



语音理解与生成的飞速发展离不开大规模高质量语音数据集的推动。其中,语音识别(ASR)和语音合成(TTS)被公认为最首要的任务。但对于拥有约 1.2亿 母语使用者的川渝方言而言,受限于标注资源匮乏,研究进展缓慢,ASR 与 TTS 的表现始终不尽如人意。现有公开的川渝方言语料库在规模、风格和标注维度上普遍存在不足。例如ASR-CSichDiaCSC和ASR-SCSichDiaDuSC 仅能提供小规模数据,覆盖的场景非常有限;此外,川渝方言评测集更是稀缺,仅有KeSpeech包含西南官话的测试子集。同时,这些语料往往只提供语音-文本对齐信息,缺乏说话人属性或声学质量等元数据,极大限制了其在自监督学习、风格建模和多任务训练中的应用,导致主流 ASR 与 TTS 系统在川渝方言任务上表现欠佳,并在真实场景中泛化能力不足。
为解决上述问题,希尔贝壳联合西北工业大学音频语音与语言处理研究组(ASLP@NPU)、中国电信人工智能研究院、南京大学和Wenet开源社区,提出了 WenetSpeech-Chuan,首个大规模多维标注的川渝方言语音语料库,涵盖 10000 小时、9 大领域的川渝方言语音数据,并包含 ASR 转录、文本置信度、说话人情感、年龄、性别、语音质量评分等多种标注信息。同时,我们还发布了 WSC-Eval,这是一个全面的川渝方言评测基准,包含两个部分:WSC-Eval-ASR(人工标注集,用于评测不同场景(Easy/Easy)声学条件下的 ASR 性能),以及 WSC-Eval-TTS(简单和困难子集,用于标准测试与泛化能力测试)。实验结果表明,基于 WenetSpeech-Chuan 训练的模型在川渝方言 ASR 与 TTS 任务中表现优异,性能超越最先进(SOTA)的系统,并与商业系统相媲美,凸显了该数据集与流程的重要价值。
相关技术报告 “WenetSpeech-Chuan: A Large-Scale Sichuanese Corpus with Rich Annotation for Dialectal Speech Processing” 已公开发布。我们已全面开源数据、代码和模型,诚邀各位开发者与研究者试用,共同推动川渝方言语音技术的发展!
方言领域缺乏大规模开源数据,严重制约了语音技术的发展,这一问题在使用广泛的四川方言中尤为突出。为填补这一关键空白,我们推出了 WenetSpeech-Chuan,一个拥有 1 万小时、注释丰富的语料库,并基于我们自主设计的完整方言语音处理框架——Chuan-Pipeline 构建而成。为了支持严格的评估并展示该语料库的有效性,我们还发布了手工校验转录的高质量 ASR 和 TTS 基准集 WenetSpeech-Chuan-Eval。实验表明,在开源系统中,使用 WenetSpeech-Chuan 训练的模型已达到当前最优性能,甚至在某些场景下可与商业系统媲美。作为目前最大的四川方言开源语料库,WenetSpeech-Chuan 不仅降低了方言语音研究的门槛,也在推动 AI 公平性与缓解语音技术偏见方面发挥着重要作用。语料库、基准测试、模型及相关材料均已在我们的项目主页上公开发布。
这也是希尔贝壳继开源大规模粤语标注数据WenetSpeech-Yue之后,对方言语音数据研究做出的又一贡献!
WenetSpeech-Yue: 首个具有多维度标注的大规模粤语语音语料库开源!

