







📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
Playwright 是微软开发的 Web应用 的 自动化测试框架 ,它可以弥补传统UI自动化框架selenium很多的不足,在目前众多的UI自动化测试工具中脱颖而出。所以,本文章给大家介绍这个UI自动化神器的安装使用和元素定位方法,如果还没有用过的同学可以赶紧get起来哦~!
1、playwright介绍:
Playwright 是由微软 2020年开发发布的一款新型自动化测试框架, 可以 UI自动化测试 和接口自动化测试 移动端的web仿真应用。Playwright 是基于 Node.js 语言开发的,而且不需要再重新下载一个浏览器驱动,相当于已经写好了,仅仅需要安装这个库即可。
官方中文文档:https://playwright.net.cn/python/docs/intro
相比于selenium的优势:
-
不用自己安装浏览器,也不用安装驱动,不用考虑驱动和浏览器的兼容性,更稳定且兼容性更好
-
内部自带等待机制 不用自己写太多的等待
-
自带很丰富的断言的方法
-
Playwright 通过使用浏览器的底层调试协议来进行操作,相比于 Selenium 和 pyppeteer,它具有更快的执行速度和更低的资源消耗
-
支持异步请求操作, 可以跨多个窗口操作 不相互影响 能实现相互隔离, 快速执行
-
支持屏幕录制功能:根据屏幕录制指定生成相关操作代码。
-
自带定位检测器:帮助我们做元素定位 ,也可以像selenium F12自己写元素定位,支持丰富的元素定位的方法
playwright的特色:
1)跨浏览器支持:包括 Chrome、Firefox 和 WebKit内核的浏览器。
2)跨平台:在 Windows、Linux 和 macOS 上进行本地或 CI 测试,无头或有头模式。
3)跨语言: 在 TypeScript、JavaScript、Python、.NET、Java 中使用 Playwright API
4)测试移动端:适用于 Android 的 Google Chrome 和 Mobile Safari 的原生移动模拟。
2、安装环境:
-
1)安装playwright: pip install playwright
-
2)安装浏览器驱动:
- playwright install : 会安装 Chromium、Firefox 和 WebKit 的浏览器二进制文件
-
也可以通过提供参数来安装特定浏览器 :playwright install webkit
-
playwright install --help 可以查看支持哪些浏览器
-
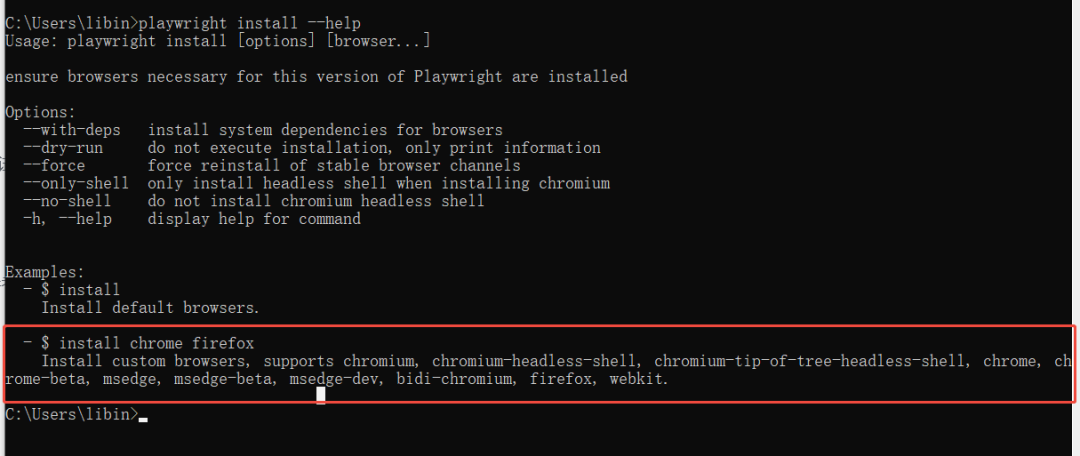
-
3)安装pytest插件: Playwright 推荐使用官方的 Playwright Pytest 插件来编写端到端测试。
- pip install pytest-playwright
3、playwright的元素定位
playwright的元素定位方法有很多,官方文档:https://playwright.net.cn/python/docs/locators
第一类:get_by_xx定位
1、 get_by_role: 通过角色方式定位元素,适用按钮、复选框、弹框等 ; 常用的参数有两个,第一个是角色名称 role,第二个是元素的文本 name 或者value的值
-
page.get_by_role("link", name="新闻").click() # 百度新闻链接
-
page.get_by_role("button",name="百度一下").click() #百度一下按钮
2、get_by_text: 通过元素的文本内容来查找元素,适用于链接文本、或者span标签中的文本等 ;包含两个参数,一个是 text标识定位的文本内容, 第二个是 exact 表示是否精确匹配;
-
默认是模糊匹配的,要精准匹配就加上参数exact=True;
-
page.get_by_text("百度一下",exact=True).click()
-
page.get_by_text("新闻", exact=True).click() #会自动忽略文本开头和结尾的空白字符
3、get_by_placeholder: 通过元素的 placeholder 属性来查找元素 ,也就是我们输入框的提示信息。他的参数和 get_by_text相同
-
exact=True:表示是否精确匹配
-
page.get_by_placeholder("请输入邮箱/手机号/账号").fill("tricy") #课堂派的用户名输入框
还有很多其他的定位,但是这种定位方法了解即可, 我们只需要使用第二种定位器locator,因为可以实现一切元素定位。

