




图神经网络框架DGL1.0初体验
DGL 1.0: Empowering Graph Machine Learning For Everyone
DGL 1.0 总结了过去三年学术界或工业界对图深度学习和图神经网络(GNN)技术的各类需求。从最先进模型的学术研究到将 GNN 扩展到工业级应用,DGL 1.0 为所有用户提供全面且易用的解决方案,以更好的利用图机器学习的优势。
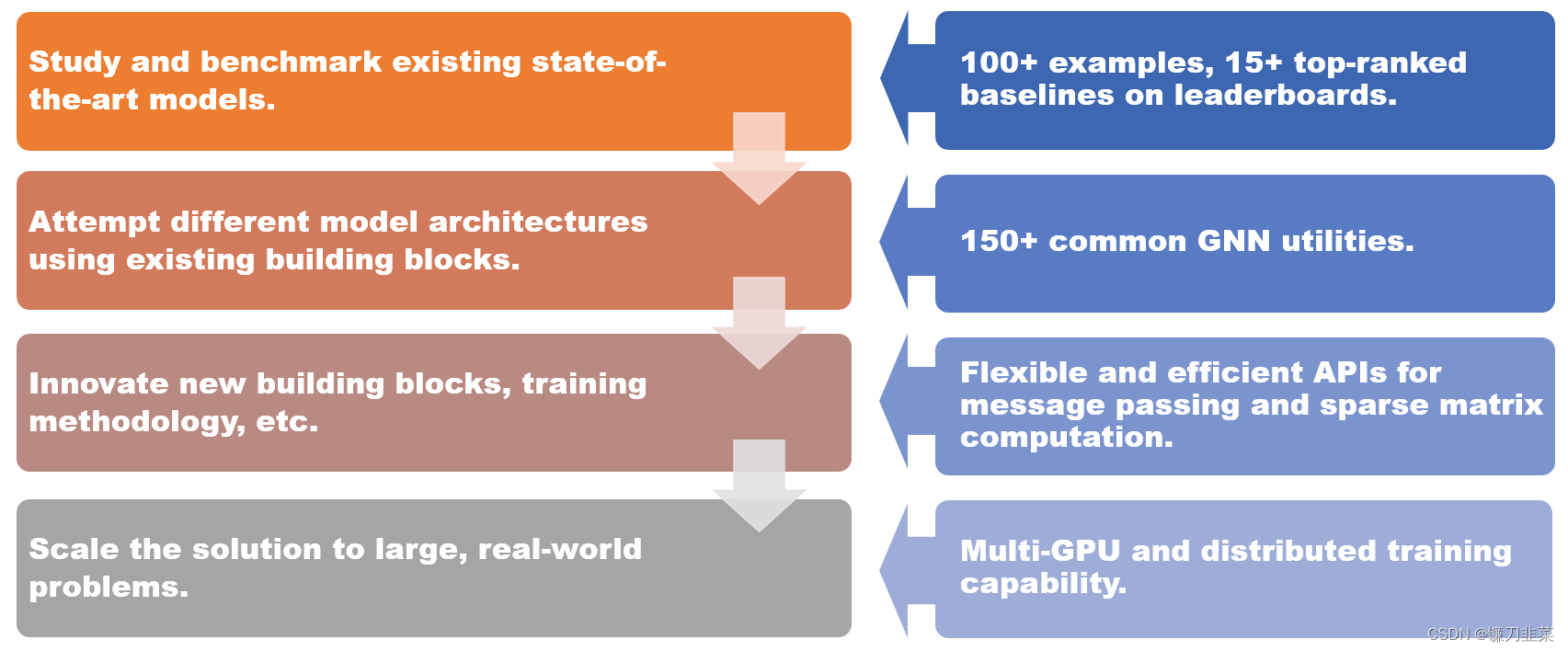
DGL 1.0 为不同场景提供的解决方案。
DGL 1.0 采用分层和模块化的设计,以满足各种用户需求。本次发布的关键特性包括:
- 100 多个开箱即用的 GNN 模型示例,15 多个在 Open Graph Benchmark(OGB)上排名靠前的基准模型;
- 150 多个 GNN 常用模块,包括 GNN 层、数据集、图数据转换模块、图采样器等,可用于构建新的模型架构或基于 GNN 的解决方案;
- 灵活高效的消息传递和稀疏矩阵抽象,用于开发新的 GNN 模块;
- 多 GPU 和分布式训练能力,支持在百亿规模的图上进行训练。
DGL 1.0技术栈图如下:
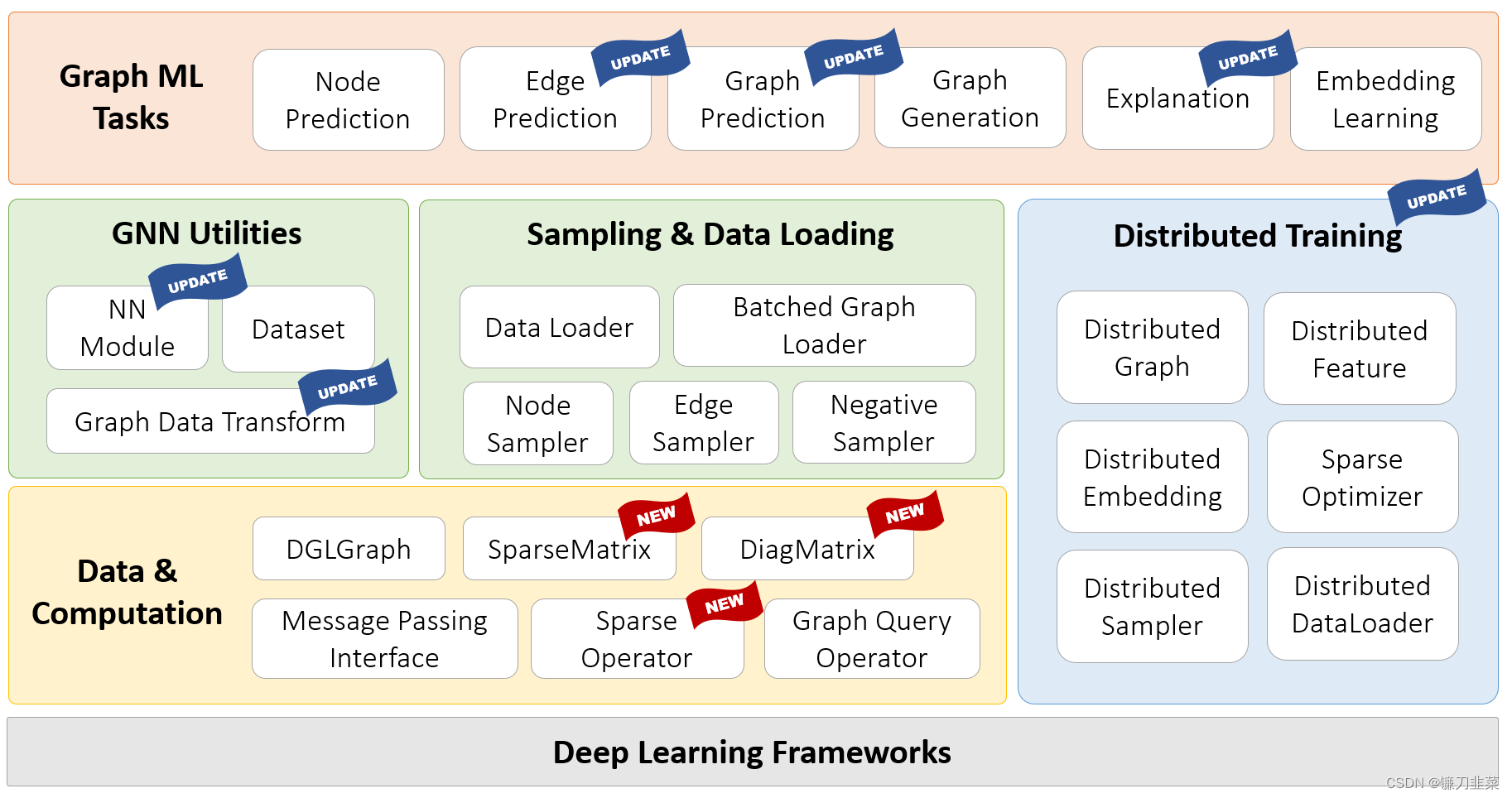
DGL github 代码地址:https://github.com/dmlc/dgl
