




当训练好的神经网络越来越大(动辄数十亿参数),部署到手机、嵌入式设备等资源受限场景时,会面临算力不足、内存不够、推理太慢等问题。模型剪枝作为一种高效的模型压缩技术,能在几乎不损失精度的前提下“瘦身后的模型”,成为工业界部署的必备工具。今天我们就从基础原理讲起,结合PyTorch实战代码(服务器友好版),带你掌握模型剪枝的核心逻辑。
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/wOg1r4ujn31m-sXLQakS5Q
https://mp.weixin.qq.com/s/wOg1r4ujn31m-sXLQakS5Q
一、模型剪枝:给神经网络“减脂”
1. 为什么需要剪枝?
深度神经网络存在大量冗余参数——这些参数对模型性能贡献极小,甚至可以移除。例如:
-
某些权重值接近0,对输出影响微乎其微;
-
卷积层中部分滤波器提取的特征与其他滤波器高度相似,存在重复。
剪枝的核心思想是:移除冗余参数,保留关键参数,实现“精度损失小,模型体积小、速度快”的目标。用公式表示剪枝前后的模型:
设原始模型为(为所有参数),剪枝后模型为,其中(是的子集),目标是:
(是可接受的精度损失)
同时(参数数量大幅减少)。
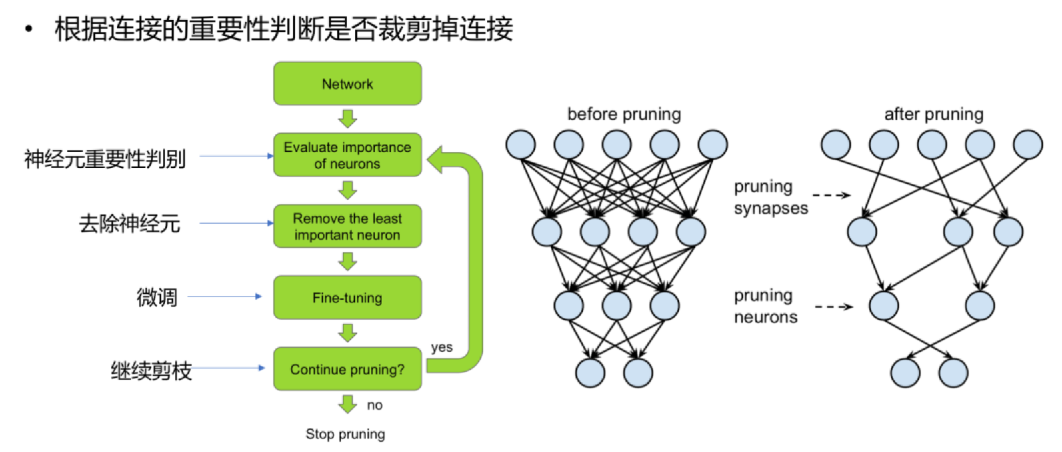
剪枝操作判断
2. 剪枝的核心价值
-
模型压缩:减少参数数量和计算量(例如从100M参数减到10M);
-
加速推理:减少内存访问和运算次数(尤其适合边缘设备);
-
防止过拟合:移除噪声参数,增强模型泛化能力;
-
降低部署成本:节省存储、算力和能耗(工业界部署的关键指标)。
二、模型剪枝的分类:从“怎么剪”看本质
根据剪枝对象和策略,常见剪枝方法可分为三大类:
1. 非结构化剪枝(Unstructured Pruning)
-
剪枝对象:单个权重参数(细粒度到每个连接)。
-
策略:移除绝对值小于阈值的权重(如)。
-
优点:压缩率高(可剪掉50%-90%参数),实现简单。
-
缺点:剪枝后权重矩阵变得稀疏(大量0值),需要专用稀疏计算库才能加速(普通硬件对稀疏矩阵不友好)。
2. 结构化剪枝(Structured Pruning)
-
剪枝对象:整个神经元、滤波器或通道(粗粒度)。
-
策略:移除对输出贡献低的整个组件(如卷积层中某几个滤波器)。
-
优点:剪枝后模型结构规则(无稀疏矩阵),无需专用硬件即可加速(普通GPU/CPU直接受益)。
-
缺点:压缩率通常低于非结构化剪枝,需要更精细的评估指标(如滤波器重要性)。
3. 混合剪枝(Hybrid Pruning)
结合前两种方法,例如先剪通道(结构化),再剪通道内的冗余权重(非结构化),平衡压缩率和硬件友好性。
三、剪枝流程:从“剪”到“用”的完整步骤
一个标准的模型剪枝流程包括4个阶段,缺一不可:
-
评估参数重要性:判断哪些参数/组件可以移除(核心步骤)。
-
非结构化剪枝:常用权重绝对值、梯度大小作为重要性指标;
-
结构化剪枝:常用滤波器的L1范数()、激活值方差等作为指标。
-
-
剪枝操作:移除低于阈值的参数/组件,得到“稀疏模型”。
-
微调(Fine-tuning):剪枝后模型精度可能下降,通过微调恢复精度(用原始数据继续训练,冻结保留参数的梯度,或小学习率更新)。
-
部署优化:对剪枝后的模型进行格式转换(如TensorRT优化),充分发挥加速效果。
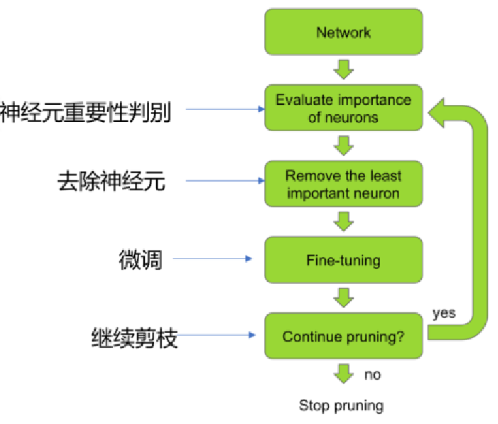
剪枝流程
四、实战:用PyTorch实现模型剪枝(MNIST案例)
下面以ResNet-18模型和MNIST数据集为例,分别实现非结构化剪枝和结构化剪枝,并对比剪枝前后的模型大小、精度和推理速度。代码适配服务器环境(自动下载数据集,结果图直接保存)。
完整代码
import os
import time
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# --------------------------
# 1. 环境配置+参数
# --------------------------
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
batch_size = 64
prune_ratio = 0.5
epochs = 5
