







📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
EasyOCR是一个基于深度学习的开源OCR(光学字符识别)库,由Jaided AI开发。
EasyOCR的整体架构基于PyTorch实现,它采用CRAFT算法进行文字检测,结合CRNN模型进行文字识别。
EasyOCR 的核心特性和功能有支持超过80种语言、高精度识别、GPU加速、易于安装和使用、灵活的输入格式、自定义输出、开源免费。
EasyOCR的这些特性使其成为一个功能强大且易于使用的OCR工具,适用于文档处理、自动化测试、图像分析和无障碍阅读等多种应用场景。
EasyOCR 在UI测试中的应用场景
在 UI 自动化测试中,EasyOCR作为文本内容断言、元素属性断言等的补充,以提供更全面的测试覆盖。
EasyOCR在UI自动化测试中的应用主要体现在以下几个方面:
界面元素验证:
在UI自动化测试中,EasyOCR可以用来识别和验证界面上的文本元素是否符合预期。
通过截图获取应用界面的图像,然后使用EasyOCR进行OCR识别,提取出图像中的文字,并与预期的文字进行比较,从而自动化地验证界面显示是否正确。
提高测试效率:
传统的UI测试可能需要手动比对界面上的文本,这既耗时又容易出错。
EasyOCR通过自动化的OCR识别,可以快速准确地识别图像中的文字,大大提高了测试的效率和准确性。
处理复杂场景:
EasyOCR基于深度学习模型,即使在面对模糊、倾斜、遮挡等复杂场景时,也能保持较高的识别准确率,这使得它在自动化测试中非常实用。
文本检测功能:
除了文本识别外,EasyOCR还具备文本检测功能,能够定位图像中的文本框,并返回文本框的坐标信息,这对于后续的处理如文本提取、排版分析等非常有用。
易用性:
EasyOCR提供了简洁易用的API,开发者可以轻松地将其集成到自己的自动化测试项目中。
同时,它也支持多种图像格式,如JPEG、PNG等,这使得在不同测试场景下都能灵活使用。
多语言支持:
EasyOCR支持超过80种语言的文字识别,这使得它在国际化的UI自动化测试中非常有用,可以处理多种语言的界面文本。
通过上述功能,EasyOCR成为了UI自动化测试中一个强大的工具,帮助测试人员提高测试的自动化水平和效率。下面我们就来体验EasyOCR的魅力。
EasyOCR 安装
你可以通过Python的包管理器 pip 来安装 EasyOCR:
pip install easyocr接下来是下载文本检测模型和语言模型。如果模型不存在,EasyOCR 会在第一次运行时自动下载文本检测模型和所需的语言模型。
不过由于某些原因,自动下载可能会失败,所以需要大家提前下载所需的语言模型。
手动下载的方式是进入语言模型下载中心:
https://www.jaided.ai/easyocr/modelhub/
找到文本检测模型并进行下载:

然后是下载识别模型,不同的语言有对应的识别模型,如下图标注出了英文和简体中文的识别模型:

也可在百度网盘进行下载:
https://pan.baidu.com/s/1NTnpmzud2gNol1gnFPrLgw?pwd=redx
提取码:redx
下载后会得到对应的zip包,然后解压。
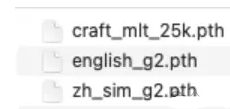
之后便会得到对应的 PTH 文件,如下图所示。
-
craft_mlt_25k.pth 为文本检测模型文件;
-
english_g2.pth 为英文的识别模型文件;
-
zh_sim_g2.pth 为简体中文的识别模型文件。
将得到的 PTH 文件被放置在EasyOCR指定的模型目录下,通常是在用户的主目录下的.EasyOCR/model文件夹中。
例如,在Windows系统中,路径可能是 C:\Users\<当前电脑用户>\.EasyOCR\model。
EasyOCR 使用
下面看一个简单的示例。我们来识别一张百度首页的图片,如下图所示。