此版本的亮点之一是引入了DGL-Sparse,这是一个全新的编程接口,使用了稀疏矩阵作为核心的编程抽象。DGL-Sparse不仅可以简化现有的GNN模型(例如图卷积网络)的开发,而且还适用于最新的模型,包括基于扩散的GNN,超图神经网络和图Transformer。
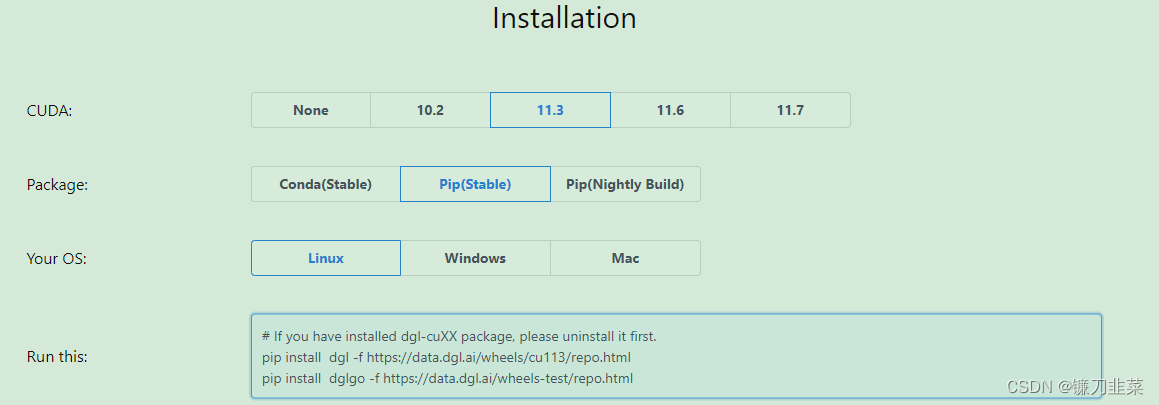
# If you have installed dgl-cuXX package, please uninstall it first.
pip install dgl -f https://data.dgl.ai/wheels/cu113/repo.html
pip install dglgo -f https://data.dgl.ai/wheels-test/repo.html
DGL中的两种GNN范式
DGL中包含两种主流的GNN范式,即消息传递视图(The Message Passing View)和矩阵视图(The Matrix View)。这些范式可以帮助研究人员更好地理解 GNN 的内部工作机制,而矩阵视角也是DGL Sparse开发的动机之一。
电影《降临》中有这么一句话:「你所使用的语言决定了你的思维方式,并影响了你对事物的看法。」这句话也适合GNN。
表示图神经网络有两种不同的范式:
- 第一种称为消息传递视图,从细粒度、局部的角度表达 GNN 模型,详细描述如何沿边交换消息以及节点状态如何进行相应的更新。
- 第二种是矩阵视角,由于图与稀疏邻接矩阵具有代数等价性,许多研究人员选择从粗粒度、全局的角度来表达 GNN 模型,强调涉及稀疏邻接矩阵和特征向量的操作。
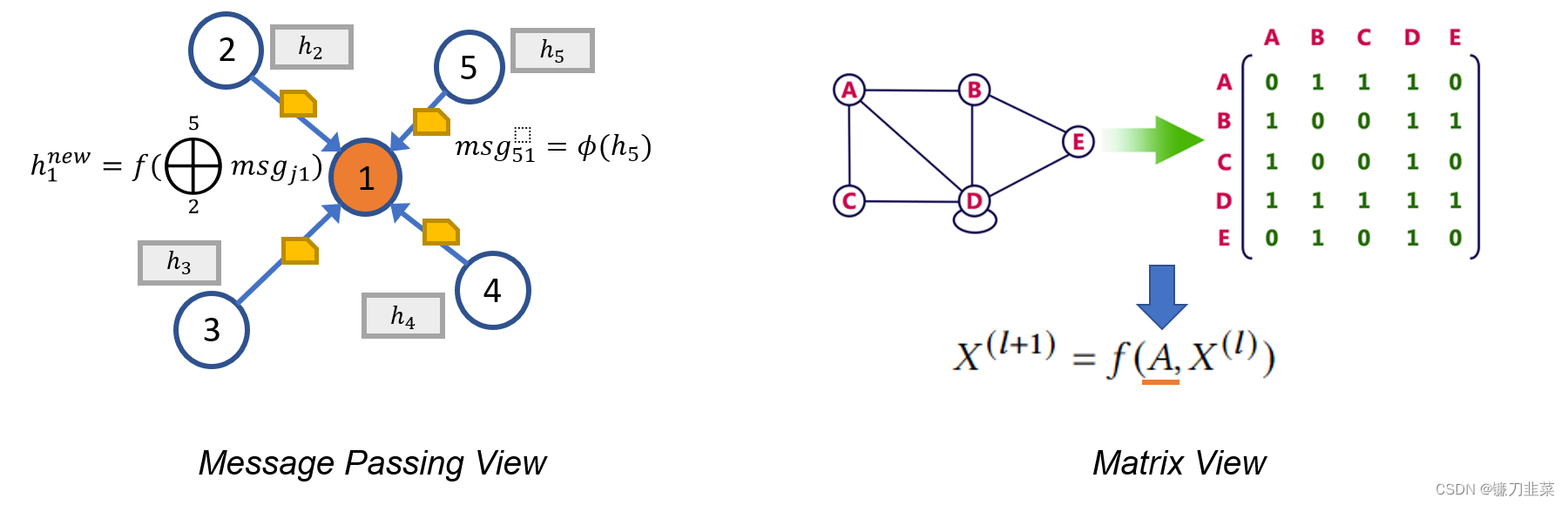
消息传递视角揭示了 GNN 与 Weisfeiler Lehman (WL)图同构测试之间的联系,后者也依赖于从邻居聚合信息。而矩阵视角则从代数角度来理解 GNN,引发了一些有趣的发现,比如过度平滑问题。
总之,这两种视角都是研究 GNN 不可或缺的工具,它们互相补充,帮助研究人员更好地理解和描述 GNN 模型的本质和特性。正是基于这个原因,DGL 1.0 发布的主要动机之一就是在已有的消息传递接口基础之上,增加对于矩阵视角的支持。
DGL Sparse:为图机器学习设计的稀疏矩阵库
DGL 1.0 版本中新增了一个名为 DGL Sparse 的库(dgl.sparse),它和 DGL 中的消息传递接口一起,完善了对于全类型的图神经网络模型的支持。DGL Sparse 提供专门用于 图机器学习的稀疏矩阵类和操作,使得在矩阵视角下编写 GNN 变得更加容易。在下一节中,作者演示多个 GNN 示例,展示它们在 DGL Sparse 中的数学公式和相应的代码实现。
图卷积网络(Graph Convolutional Network)
GCN 是 GNN 建模的先驱之一。GCN 可以同时用消息传递视图和矩阵视图来表示。下面的代码比较了 DGL 中用这两种方法实现的区别。

1)DGL message passing functions
class GCNLayer(nn.Module):
...
def forward(self, g, X):
g.ndata['X'] = X
g.ndata['deg'] = g.in_degrees().float()
g.update_all(self.message, fn.sum('m', 'X_neigh'))
X_neigh = g.ndata['X_neigh']
return F.relu(self.W(X_neigh))
def message(self, edges):
c_ij = (edges.src['deg'] * edges.dst['deg']) ** -0.5
return {'m' : edges.src['X'] * c_ij}
2)DGL sparse matrix package
import dgl.sparse as dglsp # DGL 1.0 sparse matrix package
class GCNLayer(nn.Module):
...