项目主页链接:https://github.com/ASLP-lab/WenetSpeech-Chuan
论文题目:WenetSpeech-Chuan: A Large-Scale Sichuanese Corpus with Rich Annotation for Dialectal Speech Processing
合作单位:西北工业大学音频语音与语言处理研究组、中国电信TeleAI、南京大学、WeNet开源社区
作者列表:戴宇航、张子萸、王帅、李龙豪、郭钊、左天伦、王水源、薛鸿飞、王成有、王晴、徐昕、卜辉、李杰、康健、张彬彬、谢磊
仓库地址:https://github.com/ASLP-lab/WenetSpeech-Chuan
Demo展示:https://aslp-lab.github.io/WenetSpeech-Chuan/
WenetSpeech-Chuan数据集地址:https://huggingface.co/datasets/ASLP-lab/WSC-Train
WSC-Eval-ASR: https://huggingface.co/datasets/ASLP-lab/WSC-Eval/tree/main/WSC-Eval-ASR
WSC-Eval-TTS:https://huggingface.co/datasets/ASLP-lab/WSC-Eval/tree/main/WSC-Eval-TTS
背景动机
近年来,大规模开源数据集极大地推动了自动语音识别(ASR)和语音合成(TTS)任务的发展。然而,当这些任务应用于口音或方言语音时,仍面临诸多挑战。已有研究表明,ASR 系统在处理方言时常因发音差异和声学失配而表现不佳,甚至在面对轻微口音的语音时也会出现明显性能下降。同样,关于带口音的 TTS 的研究也指出,准确建模口音变化极具难度。
在众多汉语方言中,这一问题在四川-重庆方言(以下简称四川方言)中尤为突出。四川方言是中国西南地区最主要的语言之一,使用人数约 1.2 亿人。其声调系统、词汇和语法与普通话存在显著差异,形成了清晰的语言区隔。然而,由于缺乏专门面向方言的大规模数据集,主流 ASR 和 TTS 系统在四川话语者中的表现大幅下降,迫切需要一个面向四川方言的大规模开源语料库。然而,现有的开源资源在数据规模和多样性方面仍严重不足。
目前公开可用的四川方言数据集仅包括两个小型语料库:4.53 小时的ASR-CSichDiaCSC和6.4 小时的ASR-SCSichDiaDuSC。虽然 KeSpeech 数据集也包含了部分带西南官话口音的样本,但这些语音更多是带口音的普通话,而非真正的四川方言。由于数据规模小、覆盖面窄,这些资源无法支撑鲁棒的 ASR 和 TTS 模型训练。
