







 超级会员免费看
超级会员免费看
 最大频繁项集方法(MFI)是一种数据挖掘技术,与Apriori算法不同,它专注于寻找不能扩展为更频繁项集的频繁项集。通过上下双向遍历itemset网格,减少搜索空间,生成最大频繁项集。该方法最终用于产生关联规则,以揭示数据中的隐藏模式。
最大频繁项集方法(MFI)是一种数据挖掘技术,与Apriori算法不同,它专注于寻找不能扩展为更频繁项集的频繁项集。通过上下双向遍历itemset网格,减少搜索空间,生成最大频繁项集。该方法最终用于产生关联规则,以揭示数据中的隐藏模式。
Maximal Frequent Itemsets Approach(最大频繁项集方法)
Maximal Frequent Itemset(最大频繁项集):它是一组频繁项集,但是它的扩展集都不是频繁的。
最大频繁项集方法和Apriori算法不同点就在于从数据集中提取的itemset不同,最大频繁项集方法提取的是最大频繁项集,Apriori提取的是频繁项集。
如何提取最大频繁项集呢?
1.同时从上往下和从下往上遍历itemset网格图,遍历过程中要不断减少search space,从下往上是产生频繁项集candidate,从上往下是产生最大频繁项集candidate。
2.不断重复步骤1,直至遍历所有data。
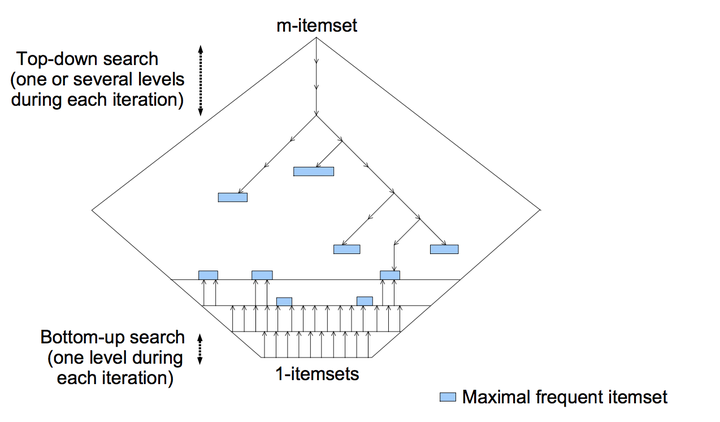
对于生成的最大频繁项集,生成关联规则。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











