




 自ChatGPT引发人工智能浪潮,国内外科技巨头布局大模型领域。本文梳理了阿里、百度、字节等8家互联网科技公司2023年至今在AI领域的50款大模型及应用,如阿里的AtomoVideo、绘蛙,百度的文心系列,字节的SDXL - Lightning等,展示了各公司的AI技术动向。
自ChatGPT引发人工智能浪潮,国内外科技巨头布局大模型领域。本文梳理了阿里、百度、字节等8家互联网科技公司2023年至今在AI领域的50款大模型及应用,如阿里的AtomoVideo、绘蛙,百度的文心系列,字节的SDXL - Lightning等,展示了各公司的AI技术动向。

▎大模型战火持续一年多,一起来看百度、阿里等国内互联网大厂在AI领域的最新技术成果。
自美国OpenAI公司推出的ChatGPT风靡全球,并引发新一轮人工智能浪潮,国内外科技巨头争相布局大模型领域。
此次,钛媒体AGI梳理了2023年至今,阿里、百度、字节、腾讯、华为、小红书、美图、科大讯飞、三六零8家互联网科技公司在 AI 领域的最新技术成果,共计包含50款AI大模型及AI应用,以帮助读者快速了解互联网大厂在AI领域的最新技术动向。
阿里巴巴
2024年3月
中国版“Sora”,文生视频框架——AtomoVideo
产品介绍:AtomoVideo是阿里巴巴推出的一个高保真图像视频生成框架,该框架利用高质量的数据集和训练策略,保持了时间性、运动强度、一致性和稳定性,并具有高灵活性,可应用于长序列视频预测任务。
因与Open AI此前推出的文生视频模型Sora功能相似,AtomoVideo也被称为中国版“Sora”。
产品功能:用户只需上传一张照片就能生成对应的视频。据悉AtomoVideo的核心在于多粒度图像注入技术,这一技术使得生成的视频对于给定的图像具有更高的保真度,能够更好地保留原始图像的细节和特征,从而使得生成的视频更加逼真。

另外,AtomoVideo的架构也具有很高的灵活性,它可以灵活地扩展到视频帧预测任务,通过迭代生成实现长序列预测,使得AtomoVideo在处理长序列的视频预测任务时,也能够保持良好的性能。
目前,阿里只发布了AtomoVideo的论文,代码,试玩页面还未公布。
适用人群或场景:视频创作者、影视拍摄
论文地址:https://arxiv.org/abs/2403.01800
电商人的AIGC创作平台——绘蛙
产品介绍:绘蛙是阿里AI电商团队针对淘宝、电商达人推出的一款可以生成文案和图片的智能创作平台,旨在提升电商营销效率。
产品功能:主要是AI文案生成和AI图片生成。在AI文案中,商家可以实现单商品种草、小红书爆文改写、穿搭分享等。以爆文改写为例,商家只需输入参考笔记内容,然后添加种草商品卖点、人设、笔记话题,即可生成小红书风格文案。
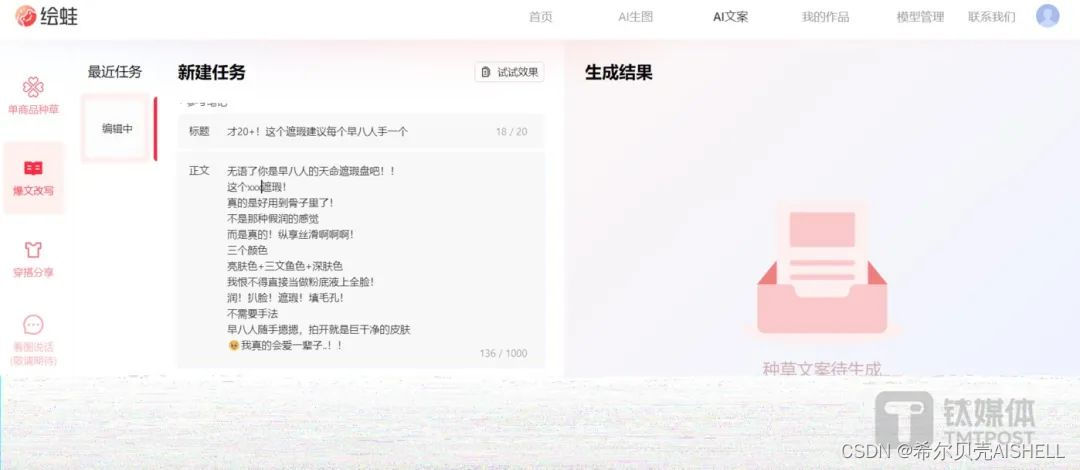
AI生图中,用户可以通过选择商品、选择模特和选择参考图生成自己想要的商品图片,支持自己上传模特图,也有自带的数字模特库可供使用,可以定制专属自己的AI模特,帮助商家节省商品拍摄和模特成本。
适用人群:淘宝、天猫店家、带货主播、电商达人
上线时间:未知
体验地址:https://www.ihuiwa.com/(需邀请码)
AI图片-音频-视频模型——EMO
产品介绍:EMO是阿里巴巴推出的AI图片-音频-视频模型,该模型采用了 Stable Diffusion 的生成能力和 Audio2Video 扩散模型,能够生成富有表现力的人像视频。
不同于 OpenAI 的文生视频模型 Sora,EMO 主攻的是直接以图+音频生成视频方向,能够直接从给定的图像和音频,剪辑生成一段带有丰富人物表情的人物头部视频。
产品功能:用户只需要上传一张照片和一段任意音频,EMO就可以根据图片和音频生成一段会说话唱歌的AI视频。视频中人物具备丰富流畅的面部表情,能做到人物开口说话和唱歌时和和音频保持一致,最长时间可达1分30秒左右。
比如,你可以上传一张高启强的照片+一段罗翔老师的音频,就能得到一段“高启强普法”视频。或者,你可以上传一张蒙娜丽莎的照片,让蒙娜丽莎给你唱现代歌曲,唱rap等。

