




爬取数据
参考博客:https://blog.youkuaiyun.com/weixin_74021639/article/details/138772911
主要使用etree来分析网页,对于格式化强的榜单来说爬取很方便。
数据分析
用到的绘图软件主要是python本身的库和DataEase。
深入一些的分析算法有关联规则Apriori算法、SHAP特征重要性分析。
关联规则——apriori算法
apriori算法参数含义
在使用 Apriori 算法(通常借助 Python 的mlxtend等相关库来实现)挖掘频繁项集并生成关联规则后,得到的结果数据中包含 antecedents、consequents、antecedent support、consequent support、support、confidence 这些字段,它们各自代表的含义如下:
1. antecedents含义:指的是关联规则中的前项,也就是规则里 “如果……” 这部分的内容。它表示在关联规则里,作为前提条件出现的项集(可以简单理解为一组商品、行为等元素的集合)。例如在关联规则 “如果购买了牛奶和面包,那么会购买鸡蛋” 中,antecedents 对应的就是 frozenset({'牛奶', '面包'}) 这样一个项集,表示规则的前置条件部分。数据类型及呈现形式:通常是 frozenset 类型,因为它是一个无序且不可变的集合形式,用来明确表示构成关联规则前提的元素组合情况。
2. consequents含义:代表关联规则中的后项,对应规则里 “那么……” 的部分,即基于前面的前提条件下,大概率会出现的另一个项集。继续上面的例子,consequents 就是 frozenset({'鸡蛋'}),意味着当满足前面购买牛奶和面包的前提时,往往会跟着购买鸡蛋这个结果。数据类型及呈现形式:同样多为 frozenset 类型,用于清晰界定关联规则后续所关联到的元素集合情况。
3. antecedent support含义:表示前项(antecedents 所代表的项集)在整个数据集中出现的频繁程度,即支持度。它是通过计算包含该前项的事务(例如购物篮记录等事务型数据中的一次记录)数量占总事务数量的比例来得到的。数值范围在 0 到 1 之间,值越高说明该项集在数据集中出现得越频繁。比如 antecedent support 的值为 0.3,表示在所有的购物篮记录中,出现前项里商品组合的购物篮占比为 30%。计算及作用:可以帮助衡量关联规则中前提条件本身的常见程度,为评估整个关联规则的有效性和重要性提供基础依据,也是后续计算其他指标(如置信度等)的一个重要参数。
4. consequent support含义:指的是后项(consequents 所代表的项集)在整个数据集中出现的频繁程度,同样是基于支持度的概念,计算的是包含该后项的事务数量与总事务数量的比例。例如其值为 0.2,意味着在所有购物篮记录中,包含后项里商品组合的购物篮占比是 20%。计算及作用:有助于了解关联规则中结果部分单独出现的频繁情况,与其他指标结合可以判断前后项之间关联的紧密程度以及规则的可靠性等。
5. support含义:关联规则的支持度,它反映了该关联规则(整个 “如果…… 那么……” 这样的完整表述)在整个数据集里出现的频繁程度,具体计算方式是同时包含前项和后项的事务数量占总事务数量的比例。比如 support 值为 0.15,就说明在全部的购物篮记录中,既满足前项情况又满足后项情况的购物篮占比是 15%。重要性:支持度是衡量关联规则重要性的一个关键指标,一般来说,支持度太低的关联规则可能只是偶然出现,缺乏实际意义,所以在实际应用中往往会设定一个最小支持度阈值,先筛选出支持度达到一定标准的关联规则再做进一步分析。
6. confidence含义:置信度,用来衡量基于前项发生的情况下,后项发生的概率。其计算方式是关联规则的支持度(support )除以 antecedent support,即 confidence = support / antecedent support。例如 confidence 的值为 0.8,表示在出现前项所描述的情况时,有 80% 的概率会出现后项所描述的情况,是判断关联规则强度、可靠性的重要指标之一。应用场景:在实际的关联规则挖掘中,通常希望找到置信度较高的规则,因为这意味着前提和结果之间有较强的关联性,能够为决策(比如商品推荐等应用场景)提供更可靠的依据。
SHAP特征重要性分析
由于我们爬取的数据大部分为文本的非结构化数据,为使用上述算法来进行特征分析,需将这些数据转化为结构化数据再进行下一步分析,所以引入分词,从词出发准确反映语义信息。项目中采用了python中使用广泛的Jieba分词工具,选用其精确模式,非常适合文本分析的场景;随机森林是一种基于多棵决策树的集成学习算法,它通过构建多个决策树,并综合这些决策树的预测结果来进行最终的决策,而并非依赖单棵树的输出;SHAP是一种模型事后解释方法,核心思想是计算特征对模型输出的边际贡献,SHAP构建一个加性的解释模型,将所有的特征都视为“贡献者”,来解释随机森林模型各个特征对最终目标(积分)的影响情况。
数据大屏
参考结构:https://gitee.com/iGaoWei/big-data-view
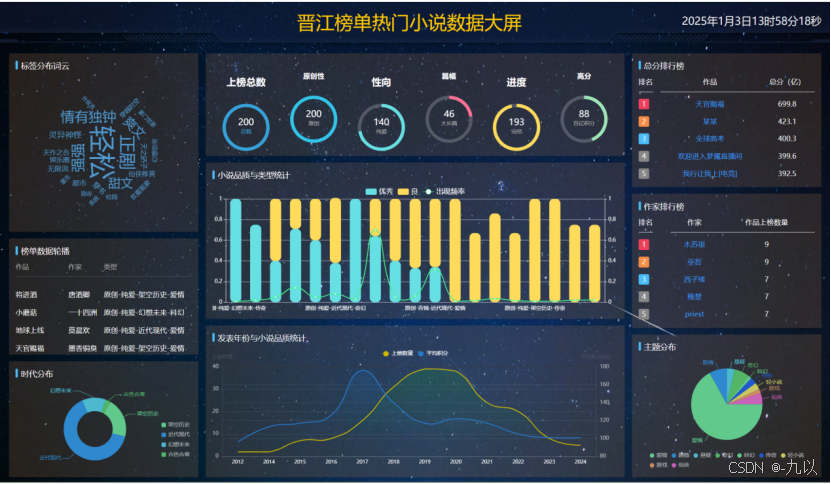
部分图表展示

