




 本文介绍了基于大数据的高校招生数据挖掘可视化系统的设计,涵盖了项目背景、设计思路、决策树算法的应用,以及数据集的收集和预处理。通过ECharts进行数据可视化,并展示了系统实验的配置和决策树模型的构建过程。
本文介绍了基于大数据的高校招生数据挖掘可视化系统的设计,涵盖了项目背景、设计思路、决策树算法的应用,以及数据集的收集和预处理。通过ECharts进行数据可视化,并展示了系统实验的配置和决策树模型的构建过程。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长大数据毕设专题,本次分享的课题是
🎯基于大数据的高校招生数据挖掘可视化系统
项目背景
随着高等教育的普及和信息化技术的发展,高校招生数据呈现出快速增长的趋势。这些数据中包含了大量有关学生报考、录取、专业选择等方面的信息,对于高校招生政策制定、专业优化、招生宣传等都具有重要价值。因此,建立一个基于大数据的高校招生数据挖掘可视化系统,旨在通过数据挖掘和分析技术,为高校招生工作提供决策支持。这一课题不仅有助于提升高校招生工作的效率和公正性,还可为其他领域的数据挖掘和可视化提供借鉴。
设计思路
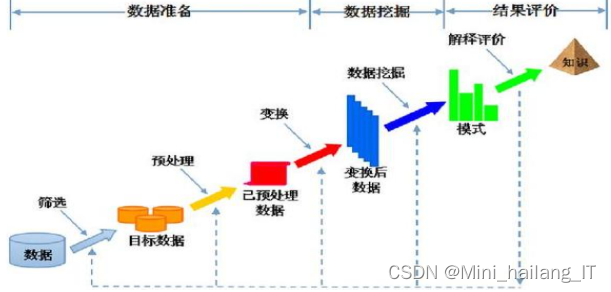
数据挖掘的过程因不同专业领域而异,每种技术都有独特特征和实现步骤。数据挖掘过程受到需求的影响,如数据完整性和专业支持度等,也导致了不同地区和行业的差异。在实施数据挖掘之前,必须确定步骤、任务和目标,并制定周详的计划。许多软件和公司提供数据挖掘过程模型,以指导用户逐步进行数据挖掘。
数据挖掘的基本步骤包括问题定义、数据收集和预处理、特征选择和转换、模型建立和评估以及结果解释和应用。首先,明确定义挖掘的问题和目标。然后,收集相关数据并进行预处理,包括数据清洗、缺失值处理和异常值检测。接下来,选择和转换特征,以提取对问题有意义的信息。然后,建立适当的数据挖掘模型,并使用训练数据进行模型训练和评估。最后,解释和解读挖掘结果,并将其应用于实际问题解决或决策支持。这些步骤相互关联,需要综合运用各种技术和方法,以实现有效的数据挖掘过程。
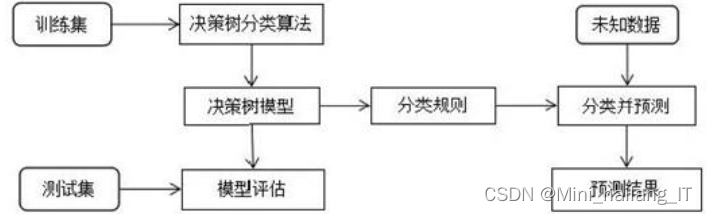
决策树是一种自顶向下递归的划分算法,采用自上而下、分而治之的贪心方法。它从根结点开始,根据样本集中的属性进行测试,将样本集分为多个子样本集,每个子样本集构成一个新的叶结点,然后重复此过程,直到达到终止条件。决策树的关键是样本集的划分和测试属性的选择。决策树的学习算法不需要用户掌握大量基础知识,是一种较为简单易懂的学习方法。
决策树的构建过程分为建树和剪枝两步。建树阶段通过广度优先递归算法选择部分训练数据,构建决策树,直到每个叶子结点同属一类。剪枝阶段利用剩余数据对生成的决策树进行检验和纠错,修剪和添加结点,直到得到一个正确的决策树。建树是递归过程,最终得到一棵决策树,而剪枝可以降低噪声数据对分类准确率的影响。
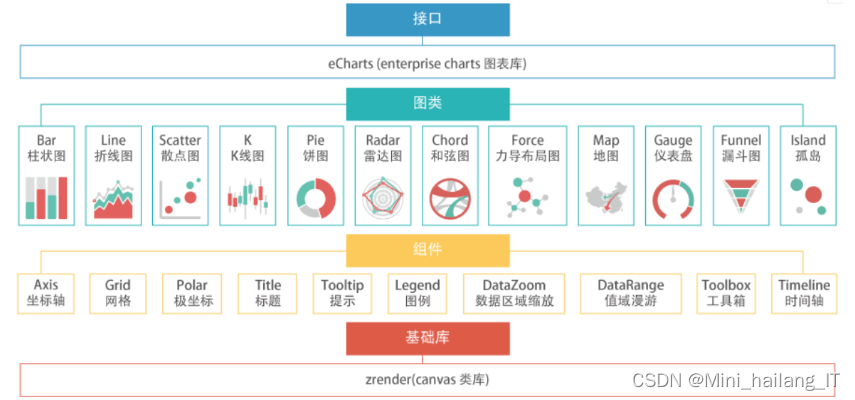
ECharts是一款开源的、跨平台的基于Web的可视化框架,它提供了丰富的内置交互和高性能的图形渲染器,使用户能够快速创建交互式可视化。ECharts采用声明式的可视设计语言,用户可以定制内置的图表类型。其底层采用流式架构和高性能的图形渲染器,大大提高了扩展性和性能。