基于我们在 WenetSpeech 系列项目中构建大规模语音语料的经验,我们此次提出了 WenetSpeech-Chuan,以解决四川方言语音资源的关键缺口。WenetSpeech-Chuan 是一个包含超过 1 万小时四川方言语音的高质量注释语料库,涵盖短视频、综艺、直播等多个真实使用场景。为支持语料库构建与后续研究,我们还提出了 Chuan-Pipeline —— 一个完整的四川方言语音数据处理框架,用于从原始语音中高效构建高质量语料资源。最后,我们发布了两个精细校验的基准测试集 —— WSC-Eval-ASR 与 WSC-Eval-TTS,以支持严格、可复现的系统评估。
Chuan-Pipeline
为了构建 WenetSpeech-Chuan 数据集,我们提出了一个完整的语音数据处理流程 —— Chuan-Pipeline,如下图所示。该流程能够系统性地将原始、未标注的音频转换为适用于高质量 ASR 和 TTS 研究的丰富注释语料。
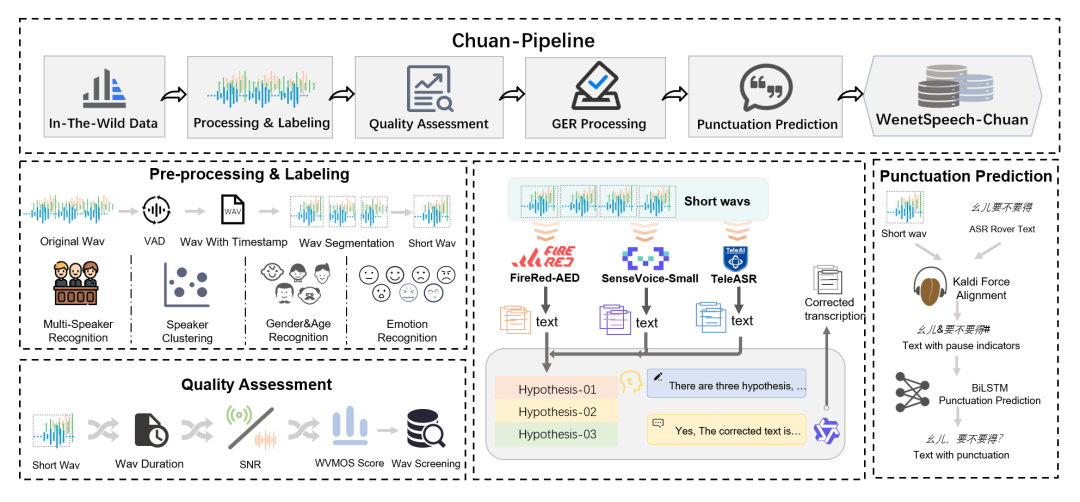
图1 Chuan-Pipeline概览
预处理与标注阶段
该阶段主要包括数据获取、切分处理以及多维度副语言(paralinguistic)信息的标注。数据采集从在线视频平台抓取元数据开始,用于筛选可能包含四川话的内容。在通过人工初步确认方言后,音频流将进入以下处理流程:
语音活动检测(VAD)与切分: 通过 VAD 技术将长音频分割为 5–25 秒的语音片段,同时剔除静音和噪声等非语音部分。
单说话人筛选与聚类: 首先使用 pyannote 工具包识别出单说话人的语音片段,然后利用 CAM++ 模型提取说话人嵌入向量并进行聚类,为每位说话人分配统一 ID。
副语言信息标注:
- 性别识别: 使用一个预训练分类器,准确率达 98.7%。
- 年龄估计: 基于 Vox-Profile 基准,划分为儿童、青少年、青年、中年和老年五个阶段。
- 情感识别: 使用 Emotion2vec 和 SenseVoice 的预测结果进行多数投票,覆盖七类情感(高兴、生气、悲伤、中性、恐惧、惊讶、厌恶)。
音频质量评估
为了确保语料质量,我们引入自动音频质量评估机制。该机制以对齐后的语音片段为输入,提取如音频时长、信噪比(SNR)等特征,并计算词级虚拟主观评分(WVMOS)以估测感知音质。质量较差的语音样本将被剔除。
LLM-GER 转录处理框架
