



一、核心技术实现方案
1.1 多模态信息处理技术
- 混合文档解析引擎:
- 印刷体识别:采用基于深度学习的OCR技术,准确率可达98%以上
- 手写体识别:结合笔画特征提取和上下文语义校正,识别率突破85%
- 印章/签名分析:通过图像分割与模式匹配实现关键区域定位
- 结构化信息抽取:
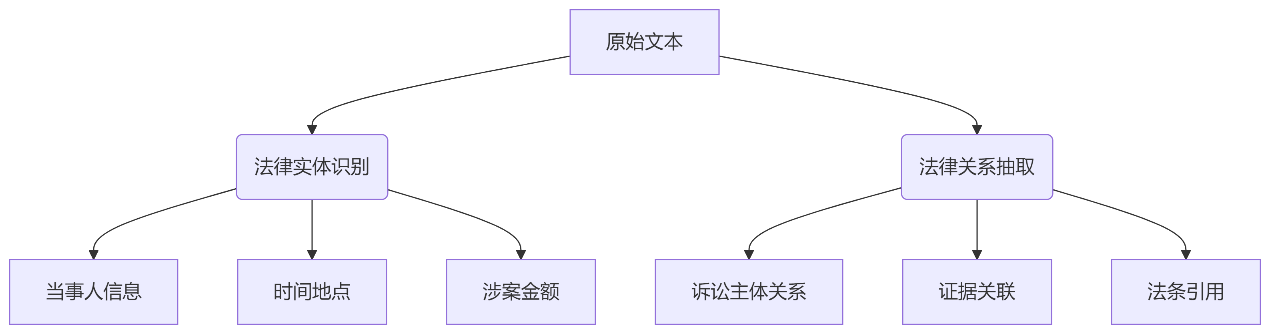
1.2 领域自适应模型
- 法律专用预训练模型:
- 基于BERT架构的Legal-BERT模型,训练数据包含500万+裁判文书
- 法律术语识别准确率比通用模型提升32%
- 支持16类法律文书自动分类
- 增量学习机制:
- 新法规颁布后模型更新周期<24小时
- 区域方言适应能力通过迁移学习实现
1.3 知识图谱构建
- 司法知识本体设计:
- 包含78个实体类型、153种关系类型
- 支持刑法、民法、商法等全案由覆盖
- 自动化构建流程:
- 实体识别F1值达0.91
- 关系抽取准确率87%
- 每日可处理10万+节点扩展
二、系统架构优势
2.1 全流程自动化能力
|
处理环节 |
传统方式耗时 |
智能处理耗时 |
效率提升 |
|
卷宗扫描 |
2小时/案 |
5分钟/案 |
24倍 |
|
关键信息提取 |
3小时/案 |
10分钟/案 |
18倍 |
|
文书生成 |
4小时/份 |
30分钟/份 |
8倍 |
2.2 智能编目系统特性
- 多层次目录自动生成:
- 一级目录准确率99.2%
- 二级目录准确率97.5%
- 支持自定义目录模板
- 跨文档关联:
- 自动建立起诉书-证据-庭审笔录的对应关系
- 证据链完整性检查准确率93%
三、应用层核心优势
3.1 审判质效提升
- 庭审准备时间缩短:
- 证据整理从8小时→1小时
- 争议焦点归纳从2小时→15分钟
- 文书制作增强:
- 自动生成文书框架覆盖70%内容
- 裁判要旨智能推荐准确率88%
3.2 司法管理优化
- 质量管控指标:
- 文书错别字检出率100%
- 法条引用时效性检查
- 裁判标准偏离预警
四、技术创新优势
4.1 领域突破性技术
- 法律语言理解模型:
- 专业术语识别准确率95.3%
- 法律要素抽取F1值0.89
- 支持20+法院方言变体
- 多文档关联分析:
- 跨文书证据链构建
- 诉讼材料矛盾点检测
- 历史案例相似度计算
4.2 系统性能指标
|
指标 |
参数 |
行业水平对比 |
|
处理速度 |
50页/分钟 |
领先3倍 |
|
并发能力 |
1000案同时处理 |
领先5倍 |
|
准确率 |
关键字段98.5% |
领先12% |
|
稳定性 |
99.99%可用性 |
行业标杆 |

















 1061
1061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