def forward(self, A, X):
D_invsqrt = dglsp.diag(A.sum(1)) ** -0.5
A_norm = D_invsqrt @ A @ D_invsqrt
return F.relu(self.W(A_norm @ X))
基于图扩散的GNN
图扩散是沿边传播或平滑节点特征或信号的过程。PageRank 等许多经典图算法都属于这一类。一系列研究表明,将图扩散与神经网络相结合是增强模型预测有效且高效的方法。下面的等式描述了其中比较有代表性的模型 APPNP 的核心计算。它可以直接在 DGL Sparse 中实现。
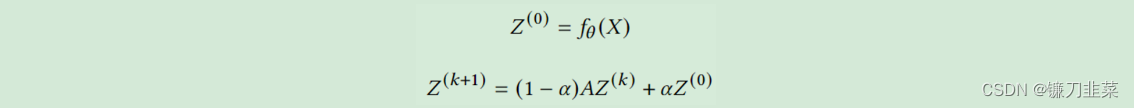
class APPNP(nn.Module):
...
def forward(self, A, X):
Z_0 = Z = self.f_theta(X)
for _ in range(self.num_hops):
A_drop = dglsp.val_like(A, self.A_dropout(A.val))
Z = (1 - self.alpha) * A_drop @ Z + self.alpha * Z_0
return Z
超图神经网络
超图是图的推广,其中边可以连接任意数量的节点(称为超边)。超图在需要捕获高阶关系的场景中特别有用,例如电子商务平台中的共同购买行为,或引文网络中的共同作者等。超图的典型特征是其稀疏的关联矩阵,因此超图神经网络 (HGNN) 通常使用稀疏矩阵定义。以下是超图卷积网络(Feng et al., 2018)和其代码实现。
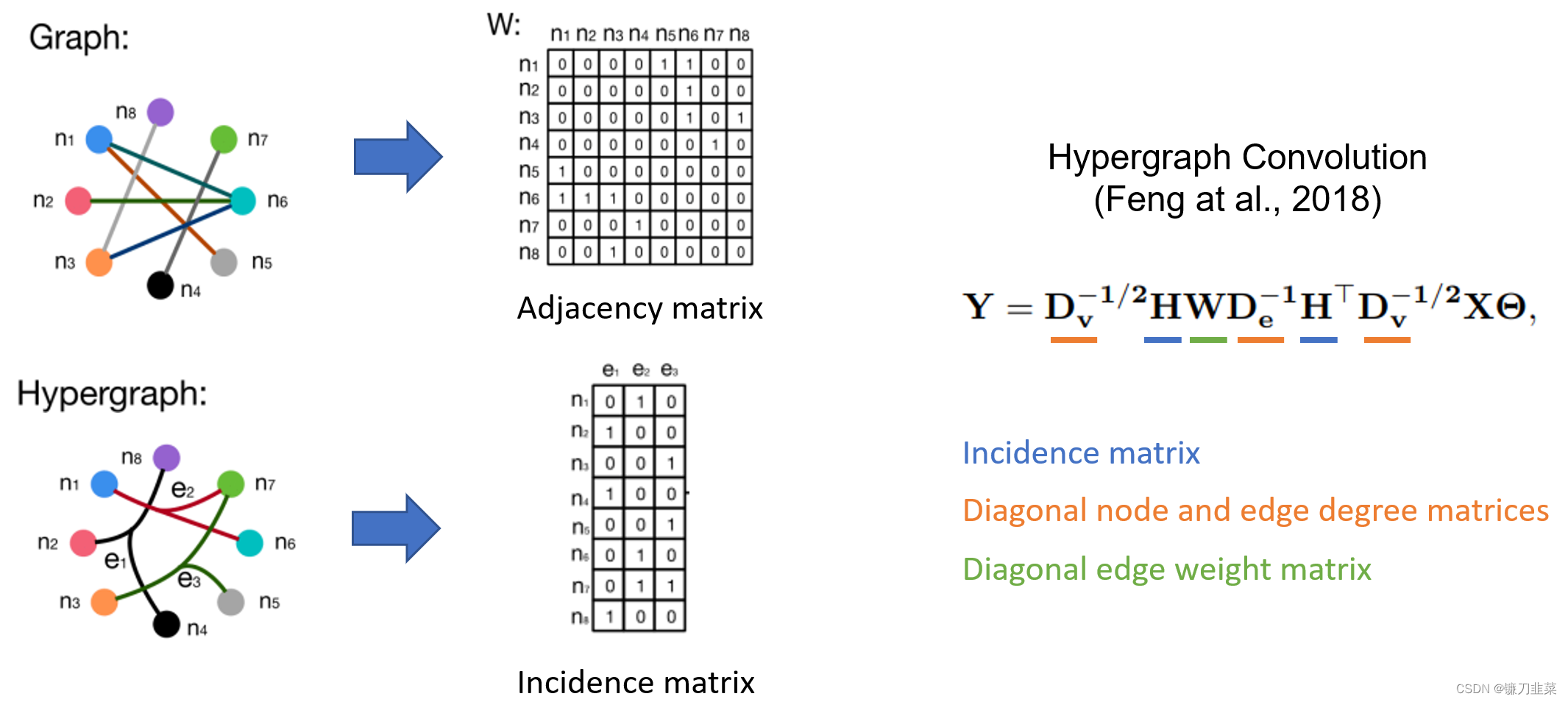
class HypergraphConv(nn.Module):
...
