



 本文介绍了PCA(主成分分析)作为一种常见的数据降维方法,通过找出数据的主要特征,减少冗余,优化数据表示。文章详细阐述了PCA的数学推导过程,包括中心化、协方差矩阵、特征值和最大特征值的寻找,以及降维的实际步骤。
本文介绍了PCA(主成分分析)作为一种常见的数据降维方法,通过找出数据的主要特征,减少冗余,优化数据表示。文章详细阐述了PCA的数学推导过程,包括中心化、协方差矩阵、特征值和最大特征值的寻找,以及降维的实际步骤。
目录
前言
什么是PCV降维
PCA(Principal Component Analysis)是一种常用的降维技术,即将高维数据转换为低维数据的方法。通俗地说,PCA降维就是通过找到数据中的主要特征,并将其用较少的特征来表示,从而减少数据的维度。
下图为例,所有的数据是分布在三维空间中,PCA将三维数据映射到二维平面u,二维平面由向量<u1,u2>表示,u1与u2垂直
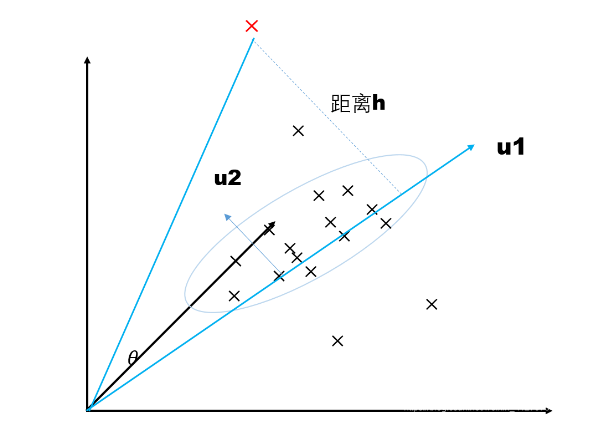
应用场景
假设你有一个数据集,它有很多特征(维度),比如说100个。但是你发现这些特征之间可能存在冗余或者相关性,有些特征对数据的贡献可能不是很大。在这种情况下,你可以使用PCA来降低数据的维度。
PCA的数学推导
假设对n个样本进行PCA处理,先对数据进行中心化,即将数据的均值变为0(为了后面计算的方便,不用减去mean)
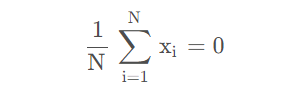
则数据集的协方差矩阵为:
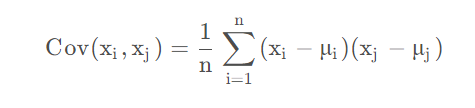
由于上面已经将数据中心化,
均为0,所以这里的协方差可以简化为下面的式子
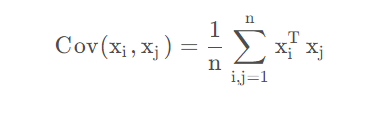
PCA的主要目的是找到一个线性变换,让数据投影的方差最大化
内基的补充
假设找到线性变化单位向量),对
做线性变化的投影,可知:
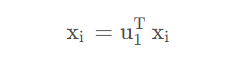
然后计算投影后的均值和方差
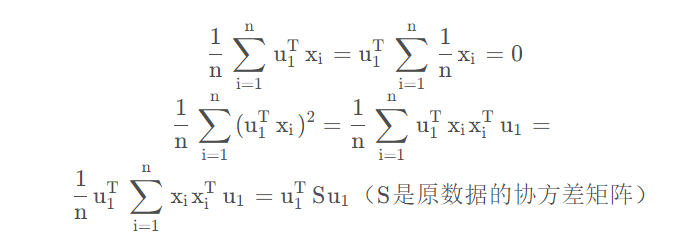
我们要投影后的方差取最大,可以得到优化函数,如下
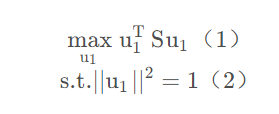
这里的(1)是我们的目标函数,(2)是约束条件,然后构建拉格朗日函数得
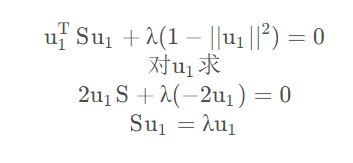
要求得(1)式的max,即要λ \lambdaλ最大,而λ \lambdaλ是矩阵S的特征值,问题就转换为求S的最大特征值,求解的方法有SVD矩阵分解和特征值分解。

PCA降维的过程
- x投影后的方差,就是x协方差矩阵的特征值,想要方差最大,就是要找协方差矩阵最大的特征值,最佳投影方向就是最大特征值对应的特征向量
- 协方差的特征值有特征向量有
,
,.....
,特征向量有
,
,....
- 将所有特征值从大到小排列,将相应的特征向量随之排列,选择特征向量的前k行组成的矩阵(
)乘以原始数据矩阵X,就得到我们需要的降维后的数据矩阵Y
PCA的流程
假设n个d维样本进行PCA处理
- 将原始数据按列组成d行n列矩阵X
- 将X的每一行去中心化,即减去这一行的均值
- 求出X的协方差矩阵
- 求出协方差矩阵的特征值和对应的特征向量
- 将特征向量根据对应的特征值大小从上到下按行排列,取前m行组成矩阵P
- Y=PX即为降维到m维的数据

















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









