







 超级会员免费看
超级会员免费看
多模态介绍及当前研究方向
什么是多模态?
什么是多模态?多模态指的是多种模态的信息,包括:文本、图像、视频、音频等。顾名思义,多模态研究的就是这些不同类型的数据的融合的问题。
目前大多数工作中,只处理图像和文本形式的数据,即把视频数据转为图像,把音频数据转为文本格式。这就涉及到图像和文本领域的内容。
多模态的任务和数据集有哪些?
多模态研究的是视觉语言问题,其任务是关于图像和文字的分类、问答、匹配、排序、定位等问题。
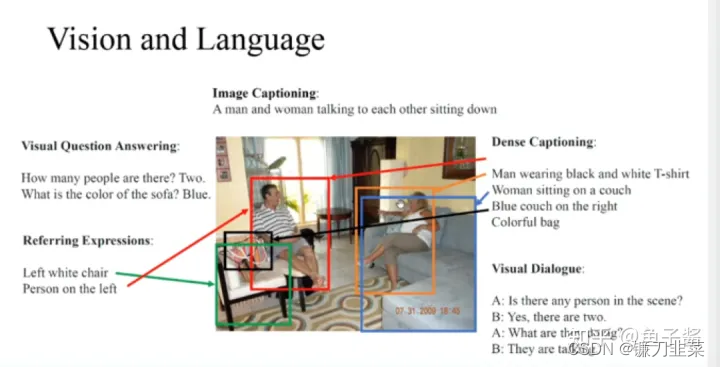
例如给定一张图片,可以完成以下任务:
- VQA(Visual Question Answering)视觉问答
输入:一张图片、一个自然语言描述的问题
输出:答案(单词或短语) - Image Caption 图像字幕
输入:一张图片
输出:图片的自然语言描述(一个句子) - Referring Expression Comprehension 指代表达
输入:一张图片、一个自然语言描述的句子
输出:判断句子描述的内容(正确或错误) - Visual Dialogue 视觉对话
输入:一张图片
输出:两个角色进行多次交互、对话 - VCR (Visual Commonsense Reas

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