def forward(self, H, X):
d_V = H.sum(1) # node degree
d_E = H.sum(0) # edge degree
n_edges = d_E.shape[0]
D_V_invsqrt = dglsp.diag(d_V**-0.5) # D_V ** (-1/2)
D_E_inv = dglsp.diag(d_E**-1) # D_E ** (-1)
W = dglsp.identity((n_edges, n_edges))
L = D_V_invsqrt @ H @ W @ D_E_inv @ H.T @ D_V_invsqrt
return self.Theta(L @ X)
图 Transformer
Transformer 模型已经成为自然语言处理中最成功的模型架构。研究人员也开始将 Transformer 扩展到图机器学习。Dwivedi 等人开创性地提出将所有多头注意力限制为图中连接的节点对。通过 DGL Sparse 工具,只需 10 行代码即可轻松实现该模型。
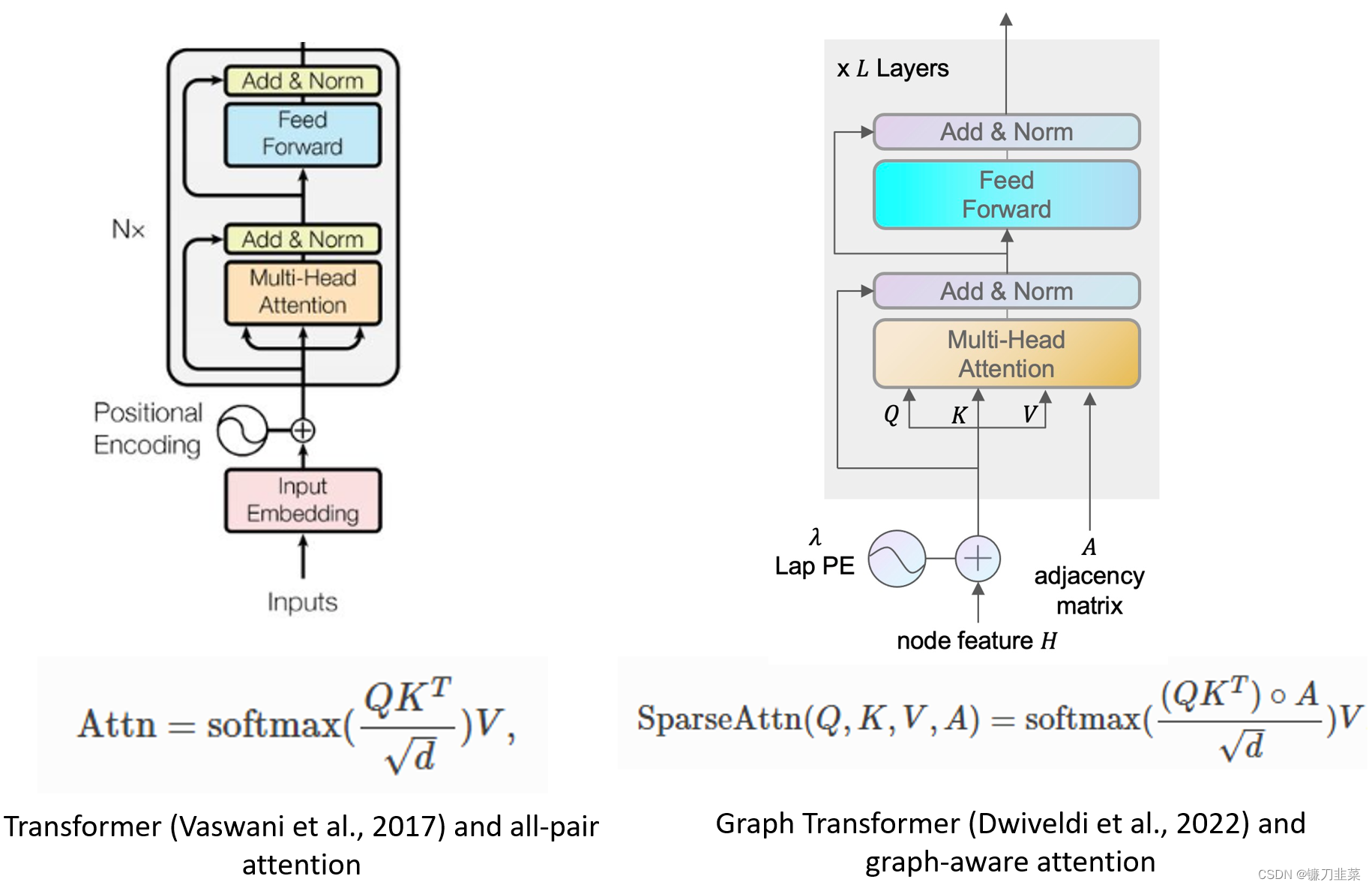
class GraphMHA(nn.Module):
...
def forward(self, A, h):
N = len(h)
q = self.q_proj(h).reshape(N, self.head_dim, self.num_heads)
q *= self.scaling
k = self.k_proj(h).reshape(N, self.head_dim, self.num_heads)
v = self.v_proj(h).reshape(N, self.head_dim, self.num_heads)
attn = dglsp.bsddmm(A, q, k.transpose(1, 0)) # [N, N, nh]
attn = attn.softmax()
out = dglsp.bspmm(attn, v)