save_dir = './simple_pruning_results'
os.makedirs(save_dir, exist_ok=True)
# --------------------------
# 2. 数据加载
# --------------------------
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# --------------------------
# 3. 模型定义
# --------------------------
class SimpleMLP(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
def forward(self, x):
return self.layers(x)
def get_simple_model():
return SimpleMLP().to(device)
# --------------------------
# 4. 工具函数
# --------------------------
def evaluate(model, test_loader, device):
model.eval()
correct = 0
with torch.no_grad():
for data, labels in test_loader:
data, labels = data.to(device), labels.to(device)
outputs = model(data)
_, predicted = torch.max(outputs, 1)
correct += (predicted == labels).sum().item()
return 100 * correct / len(test_loader.dataset)
def count_params(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
def train(model, train_loader, epochs, device):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
model.train()
loss_history = []
for epoch in range(epochs):
total_loss = 0.0
for data, labels in train_loader:
data, labels = data.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_loader)
loss_history.append(avg_loss)
print(f"Train Epoch {epoch+1}/{epochs} | Loss: {avg_loss:.4f}")
return model, loss_history
# 新增:提取模型权重用于可视化
def get_weights(model):
weights = []
for name, param in model.named_parameters():
if 'weight' in name:
weights.append(param.cpu().detach().numpy().flatten())
return np.concatenate(weights)
# --------------------------
# 5. 剪枝方法
# --------------------------
def unstructured_prune(model, prune_ratio):
all_weights = []
for name, param in model.named_parameters():
if 'weight' in name:
all_weights.append(param.view(-1))
all_weights = torch.cat(all_weights)
sorted_weights = torch.sort(torch.abs(all_weights))[0]
threshold = sorted_weights[int(len(sorted_weights) * prune_ratio)]