为了提升四川话的自动语音识别精度,我们在前人研究基础上提出了名为 LLM-GER 的转录框架(Large Language Model-based Generative Error Correction based ROVER)。
第一步:使用三种不同的 ASR 系统(FireRed-ASR、SenseVoice-Small 和 TeleASR)分别生成初步转录文本;
第二步:利用 Qwen3 大模型进行错误修复与融合。通过设计好的 Prompt,大模型能够理解方言表达,并进行语义一致、不改变 token 数量的纠错操作;
第三步:生成四份转录结果后,根据它们之间的一致性计算最终的转录置信度。
该方法综合了多个 ASR 系统的优势,同时利用 LLM 对方言表达的强理解能力,实现高质量的四川话转录。实验证明,相较于单一系统,LLM-GER 平均可提升约 15% 的转录准确率。
通过 Chuan-Pipeline,我们实现了四川方言大规模、高质量语音数据的系统化构建,为后续多语言、多任务语音研究提供了坚实基础。
标点预测
准确带标点的转录文本对 TTS 训练至关重要,但仅依靠文本的标点预测往往与实际语音停顿不匹配。为此,我们提出一种融合音频与文本的多模态标点预测方法。
音频部分:使用 Kaldi 模型对音频与文本进行强制对齐,获取词语时间戳及停顿时长。根据阈值(如短停顿 0.25 秒,长停顿 0.5 秒)将停顿划分为短停顿和长停顿。
文本部分:利用双向 LSTM(BiLSTM)标点模型对停顿候选处进行标点预测:短停顿处插入逗号,长停顿处插入句号、问号或感叹号。
阈值调整:通过人工反馈不断迭代优化停顿时长阈值,确保标点与实际语音停顿高度匹配。
WenetSpeech-Chuan
通过应用Chuan-Pipeline处理收集到的多源原始数据,我们构建了WenetSpeech-Chuan语料库,一个大规模、多标签、多领域的四川话语音语料库。本节将详细介绍该语料库,包括其元数据、音频格式、数据多样性,以及训练集和评估集的设计原则。
数据规模与置信度
我们为每段音频分配了一个置信度,衡量ASR转录的质量。如下表所示,我们选择了置信度高于0.90的3,714小时“强标签”数据;置信度介于0.60到0.90之间的6,299小时“弱标签”数据则保存在元数据中,供半监督或其他用途使用。综上,WenetSpeech-Chuan共包含10,013小时原始音频。
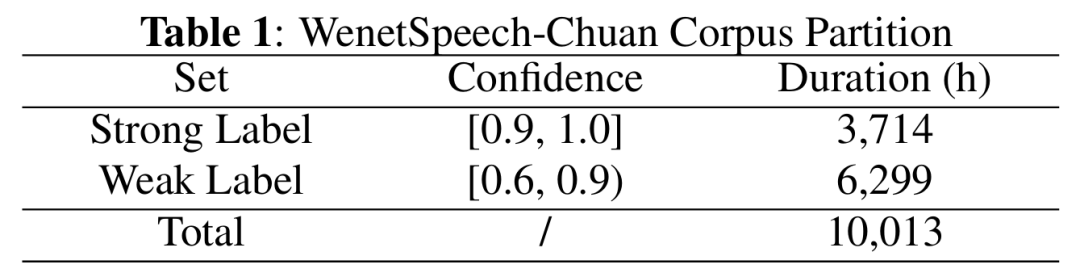
表1 WenetSpeech-Chuan标签置信度分布
领域分布
