




 本文通过一个趣味案例介绍了如何利用数据探索、聚类算法(K-Means)进行“脱单”匹配,展示了数据分析在个人生活中的应用。作者首先进行数据清洗与初步探索,接着选择无监督的聚类模型来划分潜在对象,通过K-Means算法不断迭代寻找最佳类别。最后,作者强调了沟通与自我包装的重要性,并分享了实际约会中运用数据分析的趣事。
本文通过一个趣味案例介绍了如何利用数据探索、聚类算法(K-Means)进行“脱单”匹配,展示了数据分析在个人生活中的应用。作者首先进行数据清洗与初步探索,接着选择无监督的聚类模型来划分潜在对象,通过K-Means算法不断迭代寻找最佳类别。最后,作者强调了沟通与自我包装的重要性,并分享了实际约会中运用数据分析的趣事。

本文由公众号 AIU人工智能出品,转载自行咨询原创者授权
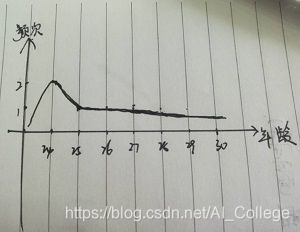
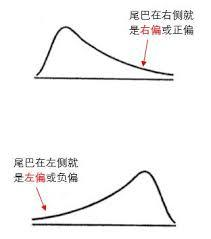
Hello大家好,上回讲到数据清洗工作已经完成,在建立模型之前,我想看看这些数据的大致情况,专业一点的说法叫做数据探索,就是对已有数据集的一个了解。最简单的探索,看看最大值、最小值、方差、均值、中位数这些,当然,这主要是针对年龄这种数值型的数据,由于之前清洗数据的时候,已经对年龄的上下限做出来限制,所以最大值最小值都在预期之内,至于均值和中位数,可能很多人搞不太清这两者的区别。 大多数人对均值比较熟悉,上学的时候用的也比较多,下边我们可以举个例子来区分探索一下,比如说有5个姑娘,年龄分别是24岁,24岁,28岁,29岁,30岁,那么她们的平均年龄是27岁,而年龄的中位数很明显是28岁,两者并不相同,画一个分布图的话,能明显看出是一个右偏分布,如果扩展到数据量更大的数据集里,画出分布是右偏分布,就能得出这样一个结论,这样一批妹子中间,年纪稍大一点的妹子占多数。如果我比较喜欢御姐型的妹子,我可能已经在偷着乐了,年纪稍大的妹子多一点,御姐就可能会多一点啊,哈哈哈……当然,这只是假设还有概率,还不能这么开心的笑! (你的好友灵魂画手已上线)
好啦,清洗和简单的探索做完了,下面该建立一个模型来做进一步的分析,挑选出哪些妹子才是和我比较搭的。这里稍稍有点纠结,是做个分类呢还是做个聚类呢?虽然这两类模型从名字上看差不多,但是实际上差别可大着呢,分类模型是有监督的模型,提前已经知道了有几类,每个类有哪些特征。而聚类一般是无监督模型,提前并不知道有几类,需要根据每条数据的特征来寻找数据间的相似性,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3207
3207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