第二类:locator定位器,重点掌握,后面只需要用这个
这个locator方法返回的是一个locator定位器对象 【不是selenium的element对象】:这个locator对象 支持各种操作方法,通过locator定位器来找元素 :
-
1)id属性定位: page.locator("id=kw").fill("柠檬班")
-
2)元素指定属性定位:page.locator("[attribute=value]")
- page.locator("[name=wd]").fill("柠檬班")
-
page.locator("[class=s_ipt]").fill("柠檬班")
-
-
3)CSS selector定位
-
4)Xpath定位
对css和xpath后面可以自动识别xpath和css selector的表达式;我们先来学习一下css和xpath定位方法:
-
xpath定位(相对) :万能,推荐使用,重点学习。
-
css selector:有弊端,不能支持文本定位,但是xpath可以。而且只支持web页面,app不支持。所以,不如xpath用的多。
1)css选择器元素定位 --了解
1、根据ID定位:两种写法都可以
page.locator("#kw").fill("柠檬班")
2、根据className定位: 可以支持多个样式一起写
page.locator(".s_ipt").fill("python") # 百度搜索框
page.locator(".s-top-right-text.c-font-normal.c-color-t.s-top-right-new").click() #百度设置按钮
3、单属性选择定位: 需要其他的属性一起定位,可以用标签[属性名=“属性值”]
page.locator("input[name='wd']").fill("python") # 百度搜索框
4、多属性选择定位: 如果一个属性不能唯一定位,用个属性组合
page.locator("input[name='wd'][id='kw']").fill("python")
2)xpath元素定位:支持web页面+App页+小程序 ,高级强大,重点学习。属性 +文本+组合方式灵活。
-
xpath其实就是一个path(路径),一个描述页面元素位置信息的路径,相当于元素的坐标
-
xpath基于XML文档树状结构,是XML路径语言,用来查询xml文档中的节点
-
既可以用于XML,也可以用于HTML(因为XML与HTML结构类似,所以xpath都可以解析)
绝对路径:从根节点开始,一层一层写出来,直到要找到元素。父/子 路径和位置都涵盖了,所以特别不稳定。
-
从根节点(/)开始,一层一层写出来,直到要找到元素。父/子 【路径和位置依赖】
-
copy xpath :/html/body/div[2]/div[2]/div/div[1]/div[2]/ul/li[1]/a[2] -- 9代单传的路径。
相对路径: 以//开头,相对于某个节点的路径来找通过条件在html里面找。
-
在页面当中查看xpath表达式,可以匹配多少元素:F12 -- ctrl + F
1、第一种写法:
-
//元素标签名称[@属性=值] # 属性值是不变的。 == 区分一下css选择器,不管是什么属性都是@
-
//元素标签名称[text()=值] # 文本是不变的。
page.locator('//input[@id="kw"]')
2、第二种写法:and or 来组合多个属性和文本 //元[@属性素标签名称=值 and @属性=值 and text()=值]
page.locator('//input[@id="su" and @type="submit"]')
3、第三种方法:contains(text(), 包含的内容) contains(@属性名, 包含的内容)
-
什么情况下去使用:当你的文本/属性的值过长的情况,可以通过它来简化表达式
- 注意:写被包含的部分的时候,这部分内容必须是原始值连续的一段字串,不能是间隔的。
-
属性包含匹配 + 文本包含匹配
page.locator('//标签名[contains(@属性名,'值')]')
4、层级定位: 按照html页面顺序 从上到下定位,//...//...//
-
page.locator('//nav[@class="nav-tabs"]//a[@class="nav__item"]')
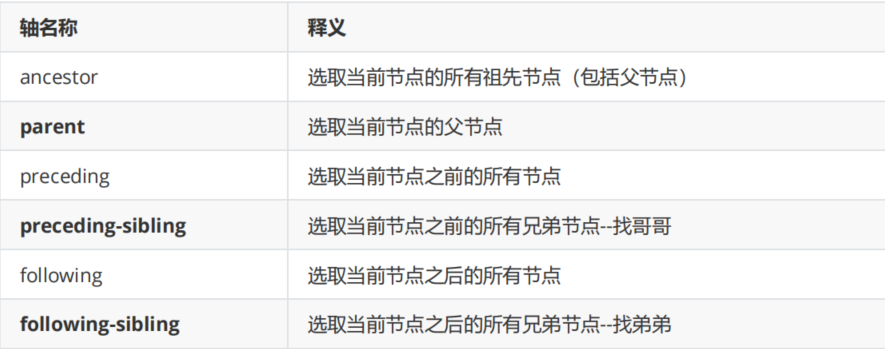
5、轴定位:如果元素之间有父子关系(儿子找爸爸)、兄弟关系(找哥哥/找弟弟),可以用轴定位
-
从子孙元素,倒着找父元素或者祖先元素。
-
从兄弟姐妹元素,顺着关系找到其它的兄弟姐妹。
- 关系疏理:要找的元素,是已知元素的 xxx 关系。
-
以下6个轴定位,重点关注标黑的三个:
- 语法 : //已找到的元素/轴定位名称::元素名称[....]
案例:
page.locator('//span[text()="Tom"]/ancestor::td/following-sibling::td//span[text()="私信 "]')
总 结
在本文章中,我们详细介绍了Playwright框架,并与Selenium进行了比较。介绍了安装配置流程,并通过实战项目展示了其强大元素定位的能力。
通过比较Playwright和Selenium,我们可以看到Playwright在自动化测试领域的优势。其跨浏览器和跨平台的特性,以及对现代Web技术的全面支持,使其成为开发人员和测试人员的首选。
我们鼓励读者在实际项目中尝试使用Playwright框架,体验其简洁的API和出色的性能。无论您是开发人员、测试人员还是质量保证专家,Playwright都将成为您工作中的得力助手。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



















 2915
2915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









