




你是否曾经好奇, 抖音、小红书是如何精准推荐你喜欢的内容?手机相册又如何自动识别并分类照片?这些功能的背后,都离不开机器学习的两大核心范式:监督学习和无监督学习。
今天,我们就用最易懂的方式,为你解读这两个关键概念。
另外,我还整理了相关资料,需要的话可以分享给你
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/bGUwk1i1bnz1Qh-Asgux4g
https://mp.weixin.qq.com/s/bGUwk1i1bnz1Qh-Asgux4g
一、监督学习:像“老师教学生”一样的学习
核心思想:
提供“带答案”的数据,让机器学习规律,从而对新数据做出预测。
举个例子 🌰:
想象你要预测房价。你收集了一批历史数据,包括:
-
房屋面积(输入特征)
-
实际售价(输出标签)
你朋友的房子是750平方英尺,想请你估个价。通过分析已有数据,算法可以拟合出一条趋势线(模型),从而预测出他房子的可能售价。
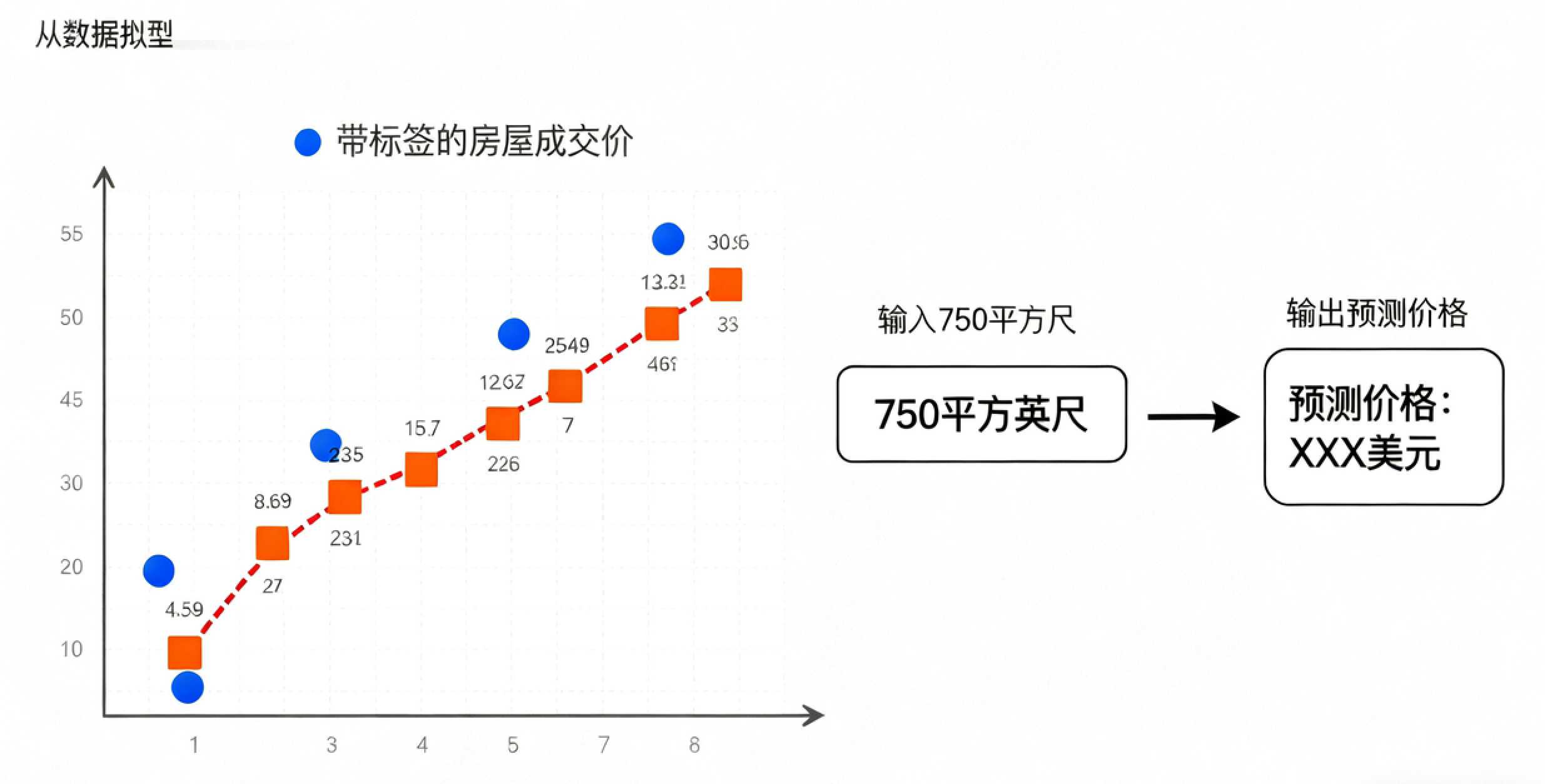
两种典型任务:
-
回归(Regression):预测连续值 → 比如:房价、销量、温度
-
分类(Classification):预测离散类别 → 比如:判断肿瘤是良性还是恶性、判断邮件是否是垃圾邮件
常见应用:
-
人脸识别
-
医疗诊断
-
股价预测
-
垃圾邮件过滤
二、无监督学习:像“自学成才”的探索
核心思想:
不给算法“答案”,只提供数据,让它自己发现内在结构或模式。
举个例子 🌰:
假设你有一堆新闻文章,但没有分类标签。无监督学习算法可以自动将这些文章按主题聚类(比如体育、科技、财经),就像谷歌新闻做的那样。