下图总结了WenetSpeech-Chuan的来源领域,共包含9个类别。短视频占比最大(52.83%),其次是娱乐类(20.08%)和直播类(18.35%)。纪录片、有声书、访谈、新闻、朗读和戏剧等其他领域比例较小,但丰富了数据集的多样性。
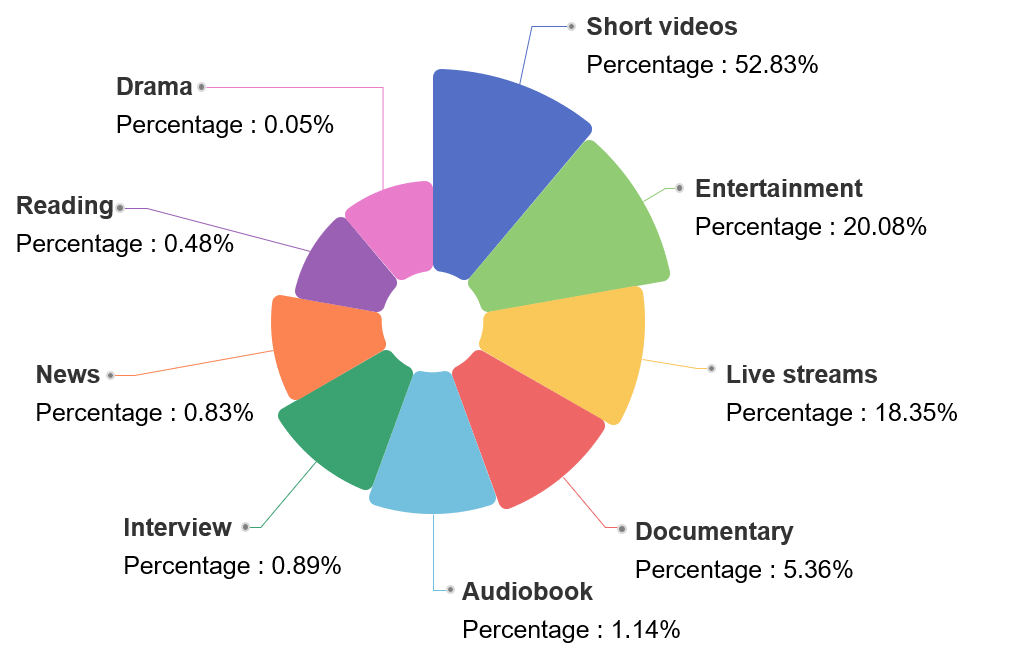
图2 数据领域分类
质量分布
如下图所示,基于WVMOS指标计算的音频质量得分主要集中在2.5到4.0区间,3.0到3.5之间有显著峰值。该分布表明语料库大部分数据质量处于中高水平,兼顾了干净录音与真实环境噪声,适合用于训练通用的鲁棒语音模型。
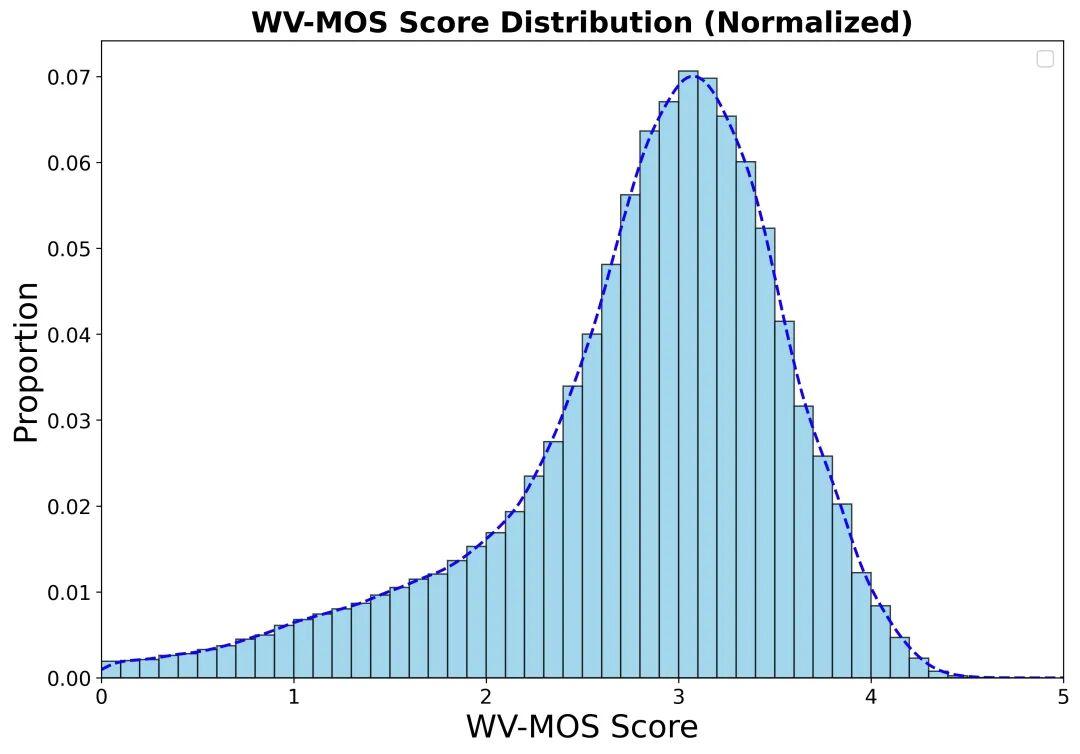
图3 音频质量WVMOS分数分布
WSC-Eval评估集
为了解决四川话ASR和TTS缺乏标准评估基准的问题,我们构建了WSC-Eval-ASR和WSC-Eval-TTS两个针对ASR和TTS的评估集,用于全面检验模型在处理四川方言上的表现。
ASR评估集:我们首先使用Chuan-Pipeline对来自多个领域的原始四川话数据进行预处理,然后我们再带领专业标注人员手动精标。所有音频样本均带有说话人属性标签,包括年龄、性别和情绪状态等。为了便于更细致地分析模型的性能,我们将总时长为9.7小时的数据进一步划分为“Easy”和“Hard”子集,依据来源领域和声学环境进行区分,从而实现更具层次的模型鲁棒性评估。详细统计信息见表2。

表2 WSC-Eval-ASR测试集
TTS评估集:WSC-Eval-TTS包含两个子集:WSC-Eval-TTS-easy由包含特定四川方言词汇的多领域短句组成;WSC-Eval-TTS-hard由长句和LLM生成的多风格四川方言长句组成,涵盖绕口令、民间俚语及富含感情的语句等风格。在音频提示方面,我们选取了来自MagicData及内部录音的10位说话人(5男5女),每人录制200个句子,确保性别、年龄和口音的多样性与平衡。
实 验
ASR部分
为验证所提出数据集的有效性,我们在三个测试集(WSC-Eval-ASR、MagicData-Conversation、MagicData-Daily-Use)上评估了多种 ASR 模型,涵盖专用识别系统(如 Paraformer、Whisper)及多模态大模型(如 Kimi-Audio、Qwen2.5-omni)。实验结果表明,开源模型 FireRedASR-AED 在多个评测集上表现稳定,平均字错误率为 15.14%,优于其他系统。通过在 WenetSpeech-Chuan 上微调 Paraformer 和 Qwen2.5-omni,整体性能分别提升 11.7% 与 11.02%。进一步结合 1000 小时高质量内部方言数据训练后,Paraformer 在各测试集上平均 CER 降至 13.38%,展现出出色的迁移与适应能力。总体来看,WenetSpeech-Chuan 显著增强了模型对四川方言的识别能力,同时不影响普通话性能。
