样本数量。这种自适应方法能够避免过采样不足或过度的问题,使采样结果更加合理。
PSO-LSTM特征提取方法的创新在于将粒子群优化算法应用于LSTM自动编码器的参数优化,实现了特征提取过程的自动化和最优化。传统方法依赖人工调参,效率低下且难以保证最优。本研究将自动编码器的关键参数编码为PSO粒子的位置向量,通过迭代搜索找到使特征提取效果最优的参数组合。这种方法大大降低了特征提取对人工经验的依赖,提高了特征提取的效率和效果。
相关文献
[1] Ester M, Kriegel H P, Sander J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]. Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining. 1996: 226-231.
[2] Arjovsky M, Chintala S, Bottou L. Wasserstein GAN[J]. arXiv preprint arXiv:1701.07875, 2017.
[3] Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780.
[4] Kennedy J, Eberhart R. Particle swarm optimization[C]. Proceedings of the IEEE International Conference on Neural Networks. 1995: 1942-1948.
[5] LeCun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[6] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]. Advances in Neural Information Processing Systems. 2014: 2672-2680.
[7] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors[J]. Nature, 1986, 323(6088): 533-536.
[8] Breunig M M, Kriegel H P, Ng R T, et al. LOF: identifying density-based local outliers[J]. ACM SIGMOD Record, 2000, 29(2): 93-104.

















 2888
2888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









