




1.前言
位置编码(Positional Encoding)是自然语言处理(NLP)和序列建模中的一项关键技术,主要用于为模型提供序列中元素的位置信息。由于像Transformer这样的模型本身不具备处理序列顺序的能力(即它们是“置换不变”的),因此必须显式地引入位置信息,以便模型能够区分“我爱猫”和“猫爱我”这样的不同语序句子。
2.绝对位置编码(Absolute Positional Encoding)
每个位置被赋予一个唯一的编码,直接表示其在序列中的绝对位置。
最常见的是正弦/余弦编码(Sinusoidal Encoding),公式如下:
P
E
p
o
s
,
2
i
=
s
i
n
(
p
o
s
1000
0
2
i
d
m
o
d
e
l
)
PE_{pos,2i}=sin(\dfrac{pos}{10000^{\frac{2i}{d_{model}}}})
PEpos,2i=sin(10000dmodel2ipos)
p
o
s
pos
pos:位置索引(即第几个token)
i
i
i:维度索引(即token中第几个维度)
d
m
o
d
e
l
d_{model}
dmodel:嵌入向量的维度(如512)
3.相对位置编码
相对位置编码的核心理念是:对于一个词而言,它与其他词的“相对位置关系”比其“绝对位置”更重要。
例如,在句子 “I think I am right” 中,第二个 “I” 的指代关系更依赖于它前面和后面的词(“think” 和 “am”),而不是它处于整个句子的第2个位置。
因此,相对位置编码不再关注“每个词在序列中的绝对位置 ( i ) 和 ( j )”,而是关注“一对词 ( i ) 和 ( j ) 之间的相对距离 ( i - j )”。
3.1
首先,回顾一下标准自注意力的计算:
A
i
,
j
=
softmax
(
Q
i
K
j
T
d
k
)
A_{i,j} = \text{softmax}\left( \frac{Q_i K_j^T}{\sqrt{d_k}} \right)
Ai,j=softmax(dkQiKjT)
其中,
Q
i
=
(
X
i
+
P
i
)
W
Q
,
K
j
=
(
X
j
+
P
j
)
W
K
Q_i=(X_i+P_i)W^Q,K_j=(X_j+P_j)W^K
Qi=(Xi+Pi)WQ,Kj=(Xj+Pj)WK
如果我们把
Q
i
,
K
i
Q_i,K_i
Qi,Ki展开,会得到四项:
X
i
W
Q
(
X
j
W
K
)
T
+
X
i
W
Q
(
P
j
W
K
)
T
+
P
i
W
Q
(
X
j
W
K
)
T
+
P
i
W
Q
(
P
j
W
K
)
T
X_iW^Q(X_jW^K)^T+X_iW^Q(P_jW^K)^T+P_iW^Q(X_jW^K)^T+P_iW^Q(P_jW^K)^T
XiWQ(XjWK)T+XiWQ(PjWK)T+PiWQ(XjWK)T+PiWQ(PjWK)T
这四项分别代表:
- 内容-内容关联:词 ( i ) 的内容与词 ( j ) 的内容之间的相关性。
- 内容-位置关联:词 ( i ) 的内容与词 ( j ) 的绝对位置之间的相关性。
- 位置-内容关联:词 ( i ) 的绝对位置与词 ( j ) 的内容之间的相关性。
- 位置-位置关联:词 ( i ) 的绝对位置与词 ( j ) 的绝对位置之间的相关性。
3.1 Shaw et al. 相对位置编码
