





文摘要概述
论文Datasets for Large Language Models: A Comprehensive Survey(arXiv:2402.18041)从五个方面对LLM数据集的基本方面进行了整合和分类:(1)预训练语料库;(2)指令微调数据集;(3)偏好数据集;(4)评价数据集;(5)传统自然语言处理(NLP)数据集。
该论文提供了对现有可用数据集资源的全面回顾,包括来自444个数据集的统计数据,涵盖8个语言类别,跨越32个领域,整合了来自20个维度的统计信息。调查的总数据量超过了774.5TB的预训练语料库和7亿个其他数据集实例。
*这里重点对该论文的前半部分,即预训练语料库和指令微调数据集进行分析讨论。
论文局限
这篇论文只综述了纯文本的数据集,不包括多模态数据集。
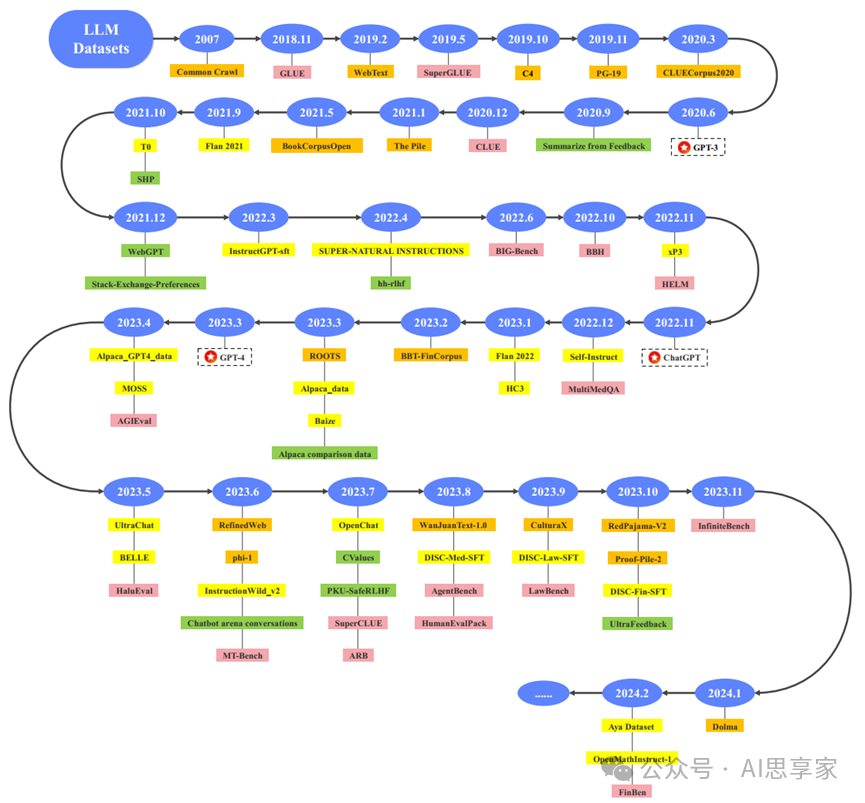
图1. 代表性大型语言模型数据集的时间线
橙色代表预训练语料库,黄色代表指令微调数据集,绿色代表偏好数据集,粉色代表评估数据集。
Part.A 预训练语料
在预训练阶段,LLM从大量未标记的文本数据中学习广泛的知识,然后将其存储在模型参数中。作为LLM的基石,预训练语料库影响着预训练的方向以及模型未来的潜力,预训练语料在提供通用性、增强泛化能力、提升性能水平、支持多语言处理等方面发挥重要作用。
01 预训练语料分类
预训练语料库可以包含各种类型的文本数据,如网页、学术材料、书籍,同时也可以容纳来自不同领域的相关文本,如法律文件、年度财务报告、医学教科书和其他特定领域的数据。
各种预训练语料库各有特色,亦存在不足之处。网页是预训练语料库中最普遍和最广泛的数据类型,但它通常包含大量的噪音,无关信息和敏感内容,使其不适合直接使用。社交媒体数据中可能存在有害信息,如偏见、歧视和暴力,但它对于LLM的预训练仍然是至关重要的。因为社交媒体数据有利于模型学习对话交流中的表达能力,以及捕捉社会趋势、用户行为模式等。书籍资料拥有更连贯的文本结构和更高的数据质量,但通常情况下,它们的更新速度较慢,可能无法及时反映当下的语言使用习惯和社会变迁。此外,书籍的覆盖领域和语言风格可能较为有限,这可能会限制模型在多样化和现实世界场景中的应用能力。因此,在选择预训练语料库时,需要综合考虑数据的多源性、覆盖面、时效性以及可能存在的偏差和风险,以确保预训练出的模型既具有广泛的适用性,又能在特定领域内表现出色。
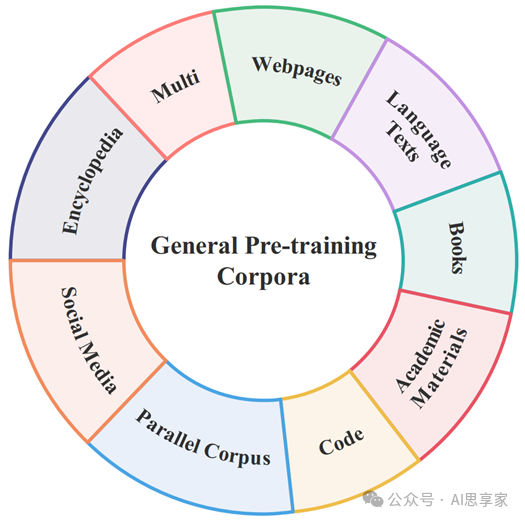
