




推荐阅读
AIGCmagic社区介绍:
2025年《AIGCmagic社区知识星球》五大AIGC方向全新升级!
AI多模态核心架构五部曲:
AI多模态模型架构之模态编码器:图像编码、音频编码、视频编码
AI多模态模型架构之输入投影器:LP、MLP和Cross-Attention
AI多模态模型架构之模态生成器:Modality Generator
————————————————
一、引言
大模型通常具有庞大的参数量和复杂的结构,这不仅导致训练和推理成本高昂,还对硬件资源提出了极高的要求。为了解决这些问题,研究人员提出了多种模型压缩和加速技术,其中量化、剪枝与蒸馏是三种常见且有效的方法。本文将详细介绍这三种技术的原理、实现方法,并配以流程图和代码示例进行说明。
二、量化技术
2.1 量化的基本原理
量化是将高精度的浮点数参数转换为低精度表示的过程。在深度学习模型中,通常使用32位浮点数(FP32)来表示模型的参数和中间计算结果。然而,32位浮点数需要较大的存储空间和计算资源,而量化技术可以将这些参数和计算结果转换为8位整数(INT8)甚至更低的位数,从而显著减少模型的存储空间和计算量。
量化的核心思想是将连续的浮点数取值范围映射到有限的离散整数集合上。常见的量化方法包括线性量化和非线性量化,其中线性量化是最常用的方法。线性量化的公式如下:
x
q
=
round
(
x
S
+
Z
)
x_q = \text{round}(\frac{x}{S} + Z)
xq=round(Sx+Z)
其中,
x
x
x 是原始的浮点数,
x
q
x_q
xq 是量化后的整数,
S
S
S 是缩放因子,
Z
Z
Z 是零点。反量化的公式为:
x
=
(
x
q
−
Z
)
×
S
x = (x_q - Z) \times S
x=(xq−Z)×S
2.2 量化的流程图
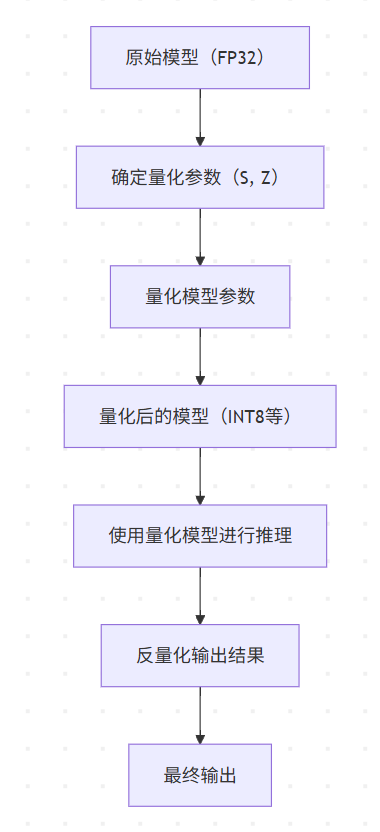
2.3 代码实现
以下是使用PyTorch实现简单的线性量化的示例代码:
import torch
import torch.nn as nn
# 定义一个简单的线性层
class SimpleLinear(nn.Module):
def __init__(self, in_features, out_features):
super(SimpleLinear, self).__init__()
self.linear = nn.Linear(in_features, out_features)
def forward(self, x):
return self.linear(x)
# 创建模型
model = SimpleLinear(10, 5)
# 模拟输入数据
input_data = torch.randn(1, 10)
# 量化参数
scale = 0.1
zero_point = 0
# 量化模型参数
quantized_weight = torch.round(model.linear.weight / scale + zero_point).to(torch.int8)
quantized_bias = torch.round(model.linear.bias / scale + zero_point).to(torch.int8)
# 量化输入数据
quantized_input = torch.round(input_data / scale + zero_point).to(torch.int8)
# 量化推理
quantized_output = torch.matmul(quantized_input, quantized_weight.t()) + quantized_bias
# 反量化输出结果
output = (quantized_output - zero_point) * scale
print("原始输出:", model(input_data))
print("量化后输出:", output)
2.4 量化的优缺点
- 优点:
- 减少模型存储空间:低精度表示可以显著减少模型的存储需求。