这是最早在Transformer中引入相对位置编码的论文之一 Self-Attention with Relative Position Representations (Shaw et al.2018), 使用相对位置信息 a i , j K , a i , j V a_{i,j}^K, a_{i,j}^V ai,jK,ai,jV来替代或修改这些项中依赖于绝对位置 P i , P j P_i, P_j Pi,Pj的部分。
具体步骤如下:
- 创建可学习的嵌入表:为每个在
[
−
k
,
k
]
[−k,k]
[−k,k]范围内的相对距离,分配两个可学习的嵌入向量:
- a i − j K a^K_{i-j} ai−jK:用于修饰键,影响注意力权重的计算。
- a i − j V a^V_{i-j} ai−jV:用于修饰值,影响注意力加权求和后的输出。
- 在注意力分数中,将原来的 Q i K j T Q_iK_j^T QiKjT 修改为 Q i ( K j + a i , j K ) T Q_i(K_j+a_{i,j}^{K})^T Qi(Kj+ai,jK)T ,这使得在计算词j相对于词i的重要性时,考虑了词j相对于词i的位置。
- 在注意力输出中,将 A i , j V j A_{i,j}V_j Ai,jVj 修改为 A i , j ( V j + a i , j V ) A_{i,j}(V_j+a_{i,j}^V) Ai,j(Vj+ai,jV),这使得在聚合信息时,不仅聚合了来自词j的内容信息,还聚合了i和j的相对位置信息。
缺点:计算效率低下,无法将所有的 a i , j V a_{i,j}^V ai,jV 聚合为一个矩阵 B B B ,然后计算 Q B T QB^T QBT,因为 B B B 的每一行会随 i i i 变化而变化,换句话说,不存在矩阵 B B B 使得 B j = a i , j V B_j=a_{i,j}^V Bj=ai,jV对所有 i i i 成立,所以无法进行高效的批量矩阵乘法。
3.2 Transformer-XL 中的相对位置编码
把标准transformer中的公式:
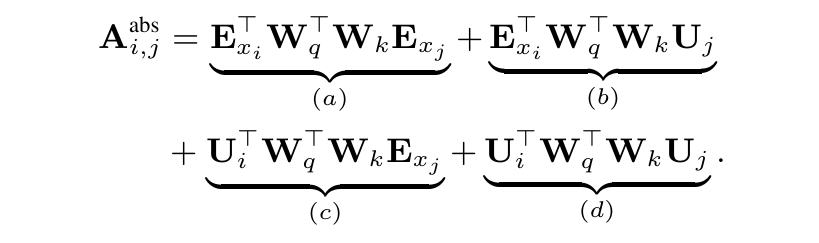
修改为
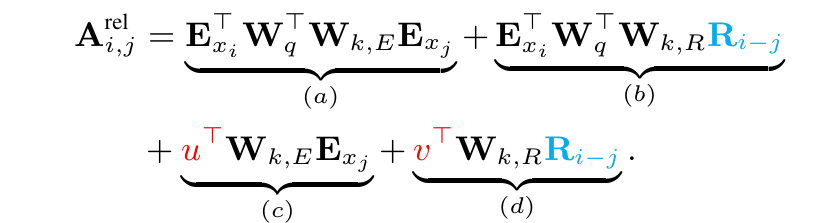
其中,绝对位置编码
U
j
U_j
Uj 被替换为相对位置编码
R
i
,
j
R_{i,j}
Ri,j,
U
i
T
W
q
T
U_i^TW_q^T
UiTWqT 被替换为可学习参数
u
,
v
u,v
u,v
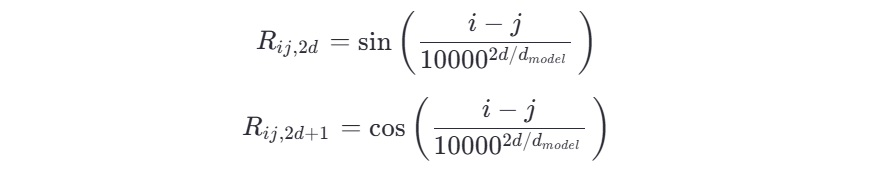
3.3 旋转位置编码 (Rotary Position Embeddingz)
RoPE是一种相对位置编码方法,它通过将位置信息以旋转矩阵的形式融入 Query 和 Key 的向量表示中,从而在不增加参数、不改变模型结构的前提下,让注意力机制能够感知 token 的相对位置。
目标: 我们希望在计算注意力分数时,内积
q
T
k
q^Tk
qTk 的结果只依赖于这两个token的相对位置差 m-n,而不是它们的绝对位置 m,n 。
实现方式: RoPE 为每个位置 pos 分配一个独特的旋转矩阵
R
p
o
s
,
θ
R_{pos,\theta}
Rpos,θ ,这个矩阵的作用是将词向量在某个维度平面上进行旋转,旋转的角度
θ
\theta
θ 与位置 pos 成正比,公式如下:
θ
i
=
p
o
s
1000
0
2
i
d
m
o
d
e
l
,
i
=
0
,
1
,
.
.
.