图2. 通用预训练语料库的数据类别
02 网页预训练语料库的构建方法
网页语料库的构建通常有两种主要方法。
第一种方法是建立在Common Crawl的基础上。许多后续的预训练语料库是通过从Common Crawl中重新选择和清洗数据而得到的。例如,RefinedWeb、C4、mC4、CC100、OSCAR 22.01、RedPajamaV2、CC-Stories、RealNews、CLUECorpus2020、CulturaX等。
第二种方法是独立抓取各种原始网页,然后采用一系列清洗过程来获得最终的语料库。例如,WuDaoCorpora-Text、MNBVC、WanJuanText-1.0、TigerBot pretrain zh corpus等。
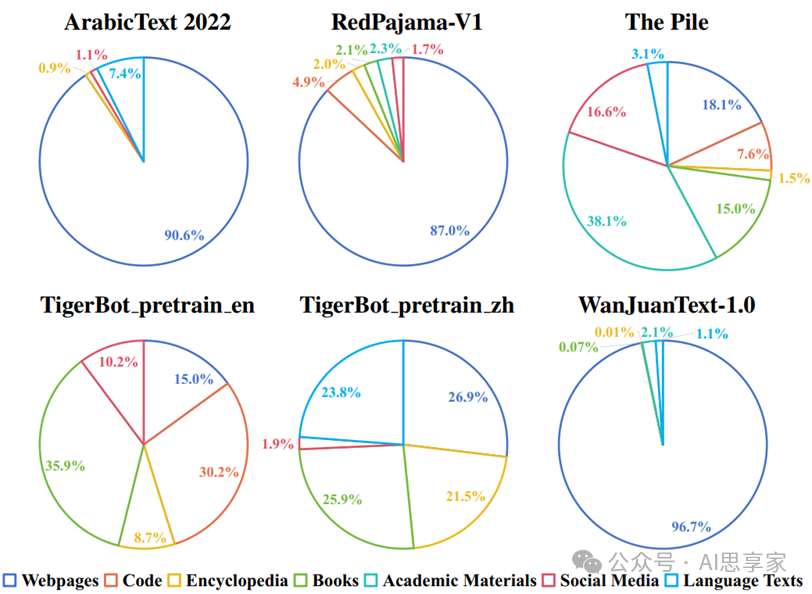
图3. 饼图展示了选定多类别预训练语料库的数据类型分布
相应的预训练语料库名称位于每个饼图的上方。不同的颜色代表不同的数据类型。
财经领域
财经领域大模型语料来源:财经新闻、财务报表、公司年报、金融研究报告、金融文献、市场数据。
财经大模型语料库:BBT-FinCorpus(大规模中文金融领域语料库)、FinCorpus(轩辕的训练语料)、FinGLM、TigerBot-research、TigerBot-earning。
医疗领域
医疗领域大模型语料来源:医学文献、医疗诊断记录、病例报告、医学新闻、医学教科书和其他相关资料。
医疗大模型语料库:Medical-pt(开源的医学百科全书和医学教科书数据集)、PubMed Central(医学文献)
法律领域
法律领域大模型语料来源:法律文书、法律书籍、法律条款、法院判决和案件、法律新闻和其他法律资料。
法律大模型语料库:TigerBot-law(包含11类中国法律法规)
交通领域
交通领域大模型语料来源:交通文献,交通技术项目,交通统计,工程建设信息,管理决策信息,交通术语。
交通领域大模型语料库:TransGPT(国内首个开源大型交通模型)
数学领域
数学领域大模型语料来源:数学相关代码、数学网络数据和数学论文。
数学领域大模型语料库:Llemma
特别提示:
在使用任何预训练语料库之前,建议查看适用许可证的具体条款和条件,以确保符合相关规定。Apache-2.0、ODC-BY、CC0和Com
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