- 加速推理过程:低精度计算通常比高精度计算更快,尤其是在支持低精度计算的硬件上。
- 降低能耗:减少了计算和存储的需求,从而降低了能耗。
- 缺点:
- 精度损失:量化会引入一定的精度损失,可能会导致模型性能下降。
- 量化参数选择困难:合适的量化参数(如缩放因子和零点)需要通过复杂的算法进行确定。
三、剪枝技术
3.1 剪枝的基本原理
剪枝是通过移除模型中对输出影响较小的参数来减少模型复杂度的技术。在深度学习模型中,许多参数对模型的最终输出贡献很小,甚至可以忽略不计。剪枝技术的目标是识别并移除这些不重要的参数,从而在不显著降低模型性能的前提下,减少模型的参数量和计算量。
剪枝可以分为结构化剪枝和非结构化剪枝。结构化剪枝通常以滤波器、通道或层为单位进行剪枝,而非结构化剪枝则是对单个参数进行剪枝。常见的剪枝方法包括基于幅度的剪枝、基于梯度的剪枝等。
3.2 剪枝的流程图
3.3 代码实现
以下是使用PyTorch实现基于幅度的剪枝的示例代码:
import torch
import torch.nn as nn
import torch.nn.utils.prune as prune
# 定义一个简单的卷积神经网络
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.fc1 = nn.Linear(16 * 32 * 32, 10)
def forward(self, x):
x = self.conv1(x)
x = x.view(-1, 16 * 32 * 32)
x = self.fc1(x)
return x
# 创建模型
model = SimpleCNN()
# 对卷积层进行剪枝
parameters_to_prune = (
(model.conv1, 'weight'),
)
# 基于幅度的剪枝,剪枝比例为20%
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=0.2,
)
# 移除剪枝的参数
prune.remove(model.conv1, 'weight')
# 打印剪枝后的模型参数
print("剪枝后的卷积层权重形状:", model.conv1.weight.shape)
3.4 剪枝的优缺点
- 优点:
- 减少模型参数量:显著减少模型的参数量,降低存储和计算需求。
- 加速推理过程:减少了计算量,从而提高了推理速度。
- 提高模型可解释性:移除不重要的参数可以使模型更加简洁,易于理解。
- 缺点:
- 性能下降:剪枝可能会导致模型性能下降,尤其是在剪枝比例较大时。
- 微调成本高:剪枝后通常需要对模型进行微调,以恢复性能。
四、蒸馏技术
4.1 蒸馏的基本原理
蒸馏是一种模型压缩技术,通过将一个大型的、复杂的教师模型的知识转移到一个小型的、简单的学生模型中。教师模型通常具有较高的性能,但计算成本也较高;而学生模型则具有较低的计算成本,但性能可能不如教师模型。蒸馏的目标是让学生模型学习教师模型的输出分布,从而在保持较低计算成本的前提下,达到接近教师模型的性能。
蒸馏的核心思想是使用教师模型的输出作为软标签,与学生模型的输出进行比较,并通过损失函数来优化学生模型的参数。常见的蒸馏损失函数包括KL散度损失、均方误差损失等。
4.2 蒸馏的流程图
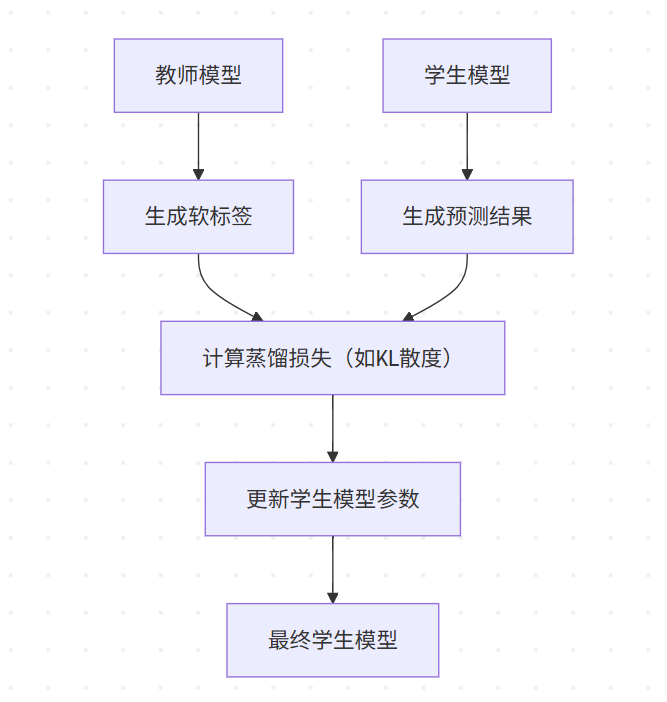
4.3 代码实现
以下是使用PyTorch实现简单的知识蒸馏的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义教师模型
class TeacherModel(nn.Module):
def __init__(self):
super(TeacherModel, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.fc2 = nn.Linear(20, 5)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 定义学生模型
class StudentModel(nn.Module):
def __init__(self):