,
d
2
−
1
\theta_i = \dfrac{pos}{10000^{\frac{2i}{d_{model}}}},i=0,1,...,\frac{d}{2}-1
θi=10000dmodel2ipos,i=0,1,...,2d−1
假设向量
q
,
k
q,k
q,k只有两个维度,RoPE 的旋转操作如下:
对于位置为 m 的token,查询向量
q
q
q 会旋转
m
θ
m\theta
mθ 角度
对于位置为 n 的token,键向量
k
k
k 会旋转
n
θ
n\theta
nθ 角度
旋转矩阵
R
θ
R_\theta
Rθ 在二维下是:
R
θ
=
[
cos
θ
−
sin
θ
sin
θ
cos
θ
]
R_\theta = \begin{bmatrix} \cos \theta & -\sin \theta \\ \sin \theta & \cos \theta \end{bmatrix}
Rθ=[cosθsinθ−sinθcosθ]
旋转后的向量内积为
(
R
m
,
θ
q
)
T
(
R
n
,
θ
k
)
=
q
T
R
m
,
θ
T
R
n
,
θ
k
(R_{m,\theta}q)^T(R_{n,\theta}k)=q^TR_{m,\theta}^TR_{n,\theta}k
(Rm,θq)T(Rn,θk)=qTRm,θTRn,θk
由于旋转矩阵是正交矩阵,故
R
m
,
θ
T
=
R
m
,
θ
−
1
=
R
−
m
,
θ
R_{m,\theta}^T=R_{m,\theta}^{-1}=R_{-m,\theta}
Rm,θT=Rm,θ−1=R−m,θ
又
R
m
,
θ
R
n
,
θ
=
R
m
+
n
,
θ
R_{m,\theta}R_{n,\theta}=R_{m+n,\theta}
Rm,θRn,θ=Rm+n,θ
则
q
T
R
m
,
θ
T
R
n
,
θ
k
=
q
T
R
n
−
m
,
θ
k
q^TR_{m,\theta}^TR_{n,\theta}k=q^TR_{n-m,\theta}k
qTRm,θTRn,θk=qTRn−m,θk
最终的内积结果只依赖于原始向量 q,k,以及它们的相对位置 n-m,实现了我们的目标。注意,尽管 RoPE 使用绝对位置
m
m
m 来构造旋转矩阵,但其在注意力机制中实际起作用的是相对位置
m
−
n
m-n
m−n ,使用绝对位置 ≠ 是绝对位置编码,关键看模型在实际计算中利用的是绝对位置还是相对位置。
在现实中,向量的维度远大于2,RoPE将
d
d
d 维的向量空间看成
d
/
2
d/2
d/2 个二维的子空间,对于第
i
i
i 个子空间,分配一个旋转角度
θ
i
\theta_i
θi ,具体如下:
(
cos
m
θ
0
−
sin
m
θ
0
0
0
⋯
0
0
sin
m
θ
0
cos
m
θ
0
0
0
⋯
0
0
0
0
cos
m
θ
1
−
sin
m
θ
1
⋯
0
0
0
0
sin
m
θ
1
cos
m
θ
1
⋯
0
0
⋮
⋮
⋮
⋮
⋱
⋮
⋮
0
0
0
0
⋯
cos
m
θ
d
/
2
−
1
−
sin
m
θ
d
/
2
−
1
0
0
0
0
⋯
sin
m
θ
d
/
2
−
1
cos
m
θ
d
/
2
−
1
)
(
q
0
q
1
q
2
q
3
⋮
q
d
−
2
q
d
−
1
)
\begin{pmatrix} \cos m\theta_0 & -\sin m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\ \sin m\theta_0 & \cos m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\ 0 & 0 & \cos m\theta_1 & -\sin m\theta_1 & \cdots & 0 & 0 \\ 0 & 0 & \sin m\theta_1 & \cos m\theta_1 & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \cdots & \cos m\theta_{d/2-1} & -\sin m\theta_{d/2-1} \\ 0 & 0 & 0 & 0 & \cdots & \sin m\theta_{d/2-1} & \cos m\theta_{d/2-1} \end{pmatrix} \begin{pmatrix} q_0 \\ q_1 \\ q_2 \\ q_3 \\ \vdots \\ q_{d-2} \\ q_{d-1} \end{pmatrix}
cosmθ0sinmθ000⋮00−sinmθ0cosmθ000⋮0000cosmθ1sinmθ1⋮0000−sinmθ1cosmθ1⋮00⋯⋯⋯⋯⋱⋯⋯0000⋮cosmθd/2−1sinmθd/2−10000⋮−sinmθd/2−1cosmθd/2−1
q0q1q2q3⋮qd−2qd−1
左侧是位置
m
m
m 的旋转矩阵,右侧是对应的 q 向量。
RoPE 通过这种优雅的几何变换,将相对位置信息自然地融入了注意力机制,成为了 LLaMA等众多现代大语言模型的首选位置编码方案。

















 1567
1567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









