









 本文详细介绍了一个经典的WordCount案例实现过程,包括如何通过MapReduce框架处理大量文本数据,并统计每个单词出现的频次。该案例使用了Hadoop平台,具体介绍了Mapper和Reducer两个核心阶段的工作原理及其实现代码。
本文详细介绍了一个经典的WordCount案例实现过程,包括如何通过MapReduce框架处理大量文本数据,并统计每个单词出现的频次。该案例使用了Hadoop平台,具体介绍了Mapper和Reducer两个核心阶段的工作原理及其实现代码。
WordCount案例详解
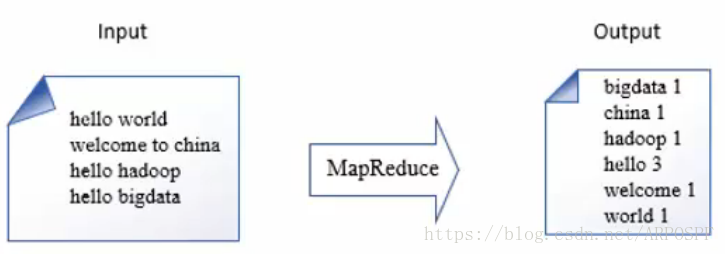
需求:文件中存储的各种各样的单词,统计在这些文件中每个单词的出现次数
WordCount Map阶段
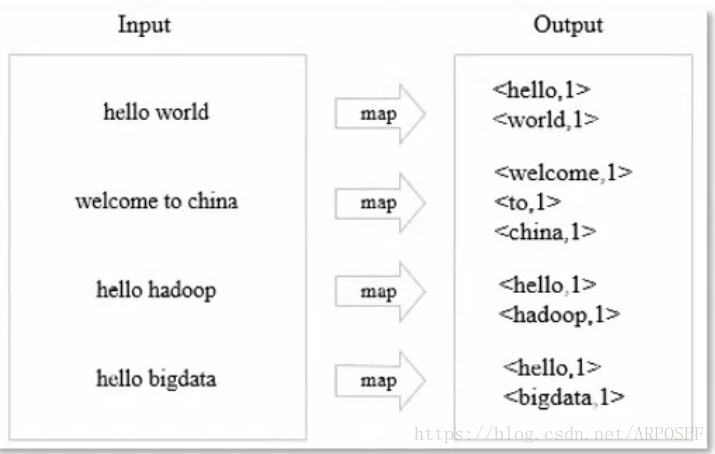
原理:针对每行数据应用map方法,按照分隔符拆分;Map阶段输出单词作为key,1作为value。
WordCount Reduce阶段
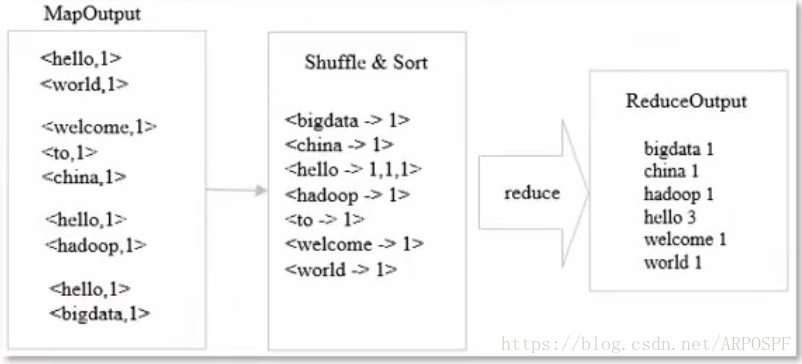
原理:从Map阶段拷贝对应的输出结果,统计每个单词出现的总词数
代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.FileOutputStream;
import java.io.IOException;
public class WC_MR {
static class WCMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split("\t");
for(String word : words){
context.write(new Text(word),new LongWritable(1));
}
}
}
static class WCReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for(LongWritable value : values){
count += value.get();
}
context.write(key,new LongWritable(count));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
String input = args[0];
String output = args[1];
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJobName("wordcount");
job.setJarByClass(WC_MR.class);
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job,new Path(input));
FileOutputFormat.setOutputPath(job,new Path(output));
System.exit(job.waitForCompletion(true)?0:1);
}
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