EasyOCR 使用起来很简单,先实例化一个Reader对象,然后使用readtext()方法读取图片,最后将结果输出。
import easyocr
# 创建一个EasyOCR的Reader对象
reader = easyocr.Reader(['en', 'ch_sim'], gpu=False)
# 读取一张图片并识别文本
result = reader.readtext('baidu.png')
# 打印识别结果
for (bbox, text, prob) in result:
print(f"Detected {text} with probability {prob}")如果一切正常,EasyOCR将输出图片中的文本及其置信度。
运行上面代码后,结果输出如下:
Using CPU. Note: This module is much faster with a GPU.
Detected Baidw百度 with probability 0.061702461704590796
Detected 百度-下 with probability 0.9840897917747498从输出结果中可以看到:识别出了两部分文字,符合预期。其中LOGO内容识别值为“Baidw百度”, u 识别成了 w,有误差,其置信度是 0.06;按钮文字识别值为“百度-下”,其置信度是 0.98。
可以看到,置信度越高,准确性也就越高。
了解了简单的使用,下面介绍创建Reader()实例时常用的参数及readtext()方法文字识别后返回的数据。
创建Reader()实例时常用的参数有:
lang_list (list):
EasyOCR在分析图像时应该识别哪些语言的文字,例如,['en']代表英语,['ch_sim']代表简体中文。
gpu (bool):
用于启用或禁用GPU支持,默认值是 True。
model_storage_directory (string):
指定模型数据的存储路径。
如果未指定,EasyOCR会按照环境变量EASYOCR_MODULE_PATH指定的路径、环境变量MODULE_PATH指定的路径、默认路径~/.EasyOCR/(当前用户的主目录下的.EasyOCR文件夹)顺序依次查找模型。
user_network_directory (string):
指定自定义网络的存储路径。
如果未指定,EasyOCR会按照环境变量EASYOCR_MODULE_PATH指定的路径、环境变量MODULE_PATH指定的路径、默认路径~/.EasyOCR/(当前用户的主目录下的.EasyOCR文件夹)顺序依次查找模型。
download_enabled (bool):
用于启用或禁用通过HTTP下载模型数据的功能。
默认值为True,如果没有本地模型文件,EasyOCR会自动尝试从网络上下载所需的模型数据。
detector (bool) :
是否加载检测模型,默认值是 True。
recognizer (bool) :是否加载识别模型,默认值是 True。
readtext()返回的数据:
-
默认输出是一个列表,其中每个元素代表图像中检测到的一段文本及其相关信息。依次是边界框、文本和置信度。边界框是一个包含四个整数的列表,表示检测到的文本区域在图像中的坐标位置。
坐标通常是[x_min, y_min, x_max, y_max]的形式,其中(x_min, y_min)是文本区域左上角的坐标,(x_max, y_max)是文本区域右下角的坐标;文本是识别出的文本字符串;置信度是一个介于0和1之间的浮点数,表示模型对识别结果的置信程度。
值越接近1,表示置信度越高。
result = reader.readtext('baidu.png') print(result) # 输出结果 # [([[236, 64], [456, 64], [456, 112], [236, 112]], 'Baidw百度', 0.061702461704590796), ([[582, 144], [656, 144], [656, 170], [582, 170]], '百度-下', 0.9840897917747498)] -
添加 detail=0 参数,可只输出识别出来的文本列表。
result = reader.readtext('baidu.png', detail=0) print(result) # 输出结果 # ['Baidw百度', '百度-下'] -
输出 json 或 字典格式数据。
添加
output_format= 'dict' 或 output_format= 'json' 参数,可以以 json 或 字典格式将结果输出。
result = reader.readtext('baidu.png', output_format='json')
print(result)
# 输出结果
# ['{"boxes": [[236, 64], [456, 64], [456, 112], [236, 112]], "text": "Baidw百度", "confident": 0.061702461704590796}', '{"boxes": [[582, 144], [656, 144], [656, 170], [582, 170]], "text": "百度-下", "confident": 0.9840897917747498}']
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】




















 4106
4106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