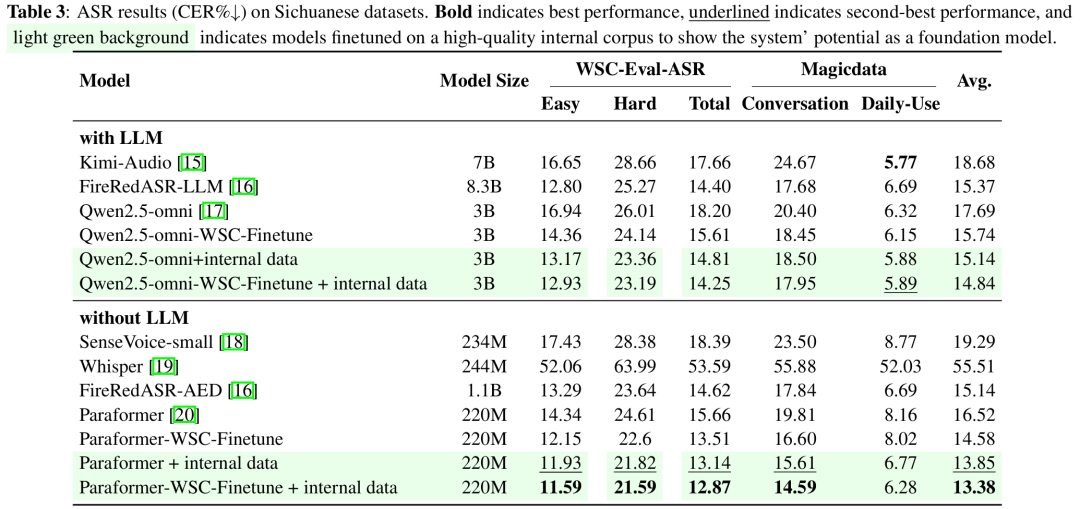
表3 ASR实验结果
TTS部分
我们将 CosyVoice2-WSC 与多个支持方言的 TTS 模型进行比较,包括 Step-Audio-TTS、CosyVoice2.0、Llasa-1B 和 Qwen-TTS。评估方法包括客观指标(字符错误率 CER、说话人相似度 SIM)和主观指标(可理解性 IMOS、说话人相似度 SMOS、方言自然度 AMOS)。AMOS 部分由 10 位四川本地人和 10 位非专业听众评分,共评估 30 条样本,覆盖不同说话人和任务难度。
结果显示,CosyVoice2-WSC 在主客观评估中均表现良好。在 easy 测试集中,其 CER 为 4.28%,接近 Qwen-TTS 的 4.13%,同时感知质量和说话人相似度更高;在 hard 测试集中,虽然 CER 稍高(8.78% 对比 7.35%),但仍保持较好的稳定性和相似度(SIM 超过 62%)。相比 Step-Audio-TTS 和原始 CosyVoice2,CosyVoice2-WSC 在准确率和听感之间取得更好平衡。
进一步微调后的 CosyVoice2-WSC-SFT 表现最优,在 easy 测试集中 CER 降至 4.08%,SIM 达 78.84%,主观评分领先;hard 集中 CER 降至 7.22%,AMOS 最佳,体现出微调对准确性和自然度的双重提升。
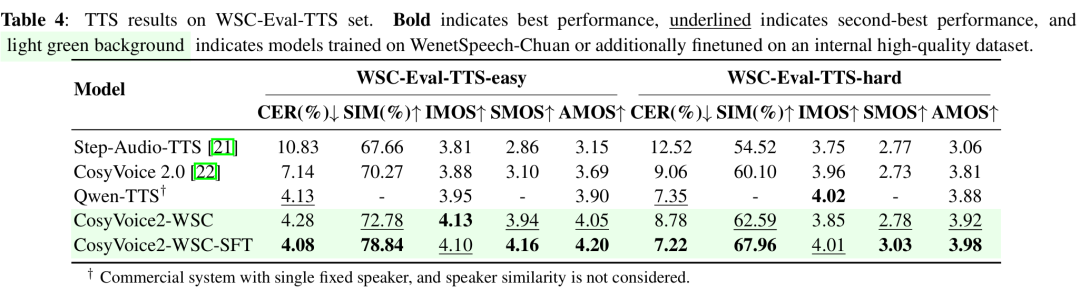
表4 TTS实验结果
希尔贝壳深耕语音数据技术,持续推进技术创新与开源生态体系建设。WenetSpeech-Chuan 数据集的开源,不仅是四川话语音技术研究的重要里程碑,更在AI语音生态构建进程中具有关键意义,为打造更为开放、多元的语音技术发展格局提供了坚实支撑。
参考文献
[1] Dana Serditova, Kevin Tang, and Jochen Steffens, “Automatic speech recognition biases in Newcastle English: an error analy sis,” CoRR, vol. abs/2506.16558, 2025.