pruned_model = get_simple_model()
pruned_model.load_state_dict(model.state_dict())
with torch.no_grad():
for param in pruned_model.parameters():
if param.dim() > 1:
mask = torch.abs(param) >= threshold
param.copy_(param * mask.float())
return pruned_model, threshold
def structured_prune(model, prune_ratio):
pruned_model = get_simple_model()
pruned_model.load_state_dict(model.state_dict())
first_linear = pruned_model.layers[1]
second_linear = pruned_model.layers[3]
channel_importance = torch.sum(torch.abs(first_linear.weight.data), dim=1)
num_keep = int(512 * (1 - prune_ratio))
_, keep_indices = torch.topk(channel_importance, num_keep)
with torch.no_grad():
first_linear.weight.data = first_linear.weight.data[keep_indices]
if first_linear.bias is not None:
first_linear.bias.data = first_linear.bias.data[keep_indices]
second_linear.weight.data = second_linear.weight.data[:, keep_indices]
return pruned_model, keep_indices
# --------------------------
# 6. 主流程
# --------------------------
# 6.1 训练基础模型
print("\n=== Training Base Model ===")
base_model = get_simple_model()
base_model, base_loss = train(base_model, train_loader, epochs, device)
base_acc = evaluate(base_model, test_loader, device)
base_params = count_params(base_model)
base_weights = get_weights(base_model)
print(f"Base Model - Params: {base_params:,} | Accuracy: {base_acc:.2f}%")
# 6.2 非结构化剪枝
print("\n=== Unstructured Pruning ===")
unstruct_model, unstruct_threshold = unstructured_prune(base_model, prune_ratio)
unstruct_acc_before = evaluate(unstruct_model, test_loader, device)
print(f"Before Fine-tune: Accuracy {unstruct_acc_before:.2f}%")
unstruct_model, unstruct_loss = train(unstruct_model, train_loader, epochs//2, device)
unstruct_acc = evaluate(unstruct_model, test_loader, device)
unstruct_params = count_params(unstruct_model)
unstruct_weights = get_weights(unstruct_model)