ECharts的层次结构包括具体的可视化视图、组件、视图交互和外部可调用接口。可视化视图指具体的图表类型,如折线图和散点图;组件是辅助视图绘制和呈现数据信息的工具,例如坐标系和提示框;视图交互是指每个视图上的特定交互,如柱状图的上钻和下钻。外部可调用接口用于外部程序控制ECharts的渲染绘制和交互等操作。ECharts内部的视图和组件相互独立,可以任意组合,便于扩展和维护。
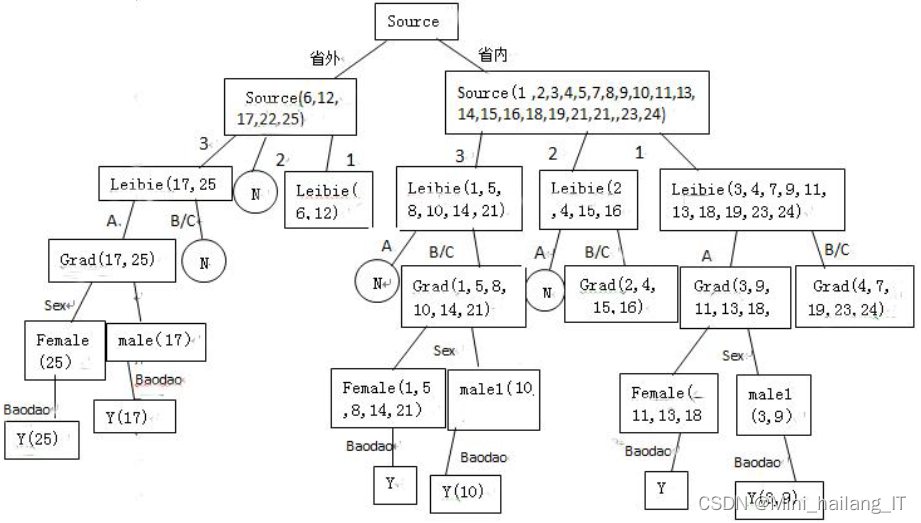
改进后的决策树在处理成绩属性时进行了一些变化。属性B和C被合并,只要高于属性C的成绩,它们就属于同一个等级C。这种合并可以简化决策树的结构,减少分支,提高模型的效率。此外,在决策树的构建过程中,离根节点较远的属性通过引入平衡度系数进行了缩短处理。这意味着在决策树的划分过程中,更加重视生源地属性,认为其对分类结果的影响更为重要。通过这种方式,改进后的决策树能够更准确和合理地进行分类,提高了模型的分类性能。
数据集
由于网络上缺乏针对高校招生领域的合适数据集,我决定自行收集和整理相关数据。首先,从多个高校招生网站和教育部门获取历年招生数据,包括学生报考信息、录取结果、专业分布等。然后,对数据进行清洗和预处理,去除重复、错误和无效数据,确保数据的质量和准确性。接着,根据系统需求和数据特点,对数据进行分类和标签化处理,以便后续的数据挖掘和可视化展示。最后,通过数据分析和挖掘算法的应用,提取出有价值的信息和规律,为高校招生工作提供决策支持。
系统实验
配置实验环境包括以下步骤:首先,确定实验所需的硬件设备,如计算机或服务器,并确保其满足实验要求,如足够的处理能力和存储空间。其次,安装操作系统,选择适合实验需求的操作系统版本,并进行基本的系统设置和更新。然后,安装所需的开发环境和工具,如编程语言、集成开发环境(IDE)、数据库管理系统等。根据实验需求,安装相应的数据分析和机器学习库,如NumPy、Pandas、SciKit-Learn等。此外,根据实验需要安装其他辅助工具和库,如可视化工具、图形库等。最后,验证环境配置是否成功,通过运行简单的示例代码或测试样例数据,确保环境能够正常运行和满足实验需求。

系统利用数据仓库和OLAP技术对招生原始数据进行采集、分类、关联等处理,并通过多维度共享式信息分析的特性,将招生信息按维度划分并展示给用户。用户可以通过钻取、切片、切块、旋转等操作,对维度视图进行交互式分析,并清晰直观地了解各系报到率情况。系统还支持历年数据的切换和导入,以实现对历史数据的报到率可视化分析。此外,通过调用决策树算法(使用R+Shiny技术),系统可以构建决策树模型并在分析系统页面中直观呈现。未来,系统还计划支持多种算法的可视化分析,如因子分析和聚类分析。分段解释
相关代码示例:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 读取数据集
data = pd.read_csv('招生数据.csv')
# 数据预处理,包括特征选择、数据清洗等步骤
# 划分训练集和测试集
X = data.drop('招生结果', axis=1) # 特征数据
y = data['招生结果'] # 目标变量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建决策树模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
# 可以根据实际需求进行可视化展示,例如使用ECharts等库进行数据可视化
















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