[2] Aref Farhadipour, Homa Asadi, and Volker Dellwo, “Self supervised models in automatic whispered speech recognition,” CoRR, vol. abs/2407.21211, 2024.
[3] Nguyen Dinh, Thanh Dang, Luan Thanh Nguyen, and Kiet Van Nguyen, “Multi-dialect vietnamese: Task, dataset, baseline models and challenges,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP2024, Miami, FL, USA, November 12-16, 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, Eds. 2024, pp. 7476–7498, Association for Computational Linguistics.
[4] Abraham Toluwase Owodunni, Aditya Yadavalli, Chris Emezue, Tobi Olatunji, and Clinton Mbataku, “Accentfold: A journey through African accents for zero-shot ASR adaptation to target accents,” in Findings of the Association for Computational Linguistics: EACL 2024, St. Julian’s, Malta, March 17-22, 2024, Yvette Graham and Matthew Purver, Eds. 2024, pp. 2146–2161, Association for Computational Linguistics.
[5] Xuehao Zhou, Mingyang Zhang, Yi Zhou, Zhiwu Li, and Haizhou Li, “Multi-scale accent modeling with disentangling for multi-speaker multi-accent TTS synthesis,” CoRR, vol. abs/2406.10844, 2024.
[6] Jan Melechovsk´y, Ambuj Mehrish, Berrak Sisman, and Dorien Herremans, “DART: disentanglement of accent and speaker representation in multispeaker text-to-speech,” CoRR, vol. abs/2410.13342, 2024.
[7] Zhiyuan Tang, Dong Wang, Yanguang Xu, Jianwei Sun, Xiaoning Lei, Shuaijiang Zhao, Cheng Wen, Xingjun Tan, Chuandong Xie, Shuran Zhou, Rui Yan, Chenjia Lv, Yang Han, Wei Zou, and Xiangang Li, “Kespeech: An open source speech dataset of mandarin and its eight subdialects,” in Pro ceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Bench marks 2021, December 2021, virtual, Joaquin Vanschoren and Sai-Kit Yeung, Eds., 2021.
[8] Binbin Zhang, Hang Lv, Pengcheng Guo, Qijie Shao, Chao Yang, Lei Xie, Xin Xu, Hui Bu, Xiaoyu Chen, Chenchen Zeng, Di Wu, and Zhendong Peng, “WENETSPEECH: A 10000+ hours multi-domain Mandarin corpus for speech recognition,” in IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2022
[9] Longhao Li, Zhao Guo, Hongjie Chen, Yuhang Dai, Ziyu Zhang, Hongfei Xue, Tianlun Zuo, Chengyou Wang, Shuiyuan Wang, Jie Li, et al., “Wenetspeech-yue: A large-scale Cantonese speech corpus with multi-dimensional annotation,” arXiv preprint arXiv:2509.03959, 2025.
[10] Linhan Ma, Dake Guo, Kun Song, YuepengJiang, Shuai Wang, Liumeng Xue, Weiming Xu, Huan Zhao, Binbin Zhang, and Lei Xie, “Wenetspeech4tts: A 12,800-hour Mandarin TTS corpus for large speech generation model benchmark,” arXiv preprint arXiv:2406.05763, 2024.
[11] Hui Wang, Siqi Zheng, Yafeng Chen, Luyao Cheng, and Qian Chen, “Cam++: A fast and efficient network for speaker verification using context-aware masking,” arXiv preprint arXiv:2303.00332, 2023.

















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









