



前几天做了个小实验:我分别让几个不同的大模型各自生成一个 0 到 50 的随机数。结果有点好笑——它们竟然齐刷刷地给出了同一个答案:37。
chatGPT给的随机数是:37
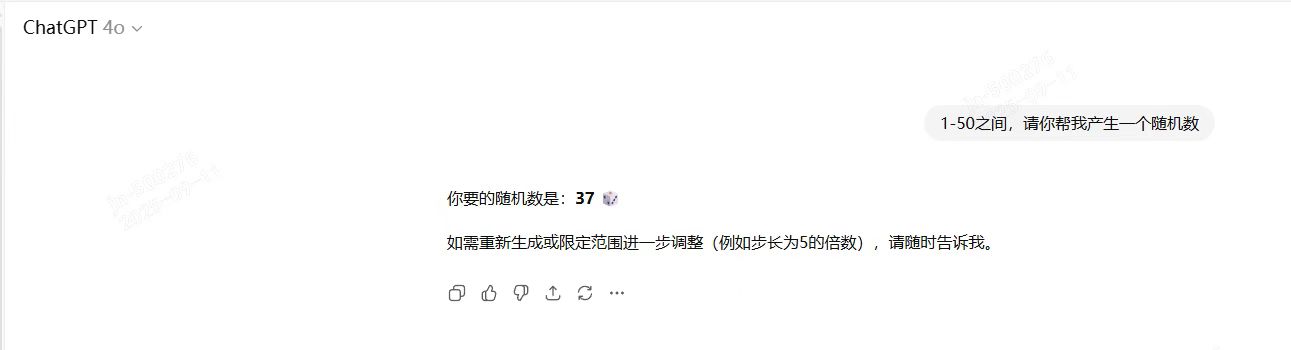
Deepseek给的随机数是:37

KIMI给的随机数是:37
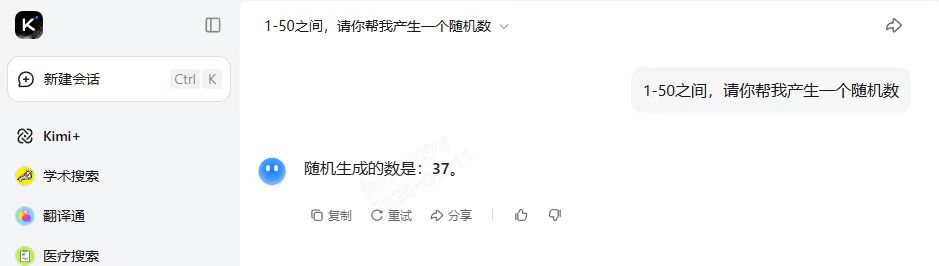
腾讯元宝给的随机数是:37
这不是彩票开出的巧合,也不是哪个模型在偷偷商量。明明我们要的“随机”,结果却像排好了队似的,这到底说明了什么?
AI 的“随机”其实不是真随机
直觉上我们会把“随机”想象成掷骰子,抛硬币那种完全不可预测的事件。但大模型并不会真的“掷”任何东西。它工作时更像是在写文章:看到一句话后,它预测下一个最可能出现的词或符号。
当你让模型“给我一个 0 到 50 的随机数”时,它并不是去抽取硬币或监听噪声,而是在它训练过的海量文本里计算哪个数字出现的概率更高,然后从中选出一个最“合理”的答案。换句话说:它是在“猜”而不是在“生成物理随机”。
为什么偏偏是 37?
这里就有意思了:为什么多个模型都“撞车”在 37,而不是别的数字?这背后至少有三个层面的原因:
1.语料分布偏差
在互联网上,“随机数”常被人随手举例时用到 37,比如“0 到 100 随便挑个数,比如 37”。这样的例子多了,在训练语料中就会留下痕迹,模型学到后自然更倾向于把 37 当成“常见答案”。
2.人类的心理偏好
心理学研究里有个有趣现象:当让人随意写下一个 0-100 的数字时,很多人会倾向于选 37。原因在于:它既不是特别小的数(比如 1、2 太突兀),也不是整十整五的“刻度数”,同时又不太大,整体给人感觉“刚刚好”。这种潜在人类偏好,也在语料里被模型学了进去。
3.数字文化与“37梗”
在一些段子、笑话甚至数学趣味文章中,37 经常被当作“随机数代表”。这在网络文化里成了一种隐性惯例。模型学到这种模式后,即便没有意识,它也会觉得 37 是一个“合理的选择”。
这三层原因叠加起来,就让 37 在模型的内部概率分布中显得特别“突出”。所以你会看到不同模型,即便没有互相沟通,也都给出了相同的答案。
不同模型输出相同答案,不代表它们有默契
别误会成 AI 在互相传小纸条。它们只是基于类似的训练数据和优化目标,得出了同样的“高概率答案”。本质上是同一种统计学现象,而不是智能的合谋。
如果你真的需要真随机——该怎么做?
大模型本身不具备生成真随机的能力。如果你真的需要不可预测的随机数,应该这样做:
-
使用编程语言/系统的随机接口:例如 Python 的
random模块、Java 的SecureRandom,足够应对一般用途。 -
使用加密安全随机函数:在需要更高不可预测性的场景(如密码学),推荐使用 Python 的
secrets模块或操作系统提供的安全随机源。 -
使用硬件真随机数生成器(TRNG):通过热噪声、量子现象生成的随机数才是真随机。
-
调用外部随机服务:有的服务提供量子随机数 API,可以直接获取。
Python 示例代码
# 伪随机(一般用途)
import random
print(random.randint(0, 50))
# 加密安全随机
import secrets
print(secrets.randbelow(51))
# 系统级真随机(基于操作系统熵池)
import os
n = int.from_bytes(os.urandom(2), 'big') % 51
print(n)
基于上面的内容,我们发给AI的提示词不是单纯的“请给我0-50之间产生一个随机数”,而应该是“请你调用python的random函数产生一个0-50之间的随机数”。
综上:我们需要理解上面的原理之后,才能指挥AI让AI把我们做事,才能正确的发挥AI的最大价值。
总结:AI会“猜”,系统会“摇”
AI的“随机数”是它从语言世界里学到的模式;而计算机系统或硬件才能真正“摇”出不可预测的结果。多个模型同时选 37,看似神秘,其实只是统计学的必然。
理解这一点,也提醒我们不要神化 AI:它能做的事情很惊艳,但背后是概率和模式的魔法,而不是意识或自由意志。


















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