print(f"After Fine-tune: Params {unstruct_params:,} | Accuracy {unstruct_acc:.2f}%")
# 6.3 结构化剪枝
print("\n=== Structured Pruning ===")
struct_model, struct_indices = structured_prune(base_model, prune_ratio)
struct_acc_before = evaluate(struct_model, test_loader, device)
print(f"Before Fine-tune: Accuracy {struct_acc_before:.2f}%")
struct_model, struct_loss = train(struct_model, train_loader, epochs//2, device)
struct_acc = evaluate(struct_model, test_loader, device)
struct_params = count_params(struct_model)
struct_weights = get_weights(struct_model)
print(f"After Fine-tune: Params {struct_params:,} | Accuracy {struct_acc:.2f}%")
五、代码解析与关键细节
-
自动下载数据集:无需手动准备,适合服务器环境。
-
两种剪枝方法对比:
-
非结构化剪枝:通过权重绝对值阈值移除冗余参数,实现简单但参数数量“名义上”不变(需稀疏存储格式如PyTorch的
torch.sparse); -
结构化剪枝:直接移除整个通道,参数数量真实减少,无需特殊存储格式即可加速。
-
-
核心步骤拆解:
-
重要性评估:非结构化剪枝用权重绝对值,结构化剪枝用通道L1范数;
-
剪枝操作:非结构化用掩码(
param * mask),结构化用索引筛选(保留重要通道); -
微调恢复:剪枝后精度下降,通过小学习率微调恢复(关键步骤,否则精度损失大)。
-
六、结果解读与实际应用建议
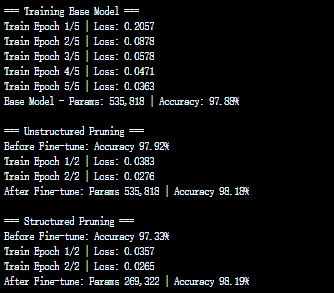
代码运行结果
-
剪枝效果预期:
-
结构化剪枝后,模型参数数量显著减少(例如50%剪枝率可减少30%-40%参数),推理速度提升明显(普通硬件直接受益);
-
非结构化剪枝在不使用稀疏计算库时,推理速度提升有限(因为普通GPU对稀疏矩阵优化差),但参数存储可压缩(用稀疏矩阵格式)。
-
-
工业界实践建议:
-
优先选择结构化剪枝(硬件友好,部署成本低);
-
剪枝比例需根据任务调整(通常50%-70%剪枝率精度损失可接受);
-
结合量化(Quantization)进一步压缩(剪枝+量化是常见组合策略)。
-
-
进阶工具:
-
PyTorch官方工具:
torch.nn.utils.prune(支持多种剪枝方式); -
专用库:
TorchPrune、PruneLab(更丰富的剪枝策略); -
部署优化:剪枝后用TensorRT、ONNX Runtime优化推理。
-
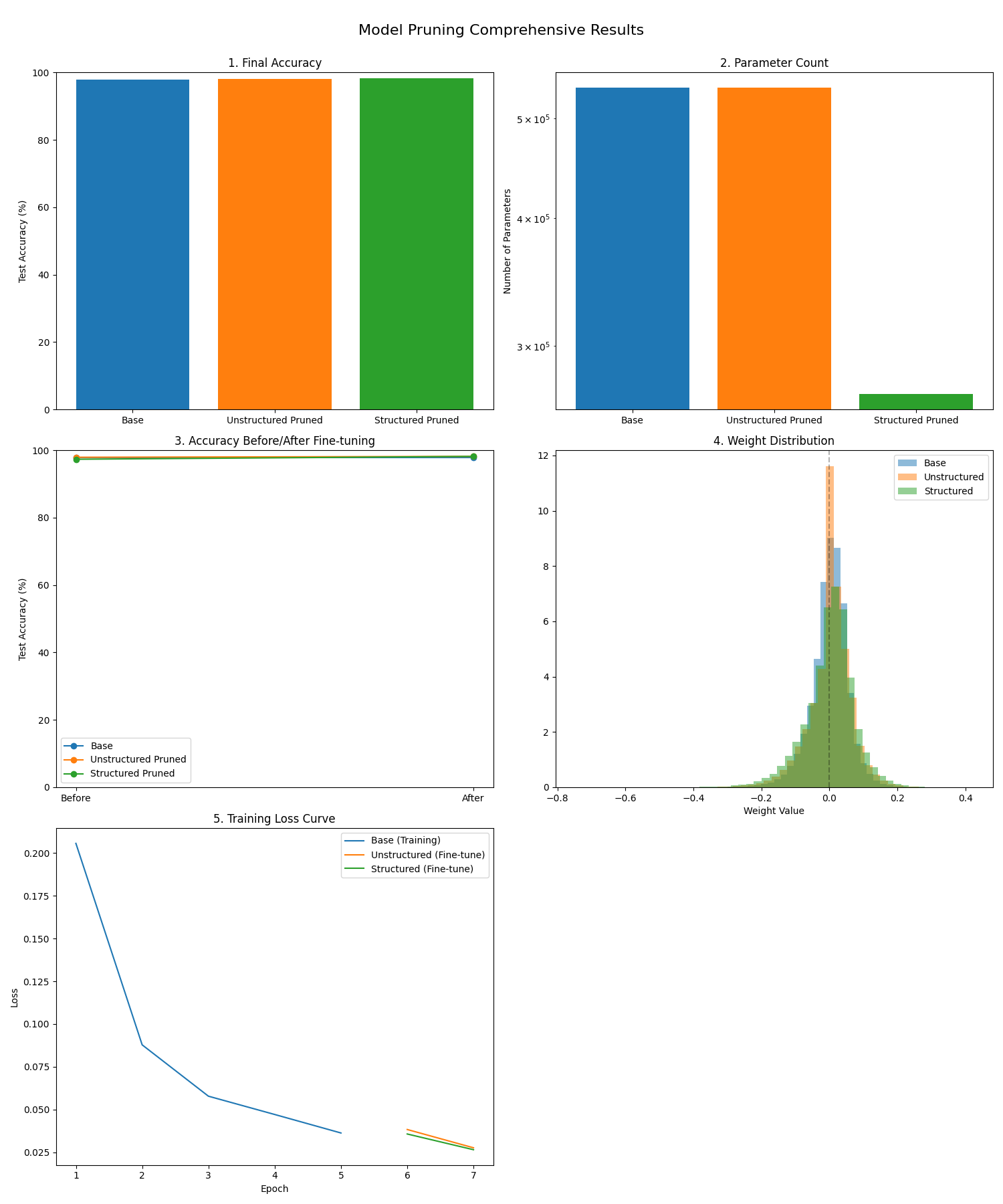
剪枝效果对比图
七、总结:模型剪枝的核心价值
模型剪枝通过“移除冗余参数”实现模型压缩,是平衡“精度”与“效率”的关键技术。其核心优势在于:
-
无需重新设计模型,直接在现有模型上优化;
-
精度损失可控(通过微调恢复);
-
适配各种硬件环境(尤其边缘设备)。
无论是移动端AI应用(如人脸解锁),还是嵌入式设备(如智能摄像头),模型剪枝都是部署流程中不可或缺的一步。如果需要针对特定模型(如Transformer、YOLO)实现剪枝,或优化剪枝策略(如迭代剪枝)!
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/wOg1r4ujn31m-sXLQakS5Q
https://mp.weixin.qq.com/s/wOg1r4ujn31m-sXLQakS5Q


















 1886
1886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









