




知乎:天晴
链接:https://zhuanlan.zhihu.com/p/703825827
背景与目标
最终目标是在 LLAMA3 模型的基础上进行继续训练与 SFT,但 LLAMA3 的数据与配比方案并未公开,因此期望从其他方案中获得配比的思路,从而确保预训练与 SFT 不会严重影响原本的模型效果。
当前一种潜在的不伤害原模型的方法是,直接继续训练/SFT,随后通过 参数合并Merge 来保留原始效果。
首先需要调研现有的方案,思路为:
-
公开的预训练数据配比
-
公开的 SFT 配比方案
-
探测 LLAMA3 配比的潜在方法
更新日期:2024.07.29
-
前文:天晴:论文解读:如何自动选择 SFT 数据
-
后文:天晴:多模态数据混比工作调研
https://zhuanlan.zhihu.com/p/690779419
https://zhuanlan.zhihu.com/p/713670161
LLAMA 和 Qwen 技术报告
最新的Qwen2和LLAMA3.1终于是公布了很多数据细节,当然也包括数据配比问题。
Qwen2
预训练数据增强
Qwen2 的预训练数据分为 启发式方法过滤 和 Qwen 模型过滤。虽然实现细节未阐明,但根据其他工作,启发式方法可能类似 C4 数据的过滤方法。Qwen 模型过滤则可能是由 GPT 对模型进行 1-5 的质量分数打标,随后对 Qwen 的一个小版本(如 0.5B)进行微调,使其只输出 1-5 的分数 token。
数据扩充
Qwen2 包含了代码、数学、多模态数据,也包括多语数据。最关心的 数据分布 依然是含糊的,目标是让数据分布与人类相似的学习一致。通过实验,对不同来源和领域划分方法进行混合。
数据规模
Qwen1.5 使用了 3T 数据,而 Qwen2 扩充至 7T 数据。团队还尝试继续放宽数据质量筛选阈值,扩充到 12T 数据。然而,在打榜精度上,7T 和 12T 的训练并无显著差异。
长上下文训练
Qwen2 的长上下文训练分为几个阶段:
-
4k 上下文训练
-
32k 上下文训练
-
使用 RoPE 位置编码,将频率从 1 万增加到 100 万(频率越高,能容纳的上下文越长)
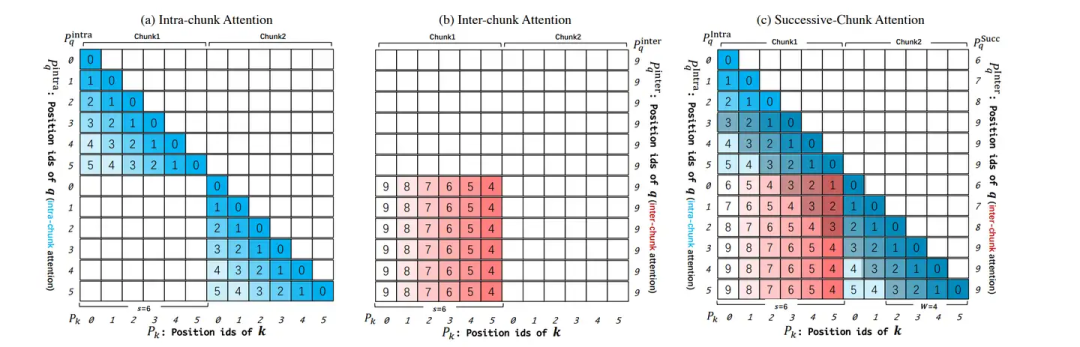
此外,Qwen2 还使用了 YARN 和 Dual Chunk Attention 机制,支持 131k 上下文(实践上,是对长上下文进行Chunk切分,随后在chunk内与chunk间进行相对位置信息的捕捉)。
后训练
核心是使用了大量非人工合成数据,值得关注的趋势是:
-
人机协作数据打标:使用 InsTag 模型生成标签,人工改进表述。依据标签多样性、语义性、复杂度、意图完整性评估筛选出具有代表性的数据;借助一些LLM数据演进生成的工作,例如Self-Evolution,进行数据合成;最后也包括人工标注。
-