super(StudentModel, self).__init__()
self.fc = nn.Linear(10, 5)
def forward(self, x):
return self.fc(x)
# 创建模型
teacher = TeacherModel()
student = StudentModel()
# 定义损失函数和优化器
criterion = nn.KLDivLoss(reduction='batchmean')
optimizer = optim.Adam(student.parameters(), lr=0.001)
# 模拟输入数据
input_data = torch.randn(16, 10)
# 训练学生模型
for epoch in range(100):
# 教师模型生成软标签
with torch.no_grad():
teacher_output = torch.softmax(teacher(input_data), dim=1)
# 学生模型生成预测结果
student_output = torch.log_softmax(student(input_data), dim=1)
# 计算蒸馏损失
loss = criterion(student_output, teacher_output)
# 更新学生模型参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f'Epoch {epoch + 1}, Loss: {loss.item()}')
4.4 蒸馏的优缺点
- 优点:
- 提高学生模型性能:通过学习教师模型的知识,学生模型可以达到接近教师模型的性能。
- 模型压缩:学生模型通常比教师模型小,从而减少了存储和计算需求。
- 泛化能力增强:蒸馏可以帮助学生模型学习到更具泛化能力的特征。
- 缺点:
- 教师模型依赖:蒸馏需要一个性能较好的教师模型,否则学生模型的性能也会受到影响。
- 训练时间增加:蒸馏过程通常需要额外的训练时间。
五、三种技术的比较与结合
5.1 三种技术的比较
| 技术 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 量化 | 将高精度浮点数转换为低精度表示 | 减少存储和计算需求,加速推理,降低能耗 | 精度损失,量化参数选择困难 | 对存储和计算资源要求较高的场景 |
| 剪枝 | 移除模型中不重要的参数 | 减少参数量和计算量,提高模型可解释性 | 性能下降,微调成本高 | 模型参数量过大的场景 |
| 蒸馏 | 将教师模型的知识转移到学生模型 | 提高学生模型性能,模型压缩,增强泛化能力 | 依赖教师模型,训练时间增加 | 需要在小模型上达到较高性能的场景 |
5.2 三种技术的结合
量化、剪枝与蒸馏技术并不是相互排斥的,它们可以相互结合,以达到更好的模型压缩和加速效果。例如,可以先对模型进行剪枝,移除不重要的参数,然后对剪枝后的模型进行量化,进一步减少存储和计算需求。最后,可以使用蒸馏技术将一个大型的教师模型的知识转移到量化剪枝后的学生模型中,提高学生模型的性能。
结合三种技术的流程图如下:
六、结论
量化、剪枝与蒸馏是大模型压缩和加速的三种重要技术。量化可以减少模型的存储和计算需求,剪枝可以移除模型中不重要的参数,蒸馏可以将教师模型的知识转移到学生模型中,提高学生模型的性能。三种技术各有优缺点,可以根据具体的应用场景选择合适的技术或结合使用。随着人工智能技术的不断发展,这些技术将在更多的领域得到应用,为解决大模型的存储和计算问题提供有效的解决方案。
交流社群
加入「AIGCmagic社区」星球/交流群,一起交流讨论:
AI视频、AI绘画、数字人、多模态、大模型、传统深度学习、自动驾驶等多个不同方向;
可私信或添加微信号:【lzz9527288】,备注不同方向邀请入群;
关注「AIGCmagic社区」星球/交流群,学习全栈式AIGC内容!



















 4232
4232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