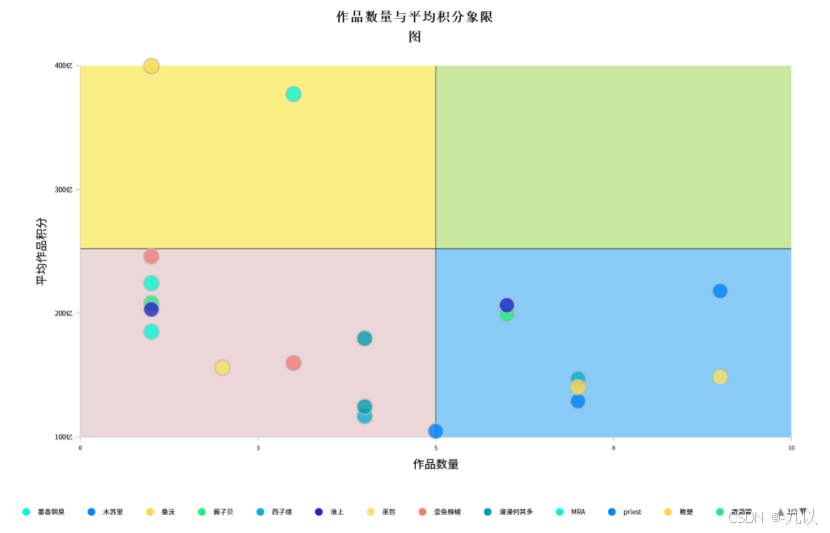
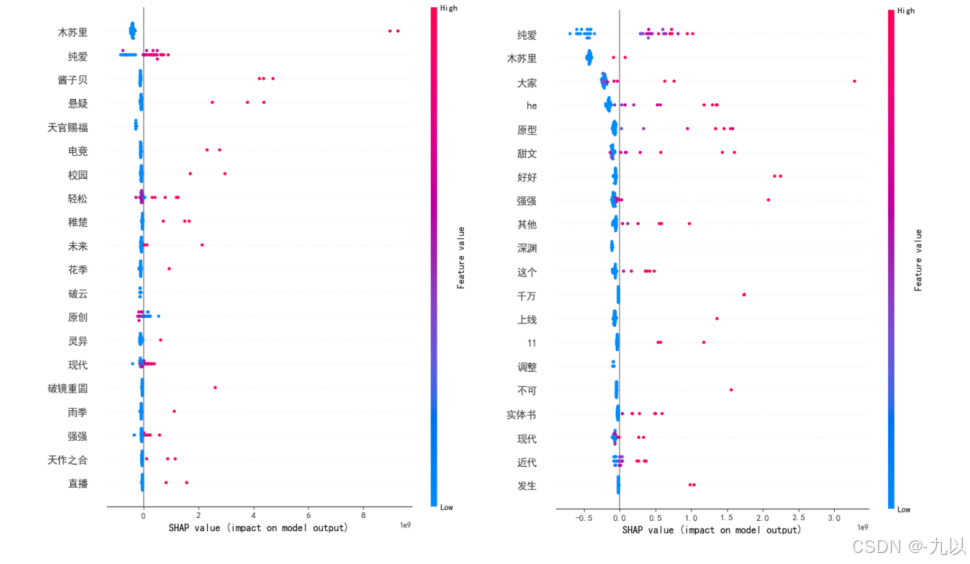
代码仓库:HomeWork/Data analysis of online novels at main · AM-SuSh/HomeWork



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