自动数据合成:例如,使用 Rejection Sampling 进行数学任务推导,或者通过 Execution Feedback 对代码任务进行执行筛选。随后是SFT常见的Data Repurposing,为各种任务,借助LLM基于某些源数据,来构造任务数据。对于Qwen它还做了安全审查,当然这里我可能并不需要。
LLAMA3.1
数据清洗与质量过滤
LLAMA3.1 对数据进行了清洗和过滤,包括:
-
排除不安全的网站 URL
-
HTML 数据抽取(发现在预训练数据里包含markdown是有害的)
-
去重(URL、MinHash for Docs、ccNet for Lines会删除导航栏cookie警告以及一些高质量数据)
-
启发式过滤(n-gram 去重、脏词过滤、KL 散度过滤等)
数据质量过滤:fasttext判断docs与Wikipedia的相关,distilRoberta分类器由LLAMA2打质量标签训练去预测质量分数。distilRoberta分类器还被训练去判断代码和数学推理的数据。
相较于前代版本,有了更多的多模态数据,唯独中文的不多。
数据配比
基于知识分类和Scaling Law实验来测试配比的合理性。
知识分类:分类器划分预训练数据为领域知识数据,例如按着 艺术、娱乐...分类
Scaling Law实验确定数据配比:基于同一个数据配比,训练若干个不同的小模型(从40M到16B),观察其scaling曲线。(我猜是人工设置的配比候选),最终结构:50%通用、25%数学以及推理、17%代码、8%多语。最终通用是什么样子也不清楚
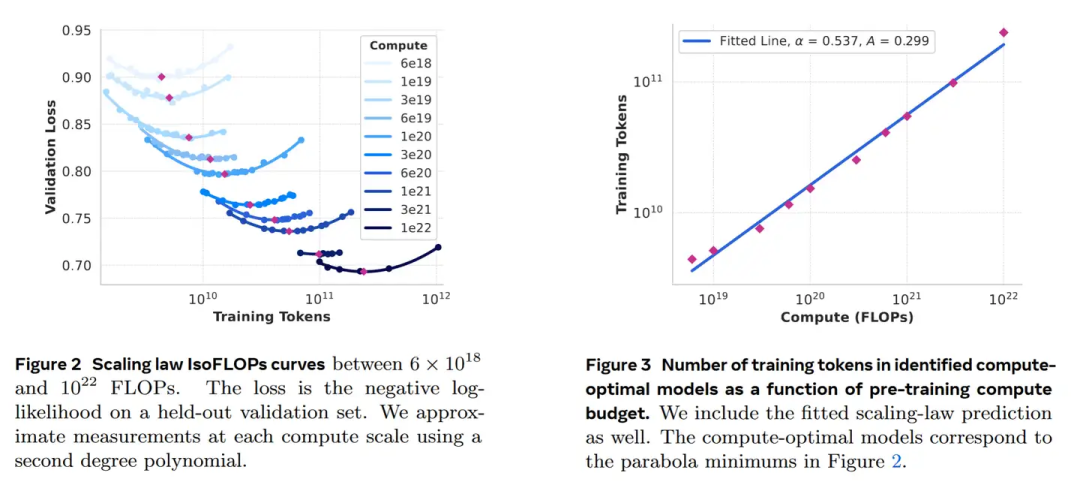

左图为浮点计算量与Loss的scaling law曲线,右图是loss与accuracy之间的曲线。有趣的一点是,loss与acc的关系,不是一个线性的
长上下文数据与退火训练
长上下文数据:基于两个标准来判断是否应该增加一个上下文长度:1) 在短上下文下性能恢复 2) 已经可以完美解决某长度下的 大海捞针。所以现在的长上下文,基本是照着大海捞针任务设计的,对于真正其他的长上下文需求,考虑的并不充分。
退火数据:基于高质量代码和 数学数据在预训练尾部做退火(可以提升GSM8k 24%,Math 6.4%)。
一个重要的发现是,退火训练可以评判小规模领域数据的价值。70%数据由原始配比方案获得,30%由需要测试的目标数据获得,在40B Tokens的退火训练中,将一个训练到50%的8B模型,学习率从开始降低至0,随后进行测评或者观察Loss。基于退火法测试小数据集比基于Sca
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6501
6501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