再比如,在基因研究中,算法可以通过分析DNA数据,自动将人群分为不同的亚型,而研究人员事先并不知道有哪些类别。
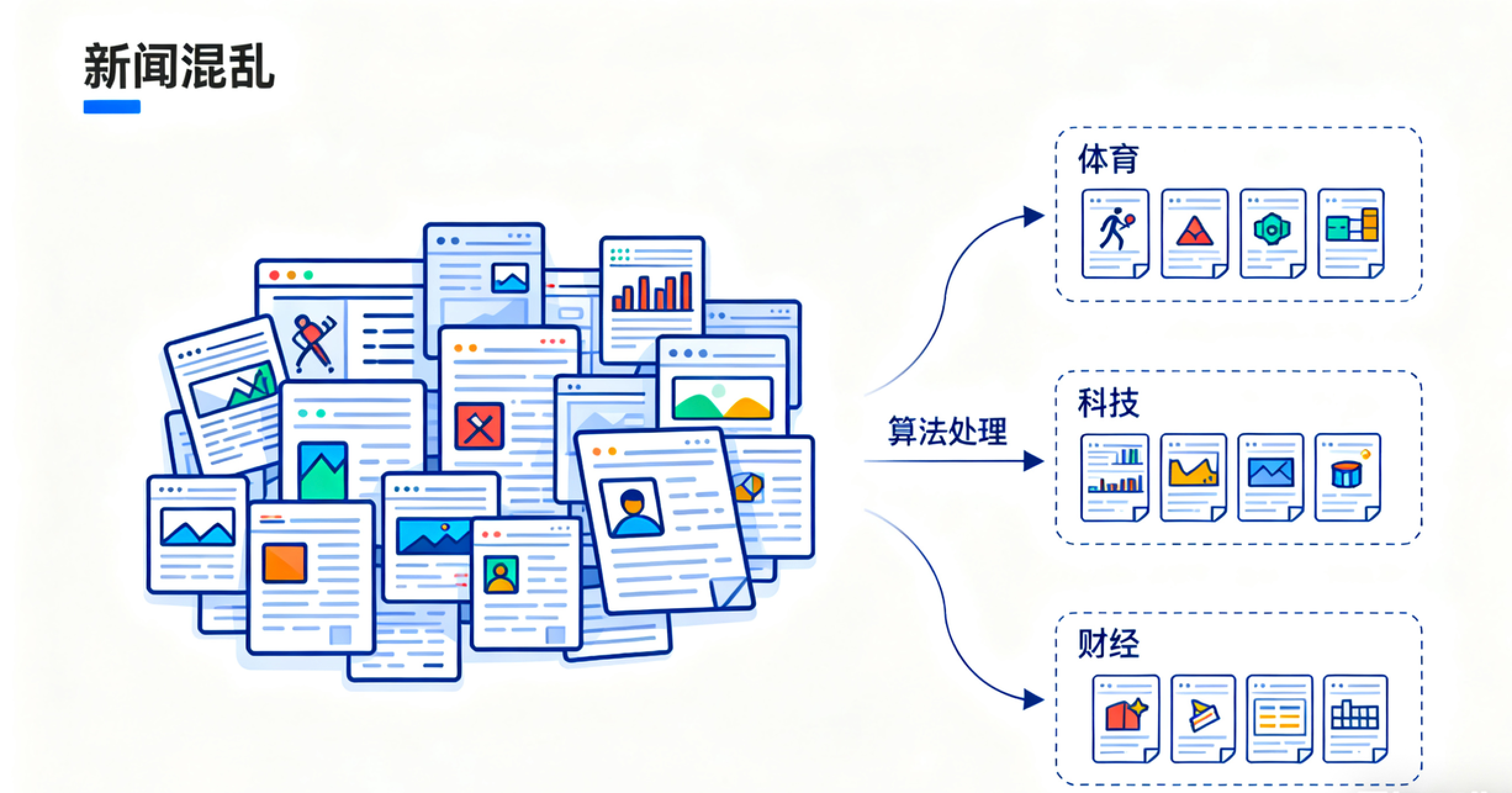
主要任务类型:
-
聚类(Clustering):将相似的数据分组 → 例如:用户分群、新闻分类
-
降维(Dimensionality Reduction):压缩数据,保留关键信息
-
关联规则(Association):发现数据之间的隐含关系(比如“啤酒与尿布”)
经典应用:
-
客户细分
-
异常检测
-
推荐系统
-
社交网络分析
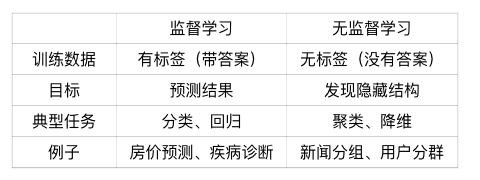
三、一张图看懂区别
四、实际应用:如何选择?
-
如果你有“标注好的数据”,并且目标是预测或分类,选择监督学习。
-
如果你没有标签,但希望探索数据内在结构,选择无监督学习。
在很多复杂场景中(如推荐系统),两者也常常结合使用。
五、总结
-
监督学习 = 老师教学生:有答案,学规律,做预测
-
无监督学习 = 自学探索:无答案,找模式,发现结构
两者都是机器学习的重要组成部分,没有优劣之分,只有适用场景不同。
理解这两个概念,是你进入机器学习世界的第一步。
欢迎关注本公众号,接下来我们将深入讲解线性回归、聚类算法等具体模型,带你继续探索机器学习之旅!
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/bGUwk1i1bnz1Qh-Asgux4g
https://mp.weixin.qq.com/s/bGUwk1i1bnz1Qh-Asgux4g


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