return self.out_proj(out.reshape(N, -1))
DGL Sparse 的关键特性
相比scipy.sparse 或torch.sparse等稀疏矩阵库,DGL Sparse 的整体设计是为图机器学习服务,其中包括了以下关键特性:
- 自动稀疏格式选择:DGL Sparse 的设计让用户不必为了选择正确的数据结构存储稀疏矩阵(也称为稀疏格式)而烦恼。用户只需要记住
dgl.sparse.spmatrix创建稀疏矩阵,而 DGL 在内部则会根据调用的算子来自动选择最优格式; - 标量或矢量非零元素:很多 GNN 模型会在边上学习多个权重(如 Graph Transformer 示例中演示的多头注意力向量)。为了适应这种情况,DGL Sparse 允许非零元素具有向量形状,并扩展了常见的稀疏操作,例如稀疏 - 稠密 - 矩阵乘法(SpMM)等。可以参考 Graph Transformer 示例中的 bspmm 操作。
通过利用这些设计特性,与之前使用消息传递接口的矩阵视图模型的实现相比,DGL Sparse 将代码长度平均降低了 2.7 倍。简化的代码还使框架的开销减少 43%。此外DGL Sparse 与 PyTorch 兼容,可以轻松与 PyTorch 生态系统中的各种工具和包集成。
接下来,我们将正式开始使用DGL 1.0。可以使用 pip 或 conda 轻松安装。除了前面介绍的示例之外,DGL Sparse 的第一个版本还包括 5 个教程和 11 个端到端示例,所有教程都可以在 Google Colab 中直接体验,无需本地安装。
内容来源
- https://www.dgl.ai/release/2023/02/20/release.html
- https://mp.weixin.qq.com/s/DmjpGfBjytZZYKVnEC50Hw



















 1370
1370




 到【灌水乐园】发言
到【灌水乐园】发言