适用人群:有演讲需求人群、电商主播、视频自媒体及讲师等
GitHub:https://github.com/HumanAIGC/EMO
论文地址:https://arxiv.org/abs/2402.17485
项目主页:https://humanaigc.github.io/emote-portrait-alive/
2024年1月
性能堪比Gemini Ultra的多模态大模型——Qwen-VL-Max
产品介绍:Qwen-VL是阿里推出的开源多模态视觉模型,2024年1月,继Plus版本之后,阿里又推出了Qwen-VL-Max版本。
产品功能:基础能力方面,Qwen-VL-Max能够准确描述和识别图片信息,并根据图片进行信息推理和扩展创作。这一特性使得该模型在多个权威测评中表现出色,整体性能堪比GPT-4V和Gemini Ultra。
视觉推理方面,Qwen-VL-Max可以理解并分析复杂的图片信息,包括识人、答题、创作和写代码等任务。同时该模型还具备视觉定位功能,可根据画面指定区域进行问答。
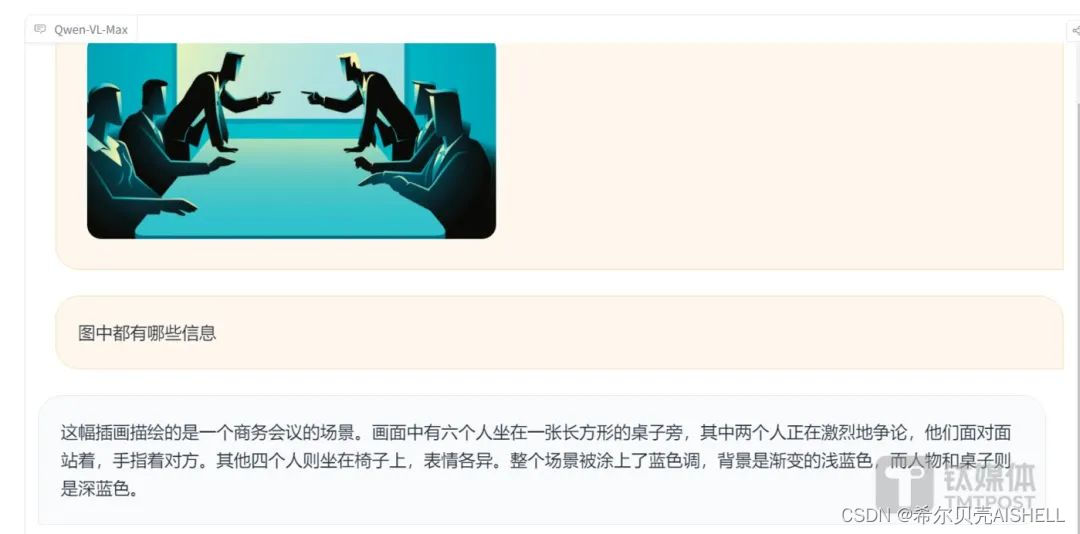
此外,Qwen-VL-Max在图像文本处理方面也取得了显著进步,中英文文本识别能力显著提高,支持百万像素以上的高清分辨率图和极端宽高比的图像,不仅能完整复现密集文本,还能从表格和文档中提取信息。
体验地址:https://huggingface.co/spaces/Qwen/Qwen-VL-Max
AI生成3D动画工具——Motionshop
产品介绍:Motionshop是阿里巴巴智能计算研究院推出的一个AI角色动画框架,该框架利用视频处理、角色检测/分割/追踪、姿态分析、模型提取和动画渲染等多种技术,使得动态视频中的主角能够轻松跨越现实与虚拟的界限,一键变身为3D
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









